[MySQL] Tips: MySQL でのテストデータの作り方まとめ
はじめに
こんにちワルプルギス! 株式会社 Belong でプロジェクトマネージャーをしている七色メガネです。
皆さんは DB に触っている時、「ランダムな文字列ってどうやって作るんだっけなー」とか、「大量のテストデータってどうやって作るんだっけかなー」と思ったことはありませんか?私はあります。
こういう日常的に使わない知識って、一度入れてもすぐ忘れちゃうんですよね。そして毎回バラバラの紹介ページを都度調べてしまう。
そんなあなた (そして私) のために、テストデータ作成関連の知識をまとめました。よければ折に触れてご参照ください。
Agenda
- 値を生成する 1 ( 数字 )
- 値を生成する 2 ( 文字列 )
- 値を生成する 3 ( 日付 )
- ランダムに生成した値を使ってテストデータを 1 つ挿入する
- 複数データを一括で Insert する ( Insert into )
- 大量のテストデータを挿入する 1 ( 直積を繰り返す )
- 大量のテストデータを挿入する 2 ( sys テーブルで直積を求める )
- 大量のテストデータを挿入する 3 ( ストアドプロシージャを使う )
- 大量のテストデータを挿入する 4 ( テーブルをハックする )
- 大量のテストデータを挿入する 5 ( csv を使う ) 補足. LOAD DATA INFILE で発生するエラーへの対応
値を生成する 1 ( 数字 )
0 ~ 1 までの浮動小数点値を取得する
select rand();
rand() は 0.0 <= v <= 1.0 の範囲で浮動小数点値 v を返します。
0 ~ X までのランダムな浮動小数点値を取得する
select rand() * 10;
rand() の結果に 10 を乗算したら、値域は 0.0 <= v <= 10.0 に変化しますね。
0 ~ X までのランダムな整数を取得する
select floor(rand() * 10);
select ceil(rand() * 10);
floor() は引数以下で最大の整数値を返します。rand()*10 の値域は 0.0 <= v <= 10.0 なので、floor() を併用すると 0 ~ 10 の値が取れますね。
ceil() は引数以上で最小の整数値を返します。
ランダム値の生成に際しては、floor() と ceil() のどちらを使ってもいいですね。
X 以上、Y 以下までの整数を取得する
-- 3 ~ 7 までの値が取れる
SELECT FLOOR(3 + (RAND() * 4));
rand()*4 の値域は 0.0 <= v <= 4.0 です。それに 3.0 を加算すると値域は 3.0 <= v <= 7.0 となりますね。
rand() 単体では下限が 0.0 でしたが、指定数値を rand() の結果に加算することで下限の表現にしているんですね。
連番を取得する
set @i = 0;
select (@i := @i + 1);
値を生成する 2 ( 文字列 )
1 <= X <= 32 文字の文字列を取得する
select SUBSTRING(MD5(RAND()), 1, 4);
substring() は文字列のトリミングを行う関数です。第二引数の位置の始まりは 0 ではなく 1 です。
- 第一引数 ... 対象文字列自体
- 第二引数 ... 切り出しを開始する位置
- 第三引数 ... 切り出しを終了する位置
md5() は文字列のチェックサムを計算し、32 桁の 16 進数の文字列として返却する関数です。
これらを組み合わせて、「チェックサム文字列の先頭から X だけの文字を切り出す」ということを実現しているんですね。
ちなみに md5() の結果に依存しているので、32 文字までしかランダム生成できません。
1 <= X <= 40 文字の文字列を取得する
select SUBSTRING(sha(RAND()), 1, 35);
sha() は md5() と同じチェックサム計算のための関数です。
md5() が 32 桁の文字列を返却していたのに対して sha() は 40 桁を返すので、33 ~ 40 桁の文字列生成にをしたいならこっちが使えるかもですね。
文字列の suffix として連番を付与する
set @ i = 0;
select concat("test_", (@i := @i + 1));
数値編で見た「連番を取得する」の応用編ですね。concat() は文字列の連結を行う関数です。
指定したリストの中の文字列をランダムに取得する
select elt(FLOOR(1 + (RAND() * 4)),"Test1", "Test2", "Test3", "Test4");
elt() は文字列リストの X 番目の値を取得する関数です。リスト先頭を取得するときは 0 ではなく 1 を指定します。
floor(1 + rand() * ${リストの長さ}) によって値域 1 <= v <= ${リストの長さ} の範囲でランダムに数値が生成されます。
従って結果的に規定した文字列リストからランダムに値を取り出すことができます。
値を生成する 3 ( 日付 )
指定日から X 日以内のランダムな日付を取得する
SELECT DATE_ADD('2023-02-01', INTERVAL CEIL(RAND() * 10) DAY);
date_add() は日付の加算を行う関数です。
- 第一引数 ... 加算対象の日付
- 第二引数 ... 加算する日付値
interval 句の指定は必須です。加算する日付値の単位には Day や Month, Year などを指定できます。
ここでは cell(rand()*10) の計算で 0 <= v <= 10 の値域を求めているので、指定日から 0 ~ 10 日の値が加算された結果をランダム生成できますね。
指定日から X 月以内のランダムな日付を取得する
SELECT DATE_ADD('2023-02-01', INTERVAL CEIL(RAND() * 8) month);
指定日から X 年以内のランダムな日付を取得する
SELECT DATE_ADD('2023-02-01', INTERVAL CEIL(RAND() * 5) year);
指定日からの X 日以上 Y 日以下のランダムな日
SELECT DATE_ADD('2023-02-01', INTERVAL FLOOR(5 + (RAND() * 5)) DAY);
数値編で見た「X 以上、Y 以下までの整数を取得する」の応用ですね。
4. ランダムに生成した値を使ってテストデータを 1 つ挿入する
サンプルテーブルです。
CREATE TABLE megane1 (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(10),
type VARCHAR(10),
description VARCHAR(255),
sales_price DECIMAL,
registered_date DATE,
created_at DATETIME
);
ここまで学んだいくつかの方法を使用してランダムデータを挿入します。
set @id = 0;
insert into megane1 (id, name, type, description, sales_price, registered_date, created_at) values
(
-- 1 から自動インクリメントしていく数字。
(@id := @id + 1),
-- 3 文字のランダム文字列と固定文字列の結合
concat( SUBSTRING(MD5(RAND()), 1, 3), "メガネ"),
-- 規定された 4 種類の文字列からランダムな文字列を取得する
(elt(FLOOR(1 + (RAND() * 4)),"Round", "Fox", "Rimless", "Wellington")),
concat("とても", SUBSTRING(MD5(RAND()), 1, 12)),
-- 30,000 以下のランダムな数値を取得する
CEIL(RAND() * 30000),
-- 現在日時に 0 ~ 5 日を加算し、その上で YYYY-MM-DD 値に整形する
date(DATE_ADD(now(), INTERVAL FLOOR(5 + (RAND() * 5)) DAY)),
-- 現在日時を取得する
now()
);
'1','f3d メガネ','Rimless','とても 194d4ea14910','5430','2023-03-02','2023-02-25 10:19:19'
Insert 句で値を挿入するときは次のいずれかの方法をとることができます。
(a) 列情報を指定する
上記の例のパターンですね。指定した列名リストの数と、挿入する行に含まれる列の数は一致していなければいけません。
insert into ${テーブル名} ${列名リスト} values ${挿入する行情報}
(b) 列情報を指定しない
列名の指定はカットすることができます。
insert into ${テーブル名} values ${挿入する行情報}
この場合、挿入する行は、「完全に値を指定しない」か「テーブルにおける列数と一致する列情報を指定する」必要があります。
(b-1) 成立する: 完全に値を指定しない
insert into megane1 values ();
このテーブルにおける必須行は ID ですが、Autoincrement 制約がかかっているため指定しなければ自動でインクリメントされた値が挿入されますので問題ありません。 このほかに not null 制約がかかっている列などがあれば、この方法は使えません。
(b-2) 成立する: テーブルにおける列数と一致する列情報を指定する
insert into megane1 values (999, "メガネ", "test", "desc", "10000", "2023-01-01", now());
(b-3) 成立しない: 挿入行で列情報を指定しているのにテーブルの列数と一致しない
insert into megane1 values (10);
テーブルにおける列数と一致しない列数を挿入行の中で指定しても、無効になります。
(c) Select 句を併用する
select の結果を使用して insert を行うことができます。
今まで違うのは、values 句がないことです。values 句があるとこの方法が成立しない ので注意しましょう。
insert into megane1 (select ... from ...)
5. 複数データを一括で Insert する ( Insert into )
Insert into では複数行を一度に挿入することもできます。
insert into megane1 values
(10000, "メガネ", "test", "desc", "10000", "2023-01-01", now()),
(10001, "メガネ", "test", "desc", "10000", "2023-01-01", now()),
(10002, "メガネ", "test", "desc", "10000", "2023-01-01", now());
'10000','メガネ','test','desc','10000','2023-01-01','2023-02-25 10:51:28'
'10001','メガネ','test','desc','10000','2023-01-01','2023-02-25 10:51:28'
'10002','メガネ','test','desc','10000','2023-01-01','2023-02-25 10:51:28'
6. 大量のテストデータを挿入する 1 ( 直積を繰り返す )
今までの方では、Select を使って既存レコードを参照しない限り、挿入行を 1 つずつ自分で定義する必要がありました。 しかしこれでは大量のテストデータを作るのにはとても使えません。
この場合、直積を利用してテストデータを作成します。
直積のイメージ
先に直積のイメージを確認しておきましょう。 次のような 2 種類のデータセットがあるとします。
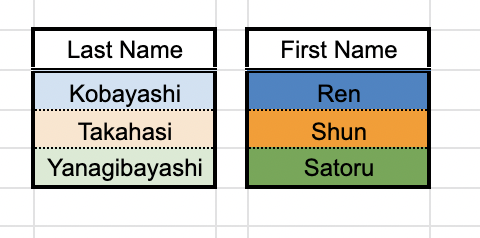
この 2 種類のデータセットから全てのデータを取り出し、可能な全ての組み合わせのパターンで結合させるのが直積です。
直積結合した後のイメージは次の通りです。
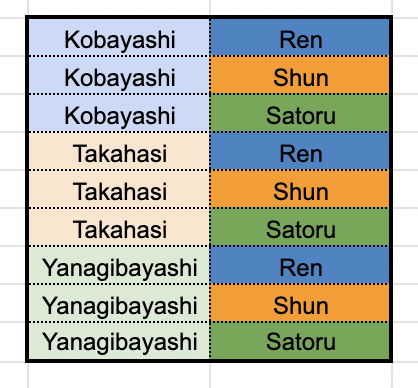
つまりそれぞれでのデータセットの数がそれぞれ X, Y だとしたら、直積計算して生まれるデータの組み合わせ数は X * Y になります。
SQL と直積
SQL では次のような方法で直積を表現することができます。from 句で 2 つ以上のテーブルを指定し、かつその関係性を指定しません。
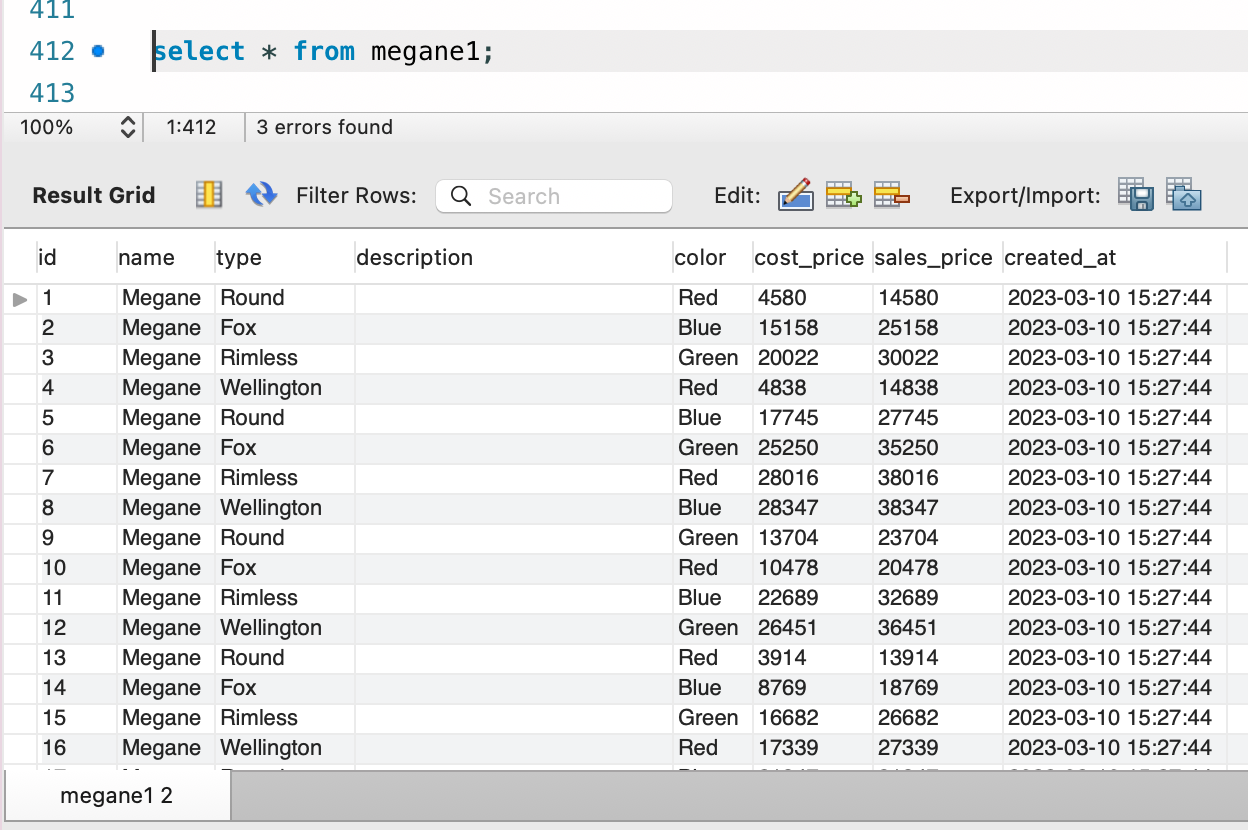
select * from megane1 as m1, megane1 as m2;
ポイントは、直積計算を行っても必ずしもその結果を select する必要はないということです。
現在 megane テーブルには 3 件のレコードがあります。
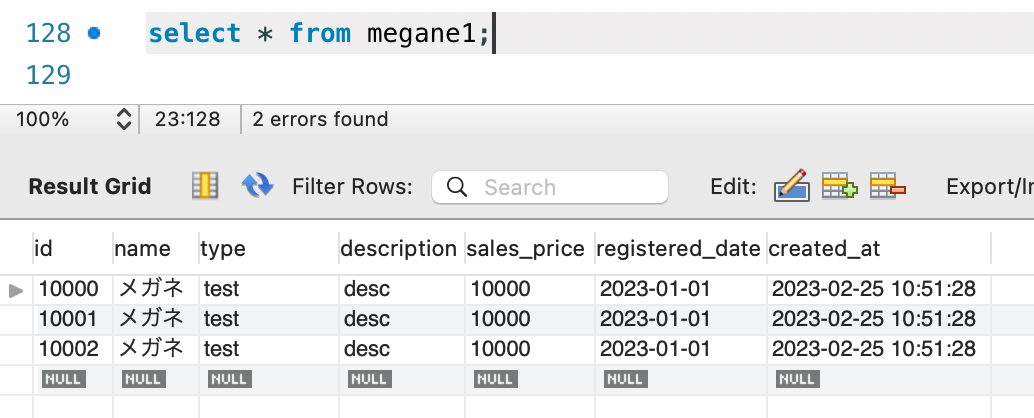
この megane テーブルを自己参照して直積を 1 度行うと、3*3 で 9 個のレコードが参照されることになります。
その後、テーブルの値を参照しない例が以下です。
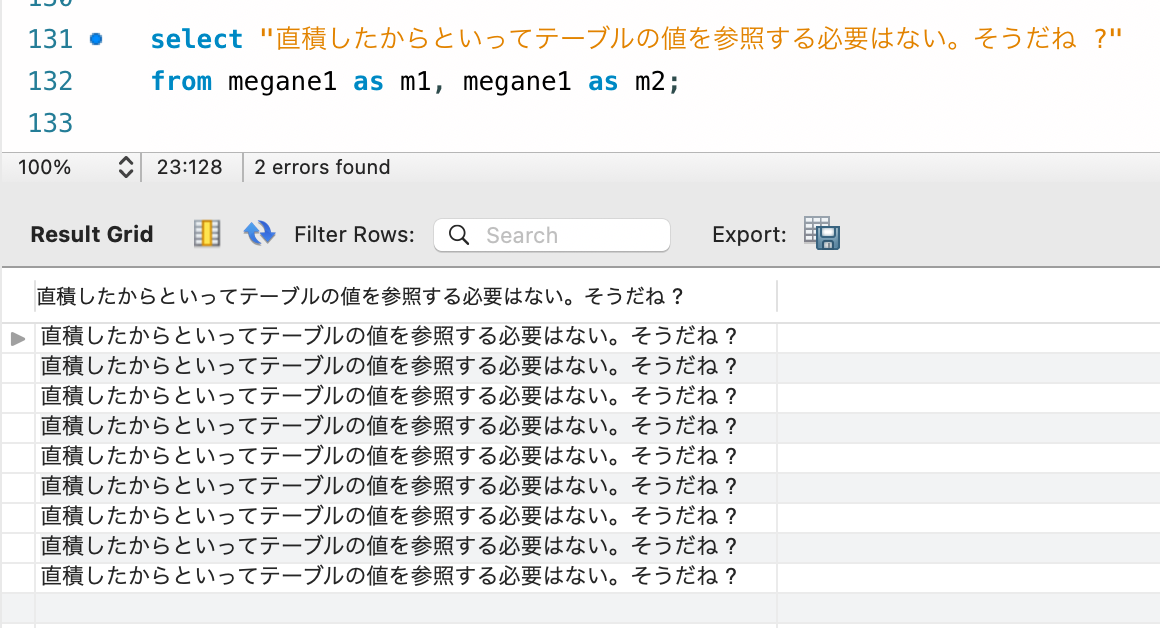
つまり直積を行って作りたいテストデータ分のレコード数を稼いだあとは、あとは自分が作りたいパターンで Select を組んで Insert を行うだけで、任意の数のテストデータが大量に作れるわけです。
大量のデータ挿入
前置きが長くなりましたが本題、大量のデータ挿入についてです。この方法では直積を行うための基盤データが必要になるので、まず 10 個のデータを用意します。
面倒なのでほぼ値のないレコードを作ります。
insert into megane1 values
(),(),(),(),(),(),(),(),(),();
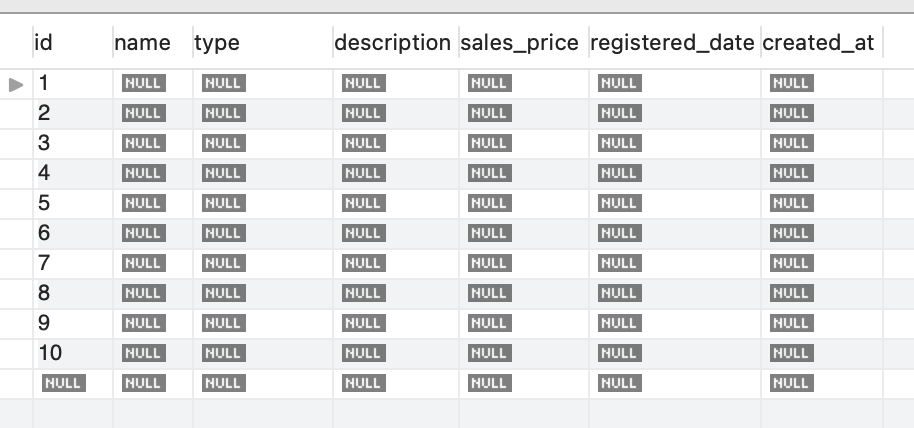
10 個のデータをもったテーブルができたので、これで直積を行います。直積は多重に行えるので今回は 3 回繰り返します。 これで 10 _ 10 _ 10 で 1,000 個分のレコード数が稼げます。それを使って、ランダムデータを生成します。
insert into megane1
(
select
(@id := @id + 1),
concat( SUBSTRING(MD5(RAND()), 1, 3), "メガネ"),
(elt(FLOOR(1 + (RAND() * 4)),"Round", "Fox", "Rimless", "Wellington")),
concat("とても", SUBSTRING(MD5(RAND()), 1, 12)),
CEIL(RAND() * 30000),
date(DATE_ADD(now(), INTERVAL FLOOR(5 + (RAND() * 5)) DAY)),
now()
from megane1 as m1, megane1 as m2, megane1 as m3
);
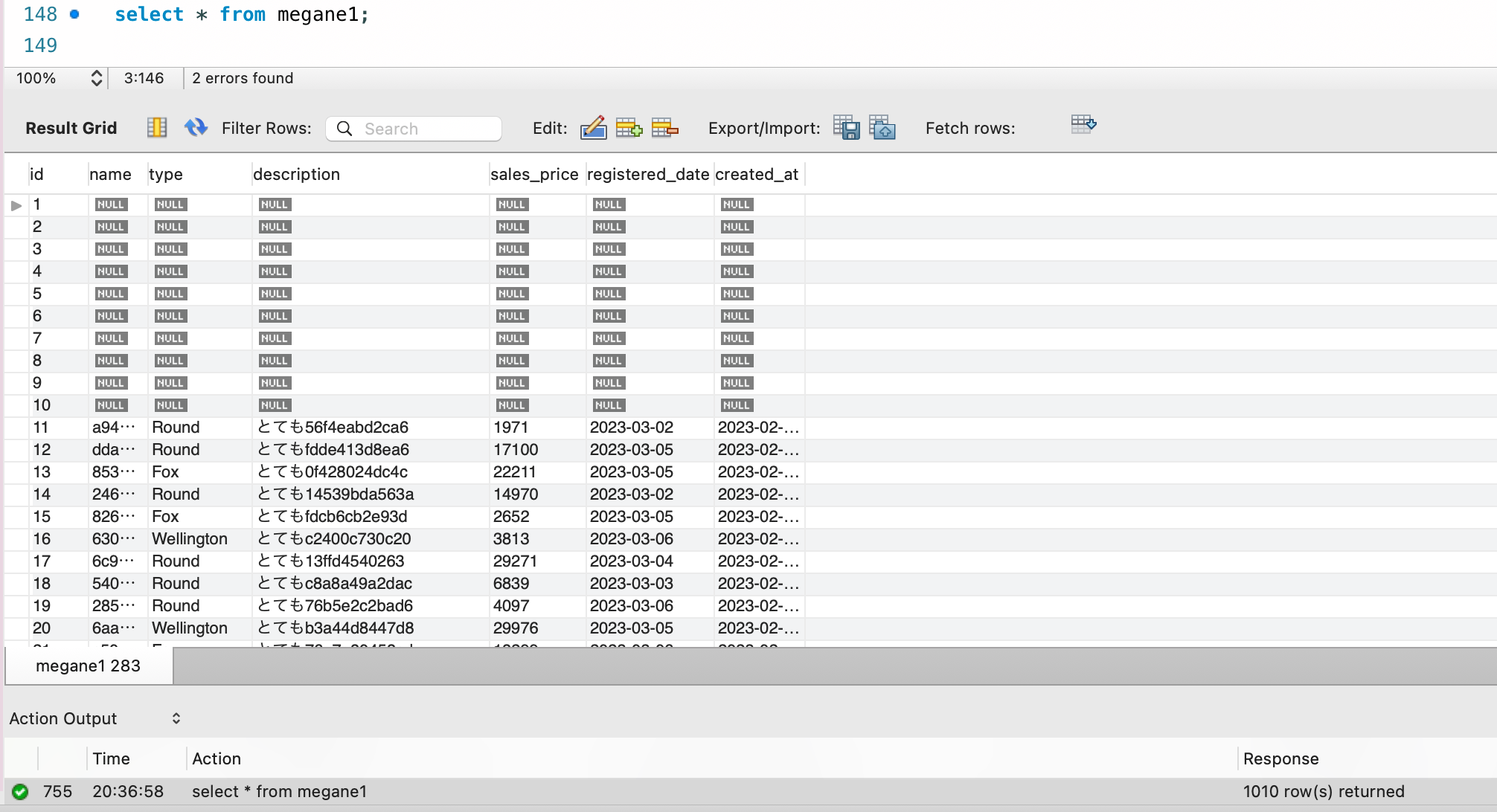
最初の 10 個分のデータは綺麗ではないですが、1010 個のランダムデータを生成することができました。
直積計算の回数を増やせば増やすほど、テストデータを増やすことができます。
7. 大量のテストデータを挿入する 2 ( sys テーブルで直積を求める )
先程の方法は便利なのですが、直積計算を行うための基盤データを自分で作らなければいけないという面倒さがありました。
ここに面倒さを感じる場合、sys 系のテーブルを参照するという方法を取ることができます。
例えば sys.schema_table_statistics が使えます。これはテーブルの統計がまとめられているビューですが、私の環境では実行時点で 77 のレコード数が存在しています。(実行タイミングで変わります)
select count(1) from sys.schema_table_statistics;
77
こういった最初からある程度のレコード数が入っている sys 系のテーブルを直積計算に使用すると、基盤データを作成する手間を skip して大量データを作成することができます。
insert into megane1 (name, type, description, sales_price, registered_date, created_at)
select
concat( SUBSTRING(MD5(RAND()), 1, 3), "メガネ"),
(elt(FLOOR(1 + (RAND() * 4)),"Round", "Fox", "Rimless", "Wellington")),
concat("とても", SUBSTRING(MD5(RAND()), 1, 12)),
CEIL(RAND() * 30000),
date(DATE_ADD(now(), INTERVAL FLOOR(5 + (RAND() * 5)) DAY)),
now()
from
sys.schema_table_statistics s1,
sys.schema_table_statistics s2,
sys.schema_table_statistics s3;
77 ^ 3 の計算を行ったので、456,000 系ほどのデータが作成できました。
select count(1) from megane1;
456533
ちなみに Select を使用した Insert 文では With 句を使うことができます。直積計算が長くなったりあるいは場合によって変わったりする場合、個人的には with 句を使った方が見やすくなるかなと思っています。
with 句を併用する場合、with は insert の後、select の前に置かれなければいけません。
insert into megane1 (name, type, description, sales_price, registered_date, created_at)
with tmp as
(
select ""
from sys.schema_table_statistics s1
)
select
concat( SUBSTRING(MD5(RAND()), 1, 3), "メガネ"),
(elt(FLOOR(1 + (RAND() * 4)),"Round", "Fox", "Rimless", "Wellington")),
concat("とても", SUBSTRING(MD5(RAND()), 1, 12)),
CEIL(RAND() * 30000),
date(DATE_ADD(now(), INTERVAL FLOOR(5 + (RAND() * 5)) DAY)),
now()
from tmp;
8. 大量のテストデータを挿入する 3 ( テーブルをハックする )
次はちょっと邪道な方法です。テーブル列の Default 列を使用します。
テーブルの各列には Default 値を設定することができます。 これはテーブルにレコードが挿入される時に、列値が設定されていない場合に指定値が初期値として用いられるようにする設定です。
ただこの Default、通常の値だけではなく式も設定することができるんですね。 つまり、今まで Insert 側で指定していたランダム値生成の設定をテーブル側に持たせることができます。
CREATE TABLE megane10 (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(10) DEFAULT "Megane",
type VARCHAR(10) DEFAULT (elt(FLOOR(1 + (RAND() * 4)),"Round", "Fox", "Rimless", "Wellington")),
description VARCHAR(255) DEFAULT NULL,
color ENUM("Red", "Blue", "Green") DEFAULT (CEIL(RAND() * 3)),
cost_price DECIMAL DEFAULT (CEIL(RAND() * 10000)),
sales_price DECIMAL DEFAULT (cost_price + 10000),
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
さっきまでのサンプルデータからはちょっと形を変えて、いくつか手法を追加しています。
- Enum が規定された color 列
- MySQL における Enum 型は、その列値が取り得る値を予め規定する文字列リストです。インデックスでアクセスすることができます。
- ここではデータ生成されるたび 0-3 の値域でランダムに数字を作って使用しているので、color に文字列リスト中のどれかが当て込まれることになります。
- 他の列を参照して計算式を作成している sales_price
- default 設定では式を設定することができ、式の中では条件を満たすテーブル内の他の列を参照できます。
この設定が行われた状態でデータの挿入を行ってみると、特に値の指定もしていないのにランダムなテストデータが作成されるのがわかります。
insert into megane10 values (),(),(),(),();
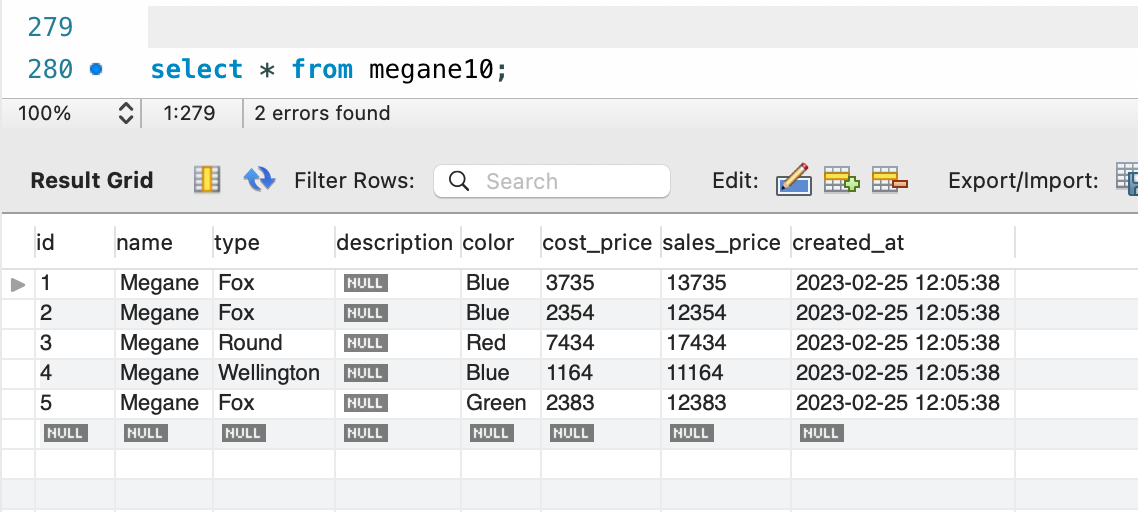
テーブルに default 設定がないよというときは、テストデータを作成する時にだけ default 設定を付け加えるという選択肢もあるかと思います。
-- default 設定のない普通のテーブル
CREATE TABLE megane11 (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(10) NULL,
type VARCHAR(10) NULL,
description VARCHAR(255) NULL,
color ENUM("Red", "Blue", "Green") NULL,
cost_price DECIMAL NULL,
sales_price DECIMAL NULL,
created_at DATETIME NULL
);
-- (1/5)テストデータ挿入
insert into megane11 values (),(),();
-- (2/5)alter で default 設定を追加してやる
alter table megane11
alter name set default "Megane",
alter type set default (elt(FLOOR(1 + (RAND() * 4)),"Round", "Fox", "Rimless", "Wellington")),
alter color set default (CEIL(RAND() * 3)),
alter cost_price set default (CEIL(RAND() * 10000)),
alter sales_price set default (cost_price + 10000),
alter created_at set default (CURRENT_TIMESTAMP);
-- (3/5)テストデータ挿入
insert into megane11 values (),(),();
-- (4/5)default 設定を消す
select * from megane11;
alter table megane11
alter name set default null,
alter type set default null,
alter color set default null,
alter cost_price set default null,
alter sales_price set default null,
alter created_at set default null;
-- (5/5)テストデータ挿入
insert into megane11 values (),(),();
select * from megane11;
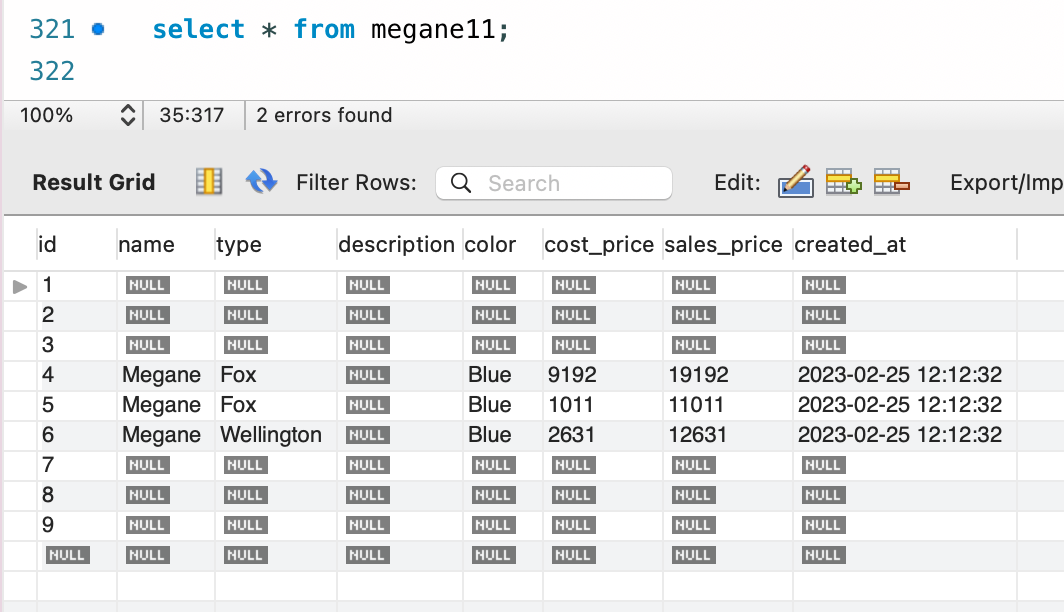
とはいえテーブルの設定を変更することになるので、本番はもちろん、DEV 環境でも基本的には使いたくない手法ですね。
あくまで個人の検証レベルで使えるかもしれない、レベルでしょうか。
9. 大量のテストデータを挿入する 4 ( ストアドプロシージャを使う )
ここまでは SQL 単体でテストデータを作成してきました。次はストアドプロシージャでの作成方法を紹介します。
DELIMITER $$
CREATE PROCEDURE sample1()
BEGIN
set @start = 0;
set @end = 100;
while @start < @end do
insert into megane1 (name, type, description, sales_price, registered_date, created_at) values
(
concat( SUBSTRING(MD5(RAND()), 1, 3), "メガネ"),
(elt(FLOOR(1 + (RAND() * 4)),"Round", "Fox", "Rimless", "Wellington")),
concat("とても", SUBSTRING(MD5(RAND()), 1, 12)),
CEIL(RAND() * 30000),
date(DATE_ADD(now(), INTERVAL FLOOR(5 + (RAND() * 5)) DAY)),
now()
);
set @start = @start + 1;
end while;
select * from megane1;
END$$
DELIMITER ;
データの作成方法は先ほどまでと同じです。ストアドプロシージャの場合は for ループが使えるので、指定回数分愚直に insert を実行するという方法が取れますね。
ちなみに 100 万件のテストデータを遊びがてら挿入していて気づいたんですが、ストアドプロシージャの for 中の Insert では都度 Commit が走ります。
大量に Insert するなら、for の前で autocommit を 0 にしておくと早くなります。( 最後に明示的に commit することと、autocommit を戻すことを忘れずに )
10. 大量のテストデータを挿入する 5 ( csv を使う )
最後は CSV を用いてテストデータを作る方法です。
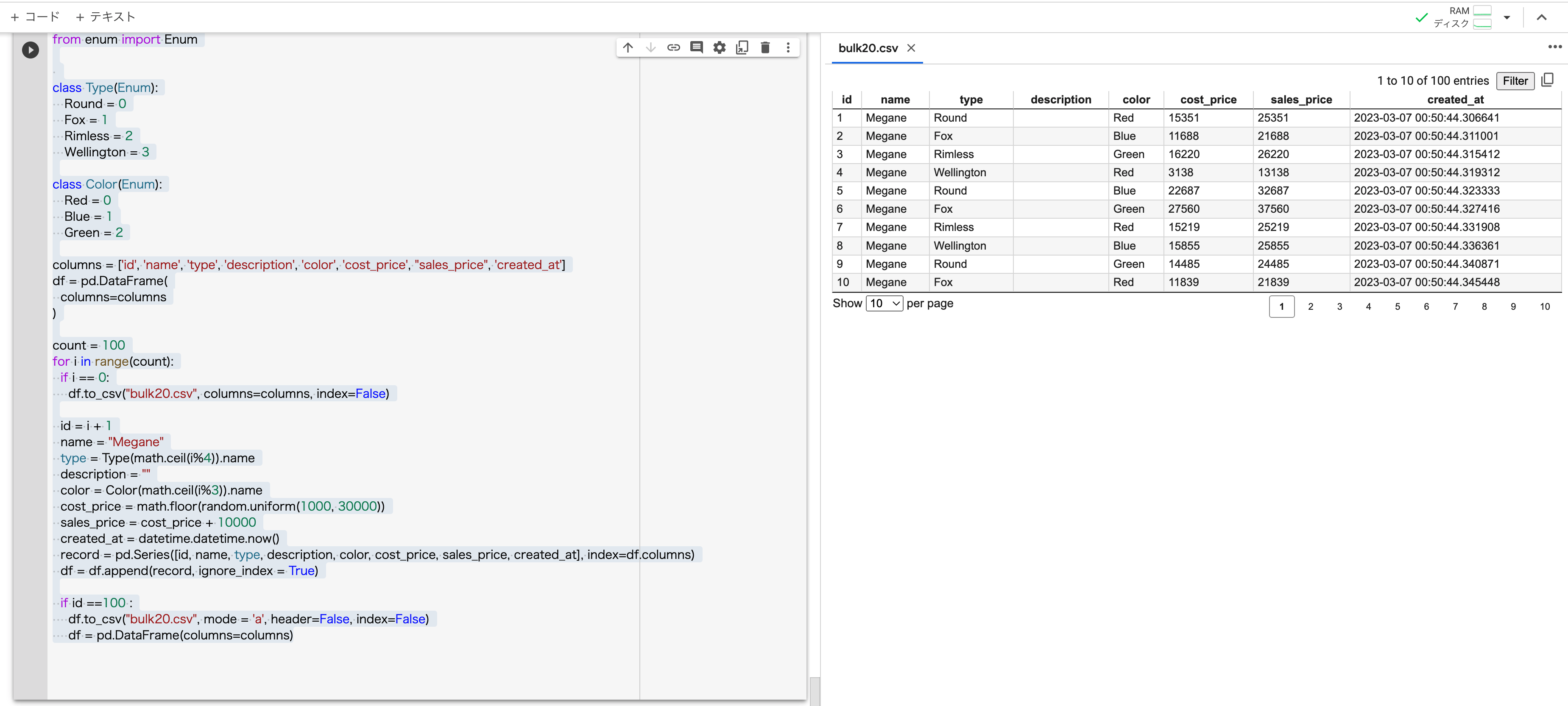
まずは CSV の用意から。今回は Python を使って Google Colab 上で生成します。コード書くのは本業ではないので質はご容赦。
データの生成ロジックはこれまでと同じです。
import math
import random
import datetime
import pandas as pd
from enum import Enum
class Type(Enum):
Round = 0
Fox = 1
Rimless = 2
Wellington = 3
class Color(Enum):
Red = 0
Blue = 1
Green = 2
columns = ['id', 'name', 'type', 'description', 'color', 'cost_price', "sales_price", 'created_at']
df = pd.DataFrame(
columns=columns
)
count = 100
for i in range(count):
if i == 0:
df.to_csv("bulk99.csv", columns=columns, index=False)
id = i + 1
name = "Megane"
type = Type(math.ceil(i%4)).name
description = ""
color = Color(math.ceil(i%3)).name
cost_price = math.floor(random.uniform(1000, 30000))
sales_price = cost_price + 10000
created_at = datetime.datetime.now()
record = pd.Series([id, name, type, description, color, cost_price, sales_price, created_at], index=df.columns)
df = df.append(record, ignore_index = True)
if id ==100 :
df.to_csv("bulk99.csv", mode = 'a', header=False, index=False)
df = pd.DataFrame(columns=columns)
100 行のテストデータができました。
余談ですが dataframe 使う時も、100 万件のデータをメモリに乗せて一気に csv に書き込もうとすると死にます。( 死にました )
10,000 件くらいで切って書き込んで書き込み終わったらフラッシュして次へ、くらいがよかったです。
では Import していきます。コマンドは次の通りです。
LOAD DATA INFILE '/tmp/bulk99.csv' INTO TABLE megane1 FIELDS TERMINATED BY ',' IGNORE 1 LINES;
終わりに
ここまでご覧いただきありがとうございました。 この記事があなたのテストデータ作成の助けになれば幸いです。
弊社 Belong では一緒にサービスを育てる仲間を募集しています。
もし弊社に興味を持っていただける方がいらっしゃったら、 エンジニアリングチーム紹介ページ をご覧ください。
では今回はここまで。サヨウナラ!
参考( MySQL 公式以外 )
- set 変数の使い方
- elt の使い方
- ストアドプロシージャのサンプル
- ランダム作成
- sha 文字列
- ランダムな位置の文字列取得
- insert と with
- ホストとコンテナ間のファイルコピー
- load data infile エラー関連
- https://ts0818.hatenablog.com/entry/2021/03/04/183254
- https://washiharu.com/mysql57-load-data-infile/
- https://ssrv.net/tech/mysql-import-files/
- https://qiita.com/You_name_is_YU/items/6d87f7664c947df84dc1
- https://yoku0825.blogspot.com/2018/07/mysql-80load-data-local-infile-error.html
- https://yoku0825.blogspot.com/2020/02/mysql-workbenchload-data-local-infile.html
- https://mysql.sql55.com/query/mysql-load-data-import-csv.php
[補足] LOAD DATA INFILE で発生するエラーへの対応
私の環境では CSV ロードが成功するまでエラーがだいぶ出ました。ので備忘録の意味でもエラー内容と対処方法を記録しておきます。
(1) CSV を読み取ることができない
docker コンテナで MySQL を実行しているとき、コンテナの外にある CSV を読み取ることができません。
ERROR 2 (HY000): File '/Users/xxx/Downloads/bulk20.csv' not found (OS errno 2 - No such file or directory)
その場合、コンテナの中に CSV をコピーして、コンテナの中の絶対パスを指定してください。
sudo docker cp '/Users/xxx/Downloads/bulk99.csv' '${コンテナのID}:/tmp/bulk99.csv'
LOAD DATA INFILE '/tmp/bulk99.csv' INTO TABLE megane1 FIELDS TERMINATED BY ',' IGNORE 1 LINES;
(2) LOAD コマンドの実行が拒否される
LOAD DATA ステートメントはセキュリティな観点から、デフォルトで実行が制限されていることがあります。
ERROR 1148 (42000): The used command is not allowed with this MySQL version
この場合、ローカルデータロードを許可するための設定を行います。サーバー側とクライアント側の両方から設定を行う必要があります。
// Server side
set persist local_infile=1;
// Client side
// 接続時に以下のオプションを渡す
--local-infile=1
(3) CSV の読み込みが許可されない
CSV のインポートやエクスポートもまた、セキュリティの観点から禁止されていることがあります。
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
secure_file_priv は、インポートやエクスポートの操作が許可されるディレクトリの情報です。
null の場合は全てが許可されず、空文字の場合は全て許可されます。私の環境ではデフォルトで null でした。
以下のコマンドで確認できます。
select @@secure_file_priv;
この値が null で CSV の読み取りが行えない場合は、MySQL 起動時にコマンドオプションでこの値に明示的に空白を設定します。
--secure-file-priv=""