Data Vault の変更耐性の仕組み
Data Platform チームの @kobori です。
久しぶりの記事になってしまいましたが、今回は Data Vault Modeling について書いてみたいと思います。 Data Vault について、なんとなく、柔軟性が高いことや、履歴保持に特化していること、複雑な手法であることは知っていましたが、その学習コストの高さとメリットへの理解不足からやや敬遠をしていました。
本記事では、簡単な Data Vault Modeling についての説明と、3NF や Star Schema などの構成と比較をし、なぜ Data Vault Modeling によって変化に強い DWH が構築できるかを解説してみたいと思います。
Data Vault とは
データ基盤構築の難しさとして、データに対する変化が発生する場所や影響範囲が分離していないことが挙げられます。 例えば SCD (Slowly Changing Dimension) は、属性の変化を同じテーブルの中で履歴として表現するアプローチであり、変化が起きる場所 (カラム) とその影響を受ける構造 (テーブル) が同じテーブルに含まれており、分離されていません。
Data Vault はこれを物理的に分離することで、データの変化に対する柔軟性を手に入れています。 先にも述べている通り、これにより履歴保持と Data 統合を可能としています。
ご存知の方も多いと思いますが、Data Vault は下記の 3 要素によって構成されます。
- Hub
- 基本的に変わらない Entity の存在を表現する
- Link
- 変化し得る Hub 間の関係を表現する
- Satellite
- 変化の激しい属性情報を表現する
これらがどのような役割を担うか、詳細は以下で説明しようと思うのですが、まずこれらの命名が Data Vault のわかりづらさの原因となっているようにも思えます。 OLTP 系のデータであれば master と transaction 、Dimensional Modeling であれば dimension と fact など、どういうデータが格納されるかという点がそのコンポーネント名に表現されている一方で、Data Vault では、Hub / Link / Satellite のように、Hub を中心に Link が広がり、更に、その Hub や Link の周りに衛星のように周遊する Satellite が配置されるというそのモデルの構成方法に基づいて命名されています。 名前からだけでは、どういうデータをそこに詰めればいいかが全く判断ができず、Data Vault 導入への障壁になっているように感じられます。ただおそらくこれも Data Vault のポイントの一つで、Data Vault は DWH を構成する部品を組み立てるためのモデリング手法であるため、それぞれに意味を持たせていないのかもしれません。
Hub
まず初めに Hub ですが、これは entity のビジネスキーを保持するオブジェクトです。 ここで言うビジネスキーとは、ソースシステム上でオブジェクトに対して与えられる ID やキーを指します。顧客 ID や注文 ID などです。 名前の通り、データモデルの中心であり、Hub を中心に Link が放射状に伸びる構造となります。
以下は customer という entity を表現する Hub になります。
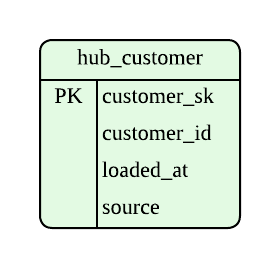
保持しているのは customer_id のみで、顧客名や email など、関連する情報は保持しません。
customer_id 以外のカラムは、モデリングの過程で付与されるものです。 customer_sk は DWH 上で付与されるサロゲートキーです。Hash Key と呼ばれるケースが多そうです。customer_id など、ソースシステム上の ID とは独立に key を定義するのですが、これは DWH とデータソースを独立にすることで、ソースシステムの変更による DWH への影響を抑え、堅牢な DWH を構成するためです。 それ以外の要素はメタデータで、Data Vault では、そのデータが load された日時やどのシステムをソースとしているかを属性として持たせます。
更新されないビジネスキーしか持たせないことで、Hub は基本的に不変の構造を持ちます。 この不変性が、Data Vault における変更耐性の一つとなります。
Link
次に Link ですが、これは名前の通り Hub 同士を結びつけるオブジェクトです。中間テーブルのように捉えてもいいかもしれません。 例えば、注文 Hub と顧客 Hub の関係を Link によって定義し、顧客ごとの注文情報を保持します。
以下がその例となりますが、Link も自身のサロゲートキーと参照する Hub のサロゲートキーのみを保持し、その他の付随する情報は持ちません。 Hub 同様メタデータも定義されます。
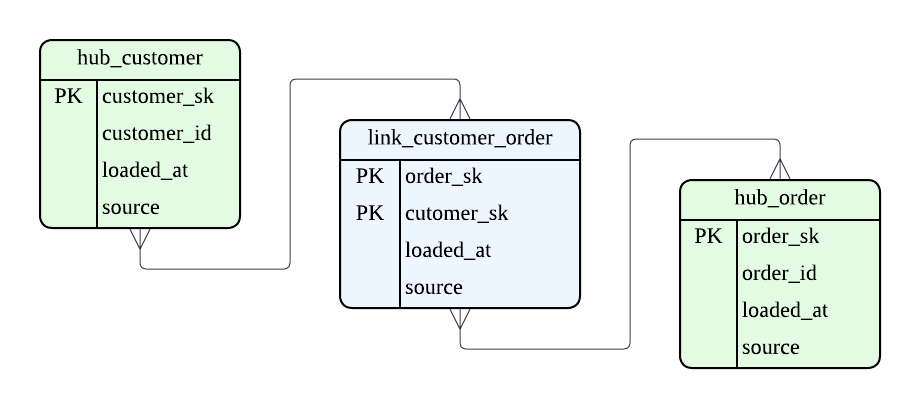
Hub 間の関係だけ定義し、関係性の変化を Link が吸収すること、これが 2 つ目の変更耐性の理由になります。 例えば、新しい Entity 間の関係が増えても、Link を 1 つ追加するだけで拡張ができます。
Link の粒度
Link はそこに含まれる Hub の数によってその粒度が決まります。 Link の粒度を決める時には、そのリンクで表現されるイベントが、それ以上分割できない単位になっているかという点が重要です。
例えば、弊社は中古端末を扱っているのですが、中古端末では入荷した端末は品質検査を行う必要があります。 この品質検査は、どの作業者がどの端末に対して何の検査を行ったかという 1 つの transaction を表すため、1 つの Link として表現します。
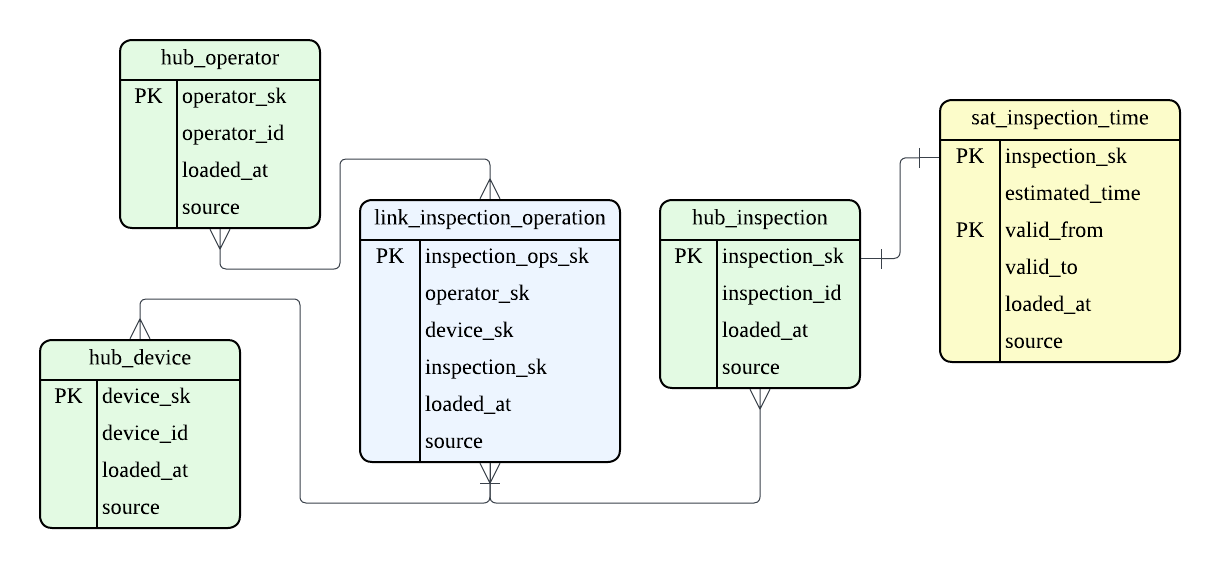
逆にこれらは分けることができません。
仮にこれらを link_inspection_operator と device_inspection に分けてモデリングをしてしまうと、品質検査をやり直した際に、誰が 1 回目の検査を行い、誰が 2 回目の検査を行ったかという事実が復元できなくなってしまいます。
このように Link の粒度が適切か、という点は、ソースで記録された事実を復元できるか、という観点で確認することができます。
もう 1 つ例を挙げたいと思います。 以下は誰がどの SKU に対する注文をしたかという情報を含む Link の例です。
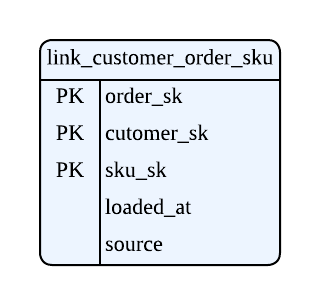
これも誤った Link のモデリングになるのですが、このモデリングからは顧客が注文をしたという事実の抽出が複雑になり、非効率になってしまいます。
この場合は、注文に関する情報 link_customer_order と注文明細 link_ordered_sku を別々にモデリングをすることで、効率的かつ柔軟なモデリングを実現できます。
Link をどの粒度で定義するか、という点は、Data Vault を実装する上でのポイントになってきます。
Satellite
最後に Satellite ですが、Satellite では Hub や Link のフィールドを定義します。 Hub や Link などを取り囲む形で、付随する属性情報や履歴情報を保持します。
以下は顧客という entity の例ですが、3NF であれば 1 つのテーブルに定義されているであろう属性が異なるテーブルに保存されています。
Satellite では、履歴データを保持するため、valid_to / valid_from のような有効期限や差分検知用の hashdiff のようなメタデータを持たせることもあります。
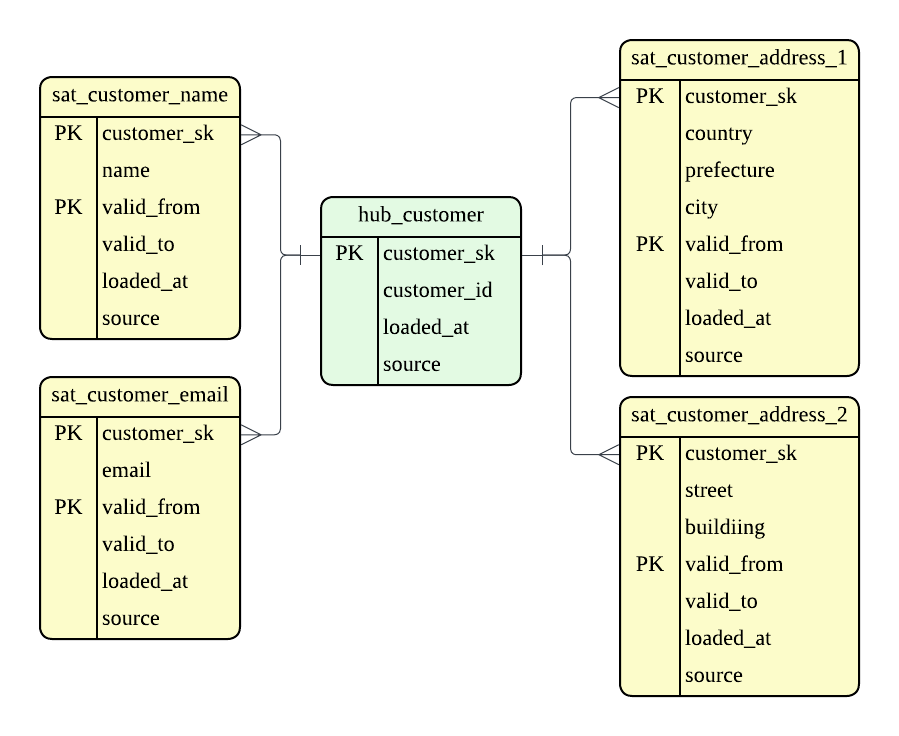
この例では、名前、メールアドレス、住所 1、住所 2 をバラバラのテーブルに分けていますが、データのライフサイクル (更新頻度や削除タイミング) によって分けています。 これは、Data Vault が追記によってのみ実現されるモデリング手法であるためです。 名前は基本的に変更はほとんどありませんが、メールアドレスは新しいメールサービスの利用やキャリアの変更によって変更されることがあります。住所も引越しごとに変更されます。 住所が 2 つに分かれているのは、PII か否かをイメージしています。市区町村など、PII に該当しない粒度の住所と、実際の詳細な住所を分けておくことで、PII の削除要請があった時も対応が容易です。 (基本的には PII に該当するレベルでの住所は分析では求められないと思うので、DWH に蓄積しておくことはないと思いますが。)
これらの分割を行わない場合、hashdiff の変更頻度が増え、履歴が爆発することになります。結果、いつ、何が変化したのかが追いづらくなってしまいます。
このように、ソースシステムにおける属性変化は全て Satellite が吸収します。 カラムの追加・更新頻度の変化・ソースの追加など、あらゆる変化を新たな Satellite の追加やレコードの追加によって対応できるため、Hub や Link の変更が不要となり、下流のモデルにも影響が出ることがありません。 これが 3 つめの変更耐性の理由となります。
Hub と Satellite
Link の例として、品質検査の例を挙げましたが、実際にはどんな検査が行われたかという事実は Hub として独立させず、Satellite として定義する方法もあると思います。
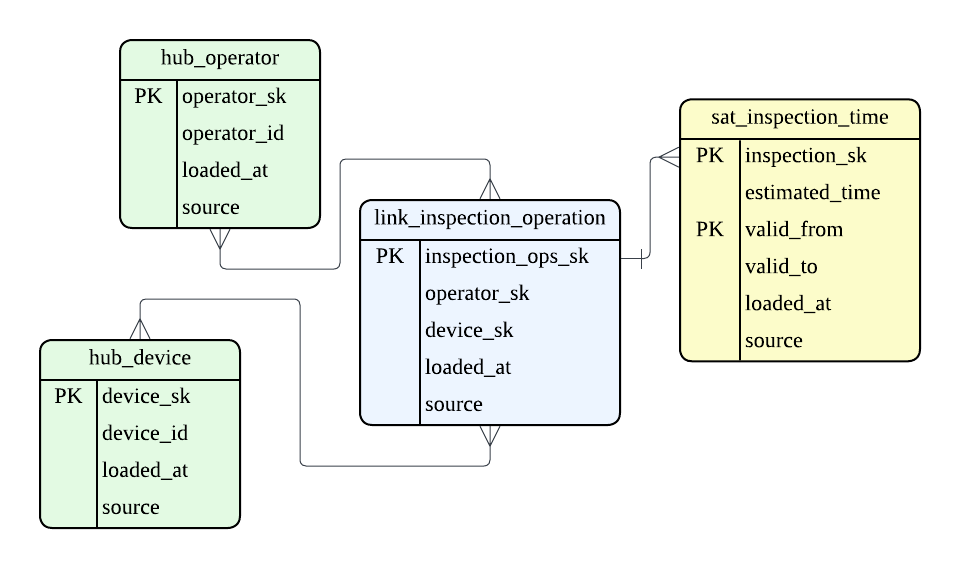
これは、検査 Hub が、想定所要時間のような分析に必要な属性を持っていて Hub にする必要があるか、ただ何の検査をしたかという事実しか必要ないのか、という観点で決まってくるのかと思います。
何を Hub として抽出し、何を Satellite に丸めるかという点も、Data Vault のポイントになりそうです。
スキーマ構成の比較
ここまで見るとわかるように、Data Vault ではかなり細かいモデリングを行うことになります。
先ほどの注文のコンテキストにおいて、3NF、Star Schema、Data Vault を比較してみたいと思います。
3NF
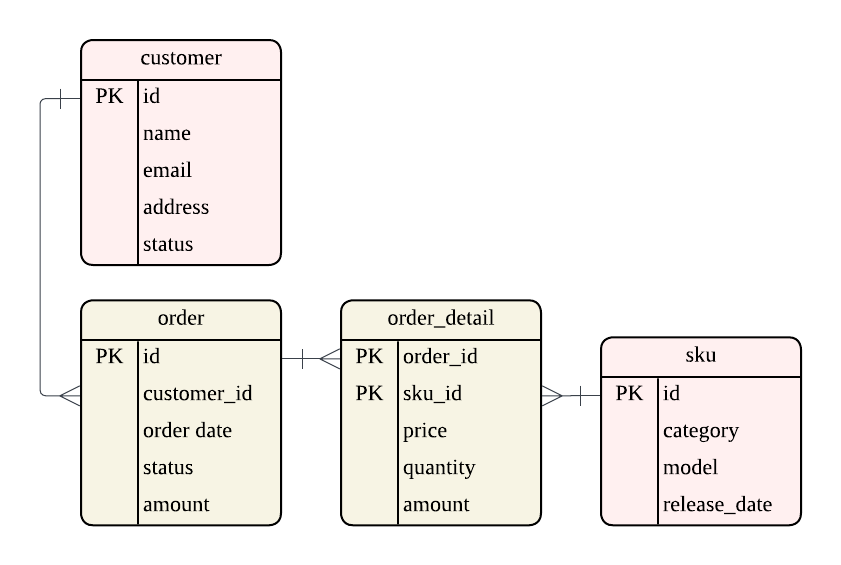
エンジニアであれば、比較的慣れ親しんだモデリングです。 整合性と更新効率を重視し、正規化によってモデリングを行います。
多くの場合、状態の変化をレコードの更新によって表現するため、Data Vault のように履歴保持が前提になっておりません。
Star Schema

Star Schema は分析効率を重視してモデリングを行います。 3NF とは反対に、非正規化によって分析時の JOIN を最小化し、Scan 効率を最大化します。 比較的粗いモデリングと言えるかと思います。
Entity 間の関係性の変化や、新しい属性の追加による影響範囲が広く、モデルの再構築が必要になる場合もあります。
Data Vault
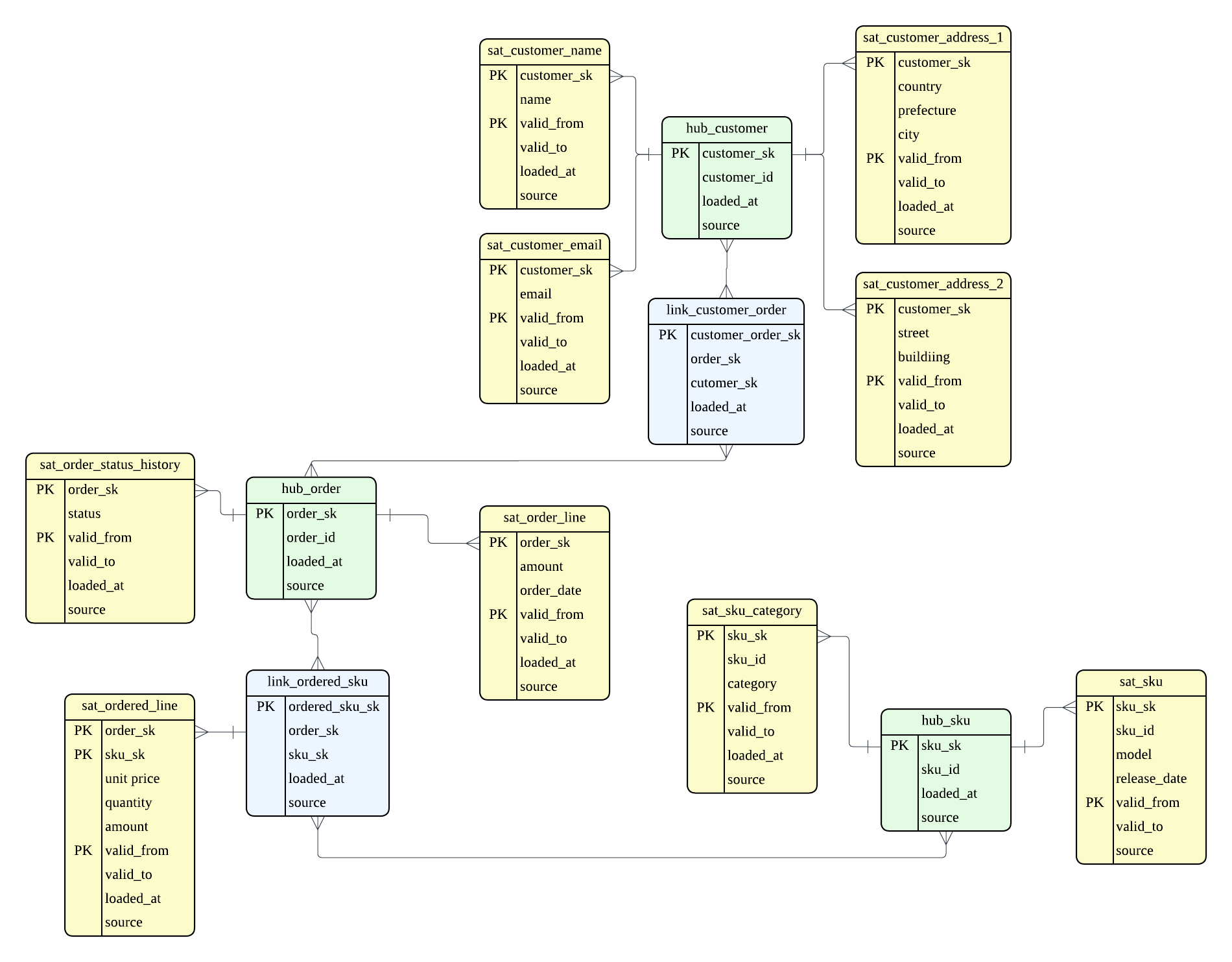
最後に Data Vault になりますが、他の 2 種類と比べると、かなり細かいモデリングになります。 クエリ効率を度外視し、冗長に見えますが、この細かさによってデータソースのあらゆる変化を受け止める柔軟性を得ることができます。
Data Vault を取り入れたデータ基盤
Data Vault は、DWH におけるデータモデリングの手法ですが、すでに述べたとおり、データソースの変化を受け止めるためのモデリング手法であり、データの分析に特化したモデリング手法ではありません。つまり、Dimensional Modeling のような分析用のモデリング手法と併せて用いることになります。
Data Vault 2.0 の書籍を参考に、レイヤ構成を考えてみました。
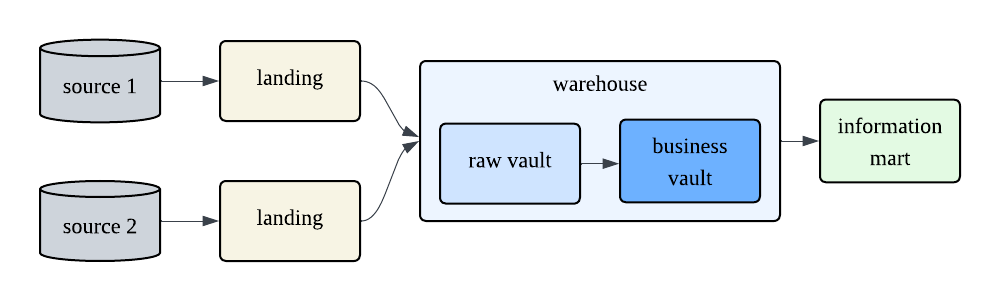
Landing Layer
この Layer は PSA (Persistent Staging Area) とも呼ぶようです。
書籍中では、この層は Truncate and Load を前提とする記載がありました (TSA, Transient Staging Area)。しかし、ここまで見るとわかるように、Data Vault はかなり複雑なモデリング手法です。Data Vault 自体は履歴保存のためのモデリングであると言えど、完璧なモデリングを完成させることは現実的ではありません。PSA としてデータを永続させ、再構築性を持たせておく方が安全のように思えます。
実際に、こちらの Scalefree 社の記事1では
the modern recommendation leans towards PSA, particularly with NoSQL or data lake implementations.
との記載があり、現代では PSA が推奨されているようです。
Raw Vault / Business Vault
ここから Data Vault が適用されます。 Raw Vault では、DWH 上のサロゲートキーを付与し、ロード日時、ソース情報、有効期間などのメタデータを付与します。 ビジネスルールの適用など、クレンジングは一切行わず、データ型の統一のような最小限の処理にとどめます。 Raw Vault に生データの形式で全ての変更履歴を蓄積することで、監査性を担保します。
続く Business Vault では Raw Vault のモデルに対してビジネスルールを適用します。 クレンジング、フォーマットの統一、合計金額の計算、追加属性の付与などです。
これらの層は、どちらもテーブルとして永続化します。 永続化することで、Raw Vault では監査性を担保し、Business Vault ではビジネスルールの変更自体を履歴として保持します。
Information Mart
書籍中では、このレイヤで Business Vault をソースとして Dimensional Modeling を適用します。 Data Vault を用いる場合、このレイヤは必ずしもテーブルとしての永続化をする必要はなさそうです。 Data Vault のレイヤでデータが永続化されているため、その再現性は担保されています。
View として定義する方が、スキーマ変更などには柔軟に対応できますが、クエリが複雑になる場合は永続化してパフォーマンスを確保する必要があります。
まとめ
確かに、Data Vault はやや複雑に思えるモデリング手法ですが、その複雑さ故にソースの変化に対して堅牢なデータモデリングを実現しています。
それを実現しているのが、
- Hub
- Link
- Satellite
の 3 要素で、これらがデータに対して起こる変化の場所を独立に保存します。 Hub の不変性が Data Vault の柱を作り、Link はあらゆる関係性の変化を吸収し、Satellite が属性の変化を吸収する、この構造により Data Vault は、既存の構造を崩さず、新しい部品の追加だけで変化に対する柔軟性を実現しています。
確かに複雑な手法には見えますが、堅牢なモデリング手法であり、取り入れる価値は十分ありそうに思えました。
本記事を読んで弊社 Data Platform チームに興味を持っていただけた方は、Entrance Book をご覧ください。
Footnotes
-
Scalefree 社: Data Vault 2.0 を唱えた Dan Linstedt を共同設立者とする企業 ↩