Data Contract を活用したデータ基盤
Data Platform チームの @kobori です。 先日 datatech-jp のイベントにて登壇の機会をいただき、その際に弊社のデータ基盤にどのように Data Contract を取り入れているかをお話ししてきました。
弊社では、プロダクトのデータを中央データ基盤に連携する際に Data Contract の考えを取り入れて連携の仕組みを構築しています。 私の入社以前からある仕組みで、2023 年ごろから取り入れられていたようです。
本記事では、弊社でどのように Data Contract 取り入れてデータ基盤を構築しているかご紹介いたします。
Data Contract とは
まずは簡単に Data Contract の説明をします。
Data Contract はその名の通り、データコンシューマーとデータプロデューサーの間で交わされる取り決めのことです。 例えばプロダクトのデータを DB から DWH に連携するような場合、プロダクトがデータプロデューサー、DWH がデータコンシューマーとなります。 GoCardless という企業で Principal Engineer として働く Andrew Jones という人が提唱した概念のようです。
Driving Data Quality with Data Contracts は Data Contract について解説されている書籍ですが、この本では Data Contract 下記の 4 原則が紹介されています。
- データプロデューサーとデータコンシューマーとの間で合意されたインターフェース
- データの期待値の設定
- データガバナンス方法の定義
- 高品質なデータ生成の促進
1. データプロデューサーとデータコンシューマーとの間で合意されたインターフェース
インターフェースを定めることで、プロデューサーが抱える実装の詳細が抽象化され、コンシューマーは実装の詳細を把握せずに、より理解しやすい形でデータを利用することが可能になり、プロデューサー側はシステムの実装の変更が容易になります。
2. データの期待値の設定
データの使い方、スキーマ、データの有効値、所有者、パフォーマンスなどの期待値を設定します。 パフォーマンスや信頼性の指標としては、完全性、適時性、可用性を使用することができます。 これらの SLI を測定しアラートを設計することで、データの品質の維持が可能になりそうです。
3. データガバナンス方法の定義
データのアクセス権、有効期限、前処理方法など、データの管理方法を定義するポリシーなどを定めます。 Data Contract にメタデータとして、これらの情報を記述しておくことで、Data Contract が SSoT として扱われることになり、データの利用者は必要な情報を全て Data Contract の参照により得られることになります。
4. 高品質なデータ生成の促進
Data Contract を定めることで、データがプロダクトの副産物ではなく、明示的に生成されたプロダクトとして扱われます (Data as a Product)。 Data Contract がプロデューサーとコンシューマーのコラボレーションを促す場として機能し、データ品質の向上が促進されていきます。
Belong における Data Contract
これら 4 原則からわかるように、 Data Contract を導入することで、データの信頼性や品質の向上が期待できます。 実際に弊社における Data Contract は下記のような構成になっております。 これは社内の在庫管理システムの Data Contract です。 現時点ではインターフェースを定めておりますが、SLI の設定やガバナンス方法の管理は今後の課題です。
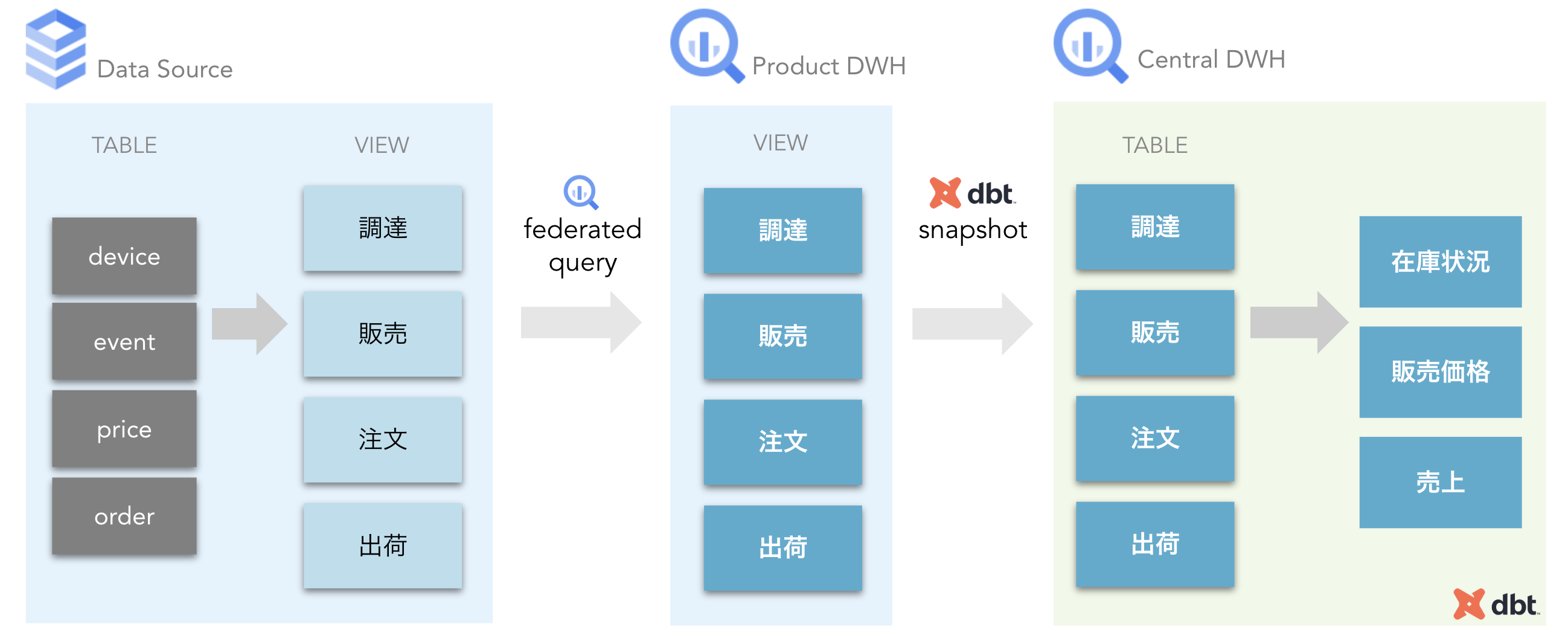
データプロデューサーの DB にあたる Cloud SQL 上に、DB の実装を抽象化する形で View を構築し、同じスキーマの View をプロダクトの DWH である BigQuery 上に構築しています。 その View を経由して中央 DWH 上にデータを蓄積しています。
弊社はリユーススマートデバイスを扱っているのですが、調達、販売、注文、出荷など、スマートデバイスのライフサイクルに合わせてインターフェースを構築することで、システム内の実装を抽象化しています。
Cloud SQL 上と BigQuery 上に同一の View を構築しているのは、BigQuery の SQL PushDown を利用するためです。 SQL PushDown が利用できることで、BigQuery 上で組み立てた SQL でも DB の Index を利用することができ、適切に Index が張られていればプロデューサーの DB への負荷を抑えることができます。 これらの View を通し、中央 DWH 上に dbt の snapshot を使って定期的に蓄積を行っています。
現在は中央 DWH 上にデータを蓄積していますが、 Product ごとに DWH を構築し、データオーナーを Product チームに任せ、Data Mesh 化を目指していく方がデータ基盤のスケールがしやすいのではないかと考えています。
構築のポイント
この構成のポイントを 3 つ以下にまとめます。
1. 堅牢なデータパイプライン
Data Contract によりプロダクトの DB の実装を隠蔽し、データコンシューマーが実装の詳細を把握する必要がなくなります。 また、スキーマをデータのユースケースからも独立に定義しています。 これにより DB の実装に変更が加わった場合もデータコンシューマーは影響を受けることが小さくなり、また、データのユースケースが増えた場合もインターフェースの改修が必要な可能性が小さくなります。 結果データパイプラインが堅牢となり、データプロデューサー、データコンシューマー双方の負担を減らすことができます。
2. SQL PushDown の利用
データソースの CloudSQL と BigQuery 上に同じスキーマの View を定義することで SQL PushDown の利用を可能としています。 SQL PushDown を利用できると、データソース側で適切な Index を張っておくことでデータソースの負担を小さくすることができます。
3. データパイプラインの管理コストの減少
データを蓄積する際に dbt の snapshot を利用しているのですが、snapshot では * を用いてカラムの選択をしておくことでデータソースのスキーマ変更の影響が小さくなります。
カラムが増えた場合には dbt がモデルにカラムを追加してくれるため改修コストがかかりませんし、カラムが減少した場合はすでに蓄積されているモデルのスキーマは変更を受けませんが、パイプラインが壊れることもありません。
これにより、Data Contract のスキーマが変わった場合も連携部分の改修コストがかからず、データチームにおける管理コストを小さく保つことができます。
さいごに
Data Contract を通してデータプロデューサーの実装とデータコンシューマーのユースケースが独立することで、データプロデューサー、データコンシューマー双方の負担を減らし、データ連携のスピード感をあげることに繋がります。
今後課題としていきたいのは、Data Contract に変更が加わった際の、変更の連携の自動化です。 弊社では dbt を使ってデータ DWH を構築しているのですが、Data Contract の定義変更を自動的に dbt の docs に反映し、データカタログのメンテナンスコストを減らし、より信頼性の高いデータを提供したいと考えています。
また、弊社では複数のプロダクトがあるのですが、 他のプロダクトにも Data Contract を活用したデータ連携の仕組みを構築し、データメッシュ化を進めることで社内データの活用の更なる加速も今後の課題の 1 つであります。
この記事を読んで弊社のデータチームに興味を持っていただけた方は Entrancebook をご覧ください。