L1/L2/L3 レイヤーを用いたシステムサポートの実践について
▼ はじめに
株式会社 Belong で Engineering Manager をしている七色メガネです。
この記事では、弊社の基幹システム運用におけるサポートチームのレイヤー体制や業務の内容を紹介します。
私たちのサポート体制は、以下の 2 つを重視して構築したものになります。
- Google で提供されている SRE Book (https://sre.google/sre-book/table-of-contents/) に則ったベストプラクティスの実践
- 弊社 CTO が ソフトウェアエンジニアとして開発に加えて自らサービス運用・サポートをしていたこと、またサポートの専門家としてシステムサポートに取り組んでいた経験をベースに、私たちのビジネスに適合するようテーラリングした活動の実践
従って、まだ若い会社であるとはいえ実践の内容自体は決してレベルの低いものではないと自負しています。
またこの運用は、様々な変遷を経たものの 3 年ほど継続運用してきたものになるので、ここまでの経験を踏まえた上での所感も併せて記載しようと思います。
よろしければお付き合いください。
▼ チーム体制
私たちのサポートチームは、開発者・非開発者が混在する形で構成されており、Level 1, 2, 3 という区分で業務を分割しています。
うち Level 1 を非開発者が担い、Level 2 と 3 を開発者が担っています。
サポート活動の主な内容はシステムアラートへの対応やユーザーからの問い合わせへの対応です。
それらが発生した場合にはまず小さい Level の人が受け取り、対応を行い、解決できない場合には次の Level にエスカレートする、という体制になっています。
開発者は通常システム開発に従事しており、週番制で L2 あるいは L3 サポート業務を行います。 当番であっても常時サポート活動があるわけではないので、アラートや問い合わせが発生するまでは開発業務を進行します。 L1 Support についても同様であり、アラートなどがない場合には他の業務を行っています。
つまりシステムサポートのみを行う専任のチームがあるわけではなく、
開発者を中心とした流動的なサポートチームがシステムサポートを行っている、というのが弊社基幹システムサポートにおける運用の形になっています。
▼ レイヤーコンセプトについて
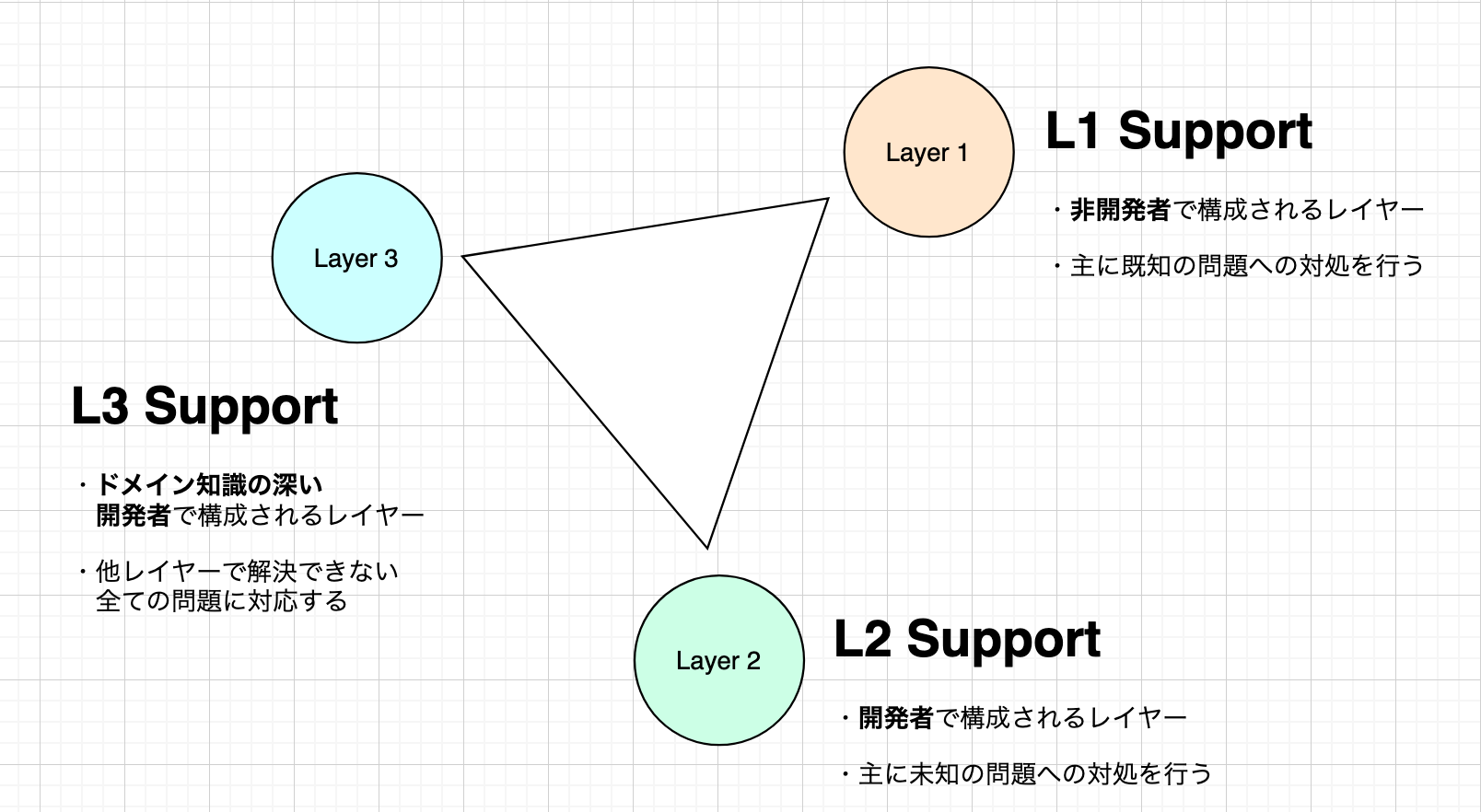
私たちのサポートチームでは、L1 / L2 / L3 という三種類のレイヤーを用いることで、各メンバーの責任を分担しています。
◻︎ L1 Support
L1 Support は、非エンジニアのメンバーから構成されます。主な業務は以下の通りです。
- アラートや問い合わせに対する一次対応を行い、内容や事実関係などの情報を整理する。
- 「トラブルシューティング集」や「問い合わせへの対応集」を参照し、現在発生している問題が既知の問題であるかを確認する。既知の問題であれば、自身で問題を解決する。
- 発生したアラートや問い合わせが未知の問題である場合は L2 Support にエスカレートを行う。
L1 Support はアラートや問い合わせのフィルタリングを行うレイヤーになるため、他のレイヤーよりも作業量が多くなります。
反面、基本的には既知の問題にしか対応せず未知の問題の場合は即座に次のレイヤーにエスカレートすることが期待されているため、
作業難易度としてはあまり高くないレイヤーとも言えます。
◻︎ L2 Support
L2 Support は、エンジニアのメンバーから構成されます。 このレイヤーを担うエンジニアは、 「一般的なエンジニアリングスキルを持っており、それに基づいた問題調査・対応が可能だが、当該システムに対するドメイン知識がまだ浅い」 ような属性のメンバーになります。 主な業務は以下の通りです。
- L1 Support からエスカレートされた問い合わせやアラートを確認し、既知の問題であるかを確認する。
- 未知の問い合わせやアラートであれば、自身で解決を試みる。必要に応じて Incident を宣言し、自身が Owner となって問題解決をコントロールする。
- 問題解決が一定時間以内に行えない場合、あるいは明らかに自身の力では問題解決が行えないと判断された場合、L3 Support にエスカレートを行う。
「自身で解決できない場合のエスカレート先があるかどうか」という点が L2 Support と L3 Support の大きな違いです。
「この問題は L3 Support しか対応してはいけません」のようなことは基本的に (※1) 無く、全ての開発者が等しく問題解決のために自分ができることをする、というのが基本コンセプトになります。
※1 ... 一部 Incident ( システム障害 ) の宣言にあたっては、会計インパクトなどの判断を L3 Support あるいは他のステークホルダーに委譲することがあります。
◻︎ L3 Support
L3 Support もエンジニアのメンバーから構成されますが、
システムについて L2 Support よりも深いドメイン知識を持っているメンバーがこのレイヤーを担当することになります。
主な業務は L2 Support と変わりませんが、L3 Support は問題をエスカレートする相手はいないため、
自身で問題解決ができない場合には、他のチームやステークホルダーなどの力を積極的に借りるなど、問題解決のためにあらゆる手を尽くすことを意識します。
▼ 業務内容
サポートチームが行う業務内容は主に以下の通りです。
- システムアラート対応
- ユーザー問い合わせ対応
- Incident 対応
アラート対応と問い合わせ対応は概ね同じワークフローになるため、合同で解説をします。
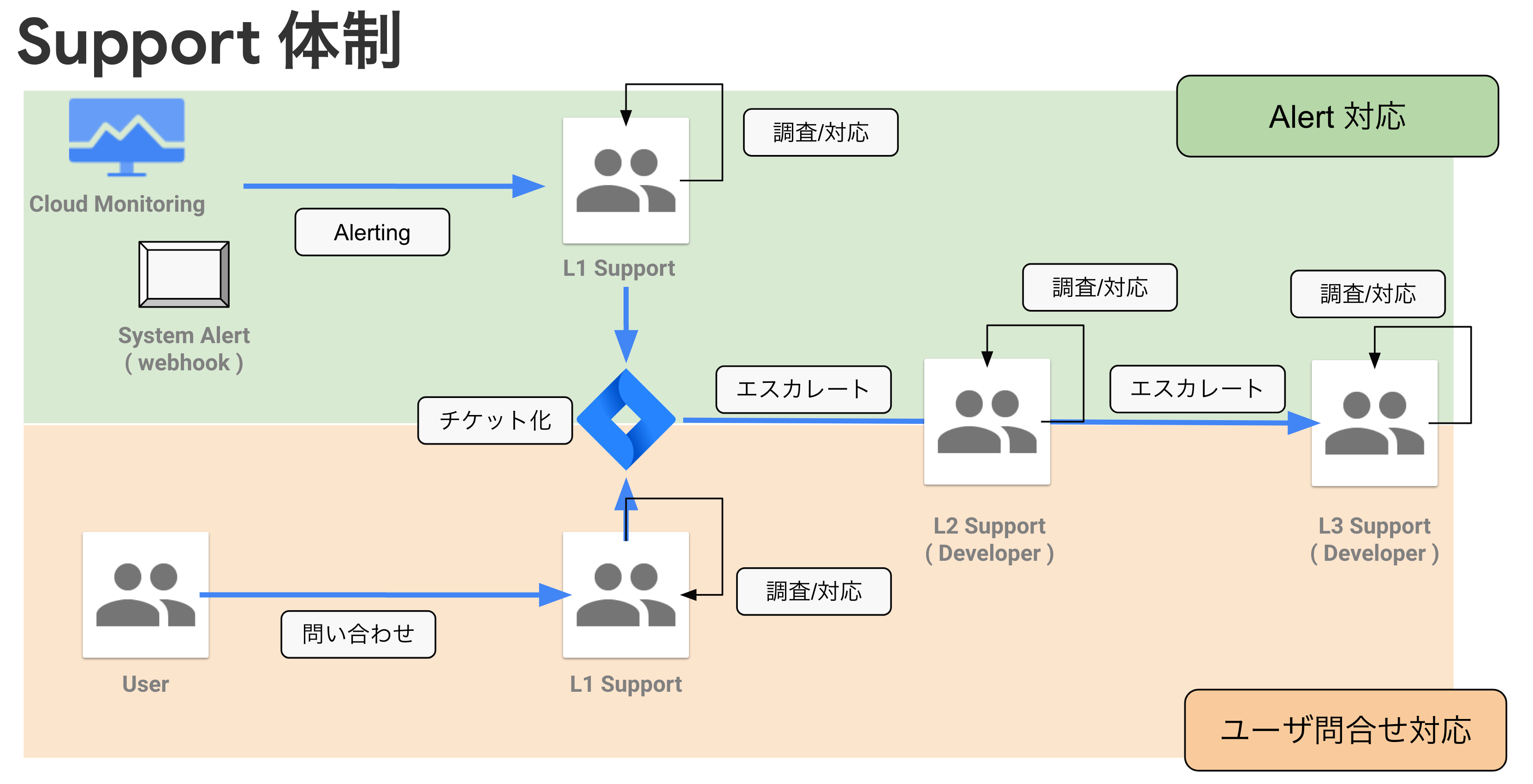
◻︎ 業務の流れ (1) アラート/問い合わせ 対応
以下は私たちのアラート対応のワークフローイメージです。
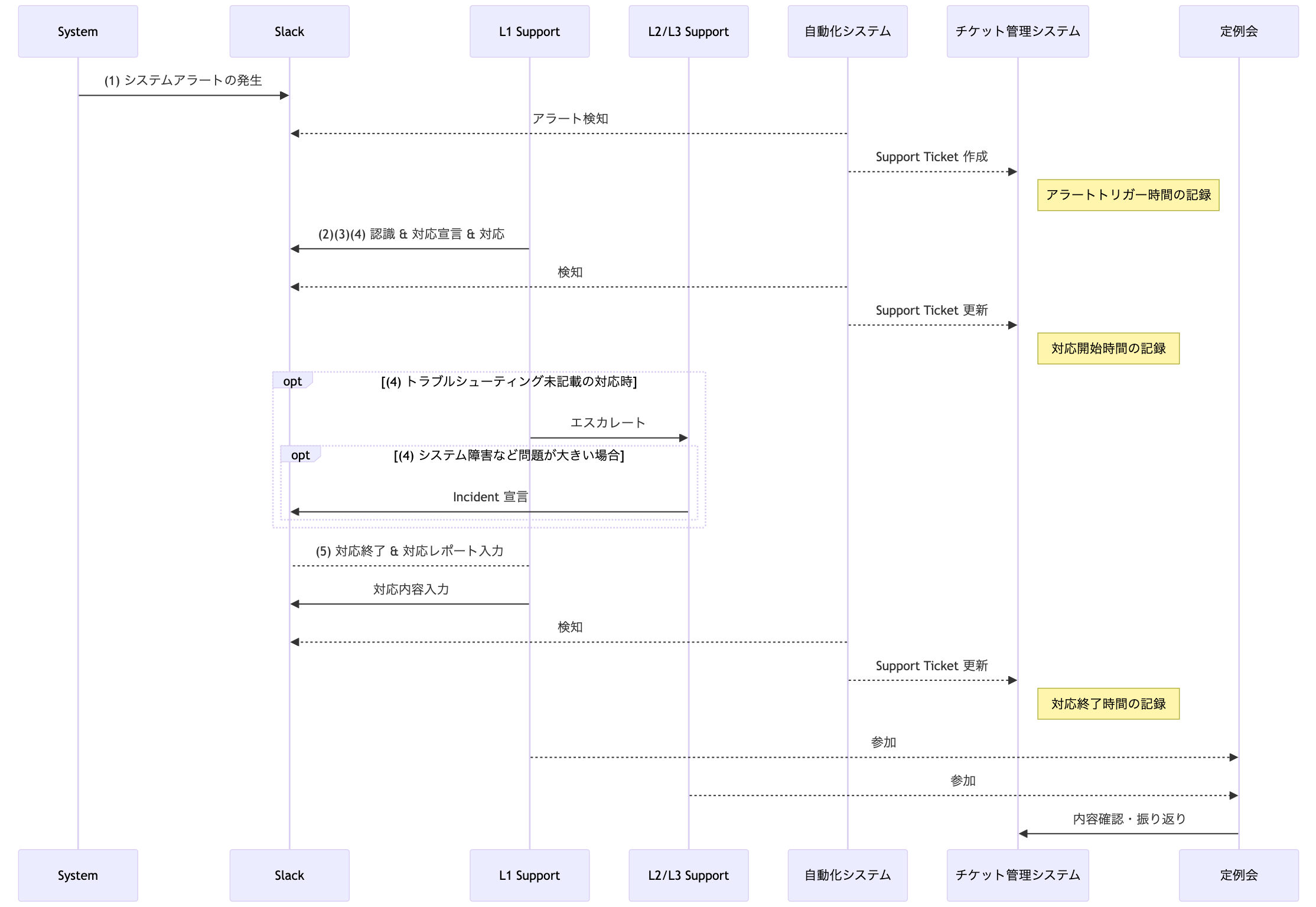
大きな流れについて、文字でも解説を加えます。
- 問題の発生
- アラートや問い合わせの発生自体です。
- アラートや問い合わせの発生自体です。
- 問題の検知
- 私たちの運用ではシステムアラートや問い合わせは Slack 上に通知されるようになっています。従って、問題の発生は Slack を監視しておくことで検知することができます。
- 私たちの運用ではシステムアラートや問い合わせは Slack 上に通知されるようになっています。従って、問題の発生は Slack を監視しておくことで検知することができます。
- 対応開始の宣言
- アラートの発生を通知する投稿に対して、Slack のスタンプを押下することで「対応開始」が宣言されます。
- アラートの発生を通知する投稿に対して、Slack のスタンプを押下することで「対応開始」が宣言されます。
- 問題対応
- 前述の通り、L1 Support は現状の確認・情報の整理・既知の問題であれば対応を行います。未知の問題である場合エスカレートが発生し、L2/L3 Support が対応を行います。
- 過去に発生したアラートや問い合わせに対する対応記録は、トラブルシューティングや問い合わせ対応集という形でまとめているため、そちらを参照します。
- クロージング
- ワークフローを通じて対応内容を記録することで、サポート活動が終了します。
- ワークフローを通じて対応内容を記録することで、サポート活動が終了します。
基本的に最初の対応は L1 Support の人が行いますが、
明らかに緊急度が高いアラートである場合や L1 Support の人が即座に反応できない場合などは、臨機応変に L2 以上の Support の人も初動にあたります。
◻︎ 業務の流れ (2) Incident 対応
システムの機能障害やデータの破損などを原因として、ユーザーによるシステム利用の一部あるいは全部に問題が発生した場合、その問題を Incident として扱います。
Incident は主に以下のパターンで発生します。
- システムアラート対応によって発見された問題から。
- システム動作に関するユーザー問い合わせから。
- 開発者のシステム監視や気づきから。
基本的には (1) 及び (2) で検知されますが、Incident は基本的に想定外の問題に根ざすものであるので、 (3) としての開発者の気づきや違和感から発見されることも多々あります。
Incident 発生時の対応フローイメージは次のとおりです。
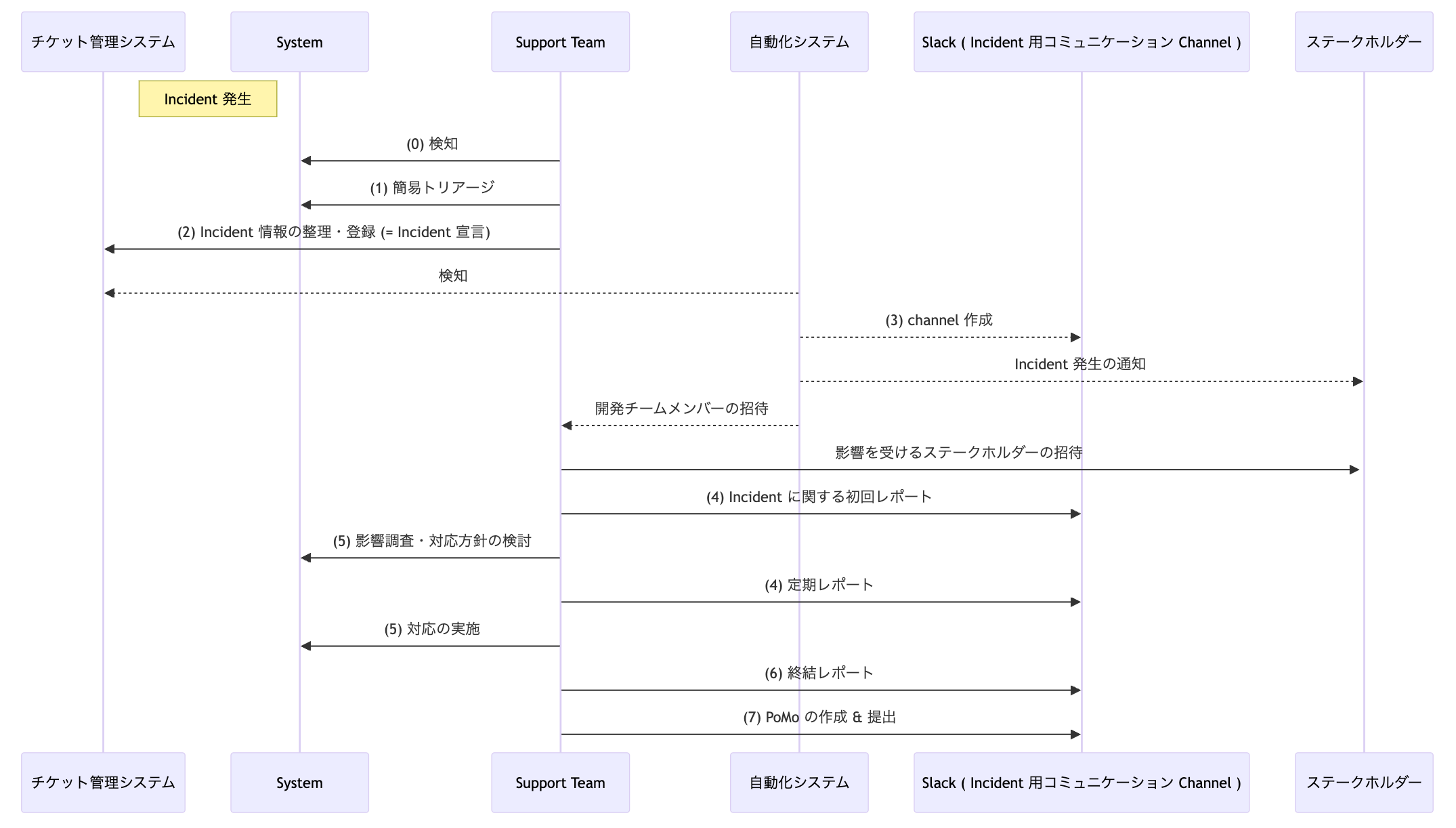
重要なポイントを文字でも解説します。
-
簡易トリアージ
- incident を宣言する前に、この問題がどれほど影響をステークホルダーに与えるかを簡易的に判断します。判断に基づき、Incident の Priority と Severity を決定し、Incident 情報として整理します。
- Severity ... その Incident がどれだけのビジネス影響をもたらすかを、Sev1(深刻な影響) ~ Sev4 (影響はない) の 4 段階で表現します。
- Priority ... その Incident の収束がどれほど急がれるかを、P1 (24 時間以内/可及的速やかに) ~ P4 (1 ヶ月以内に) の 4 段階で表現します。
- 情報が揃っていない中での判断になるので、正確な判断にならなくて構いません。情報が正確になったのちに、Priority や Severity が更新されることになっても構いません。
- この時点では「問題がなぜ発生しているのか」「どうすれば問題は解決できるか」は調査しません。
- incident を宣言する前に、この問題がどれほど影響をステークホルダーに与えるかを簡易的に判断します。判断に基づき、Incident の Priority と Severity を決定し、Incident 情報として整理します。
-
Incident の宣言
- 問題の大小に関わらず、Incident と判断された場合にはなるべく早く Incident を宣言します。この際、トリアージで決定した Priority と Severity を共有し、どの程度の危機度の Incident であるかをステークホルダーが理解できるようにします。
- 問題の大小に関わらず、Incident と判断された場合にはなるべく早く Incident を宣言します。この際、トリアージで決定した Priority と Severity を共有し、どの程度の危機度の Incident であるかをステークホルダーが理解できるようにします。
-
コミュニケーション導線の整備
- 以下の整理を行い、以降のコミュニケーションが円滑に行えるようにします。
- Communication Channel の作成 ... Incident に関する情報のみを扱う Slack Channel を作成します。
- Communication Owner の宣言 ... Incident に関する情報提供を一元的に行う人物を決めます。基本的に L2/L3 Support が務めます。
- Operation Owner の宣言 ... Incident に関する調査やシステム修正を行う人物を決めます。Communication Owner ではないメンバーが務めます。
- ステークホルダーの招致 ... Incident の影響を受けると思われるユーザーや責任者など、ステークホルダーを Channel に招致します。開発チームに判断ができない場合、誰がステークホルダーであるかの判断はユーザー側責任者に依頼します。
- 以下の整理を行い、以降のコミュニケーションが円滑に行えるようにします。
-
逐次報告
- Communication Owner は、 Incident に関する情報を常にアップデートし、都度ステークホルダーに共有します。共有事項は主に以下の通りです。
- 問題の概要
- 問題の原因
- 問題の発生頻度
- 問題を回避するためのワークアラウンド方法の有無及び内容
- 影響範囲
- 今後のシステム対応予定
- Communication Owner は、 Incident に関する情報を常にアップデートし、都度ステークホルダーに共有します。共有事項は主に以下の通りです。
-
問題の調査・対応方針の決定・対応策の実施など
- (4) の報告と並行して、実際のシステム対応を進行します。
- 調査やシステム修正など実作業は Operation Owner が行い、その内容を Communication Owner がステークホルダーに共有するという体制を取ります。
-
クロージング
-
Postmortem (PoMo) の作成
- Incident 終結後、その Incident から得る学びや教訓がある場合には PoMo を作成します。
- Incident 終結後、その Incident から得る学びや教訓がある場合には PoMo を作成します。
Incident 対応において陥りがちなのは「障害原因の追及・回復に集中しすぎて、情報の共有が漏れる」ということです。
これを避けるため、実際にシステム修正などを行う人とコミュニケーションを行う人を分けて、情報を常に更新することを意識します。
 ( 過去の Incident における Communication Owner による初回レポートの図 )
( 過去の Incident における Communication Owner による初回レポートの図 )
▼ 活動の評価について
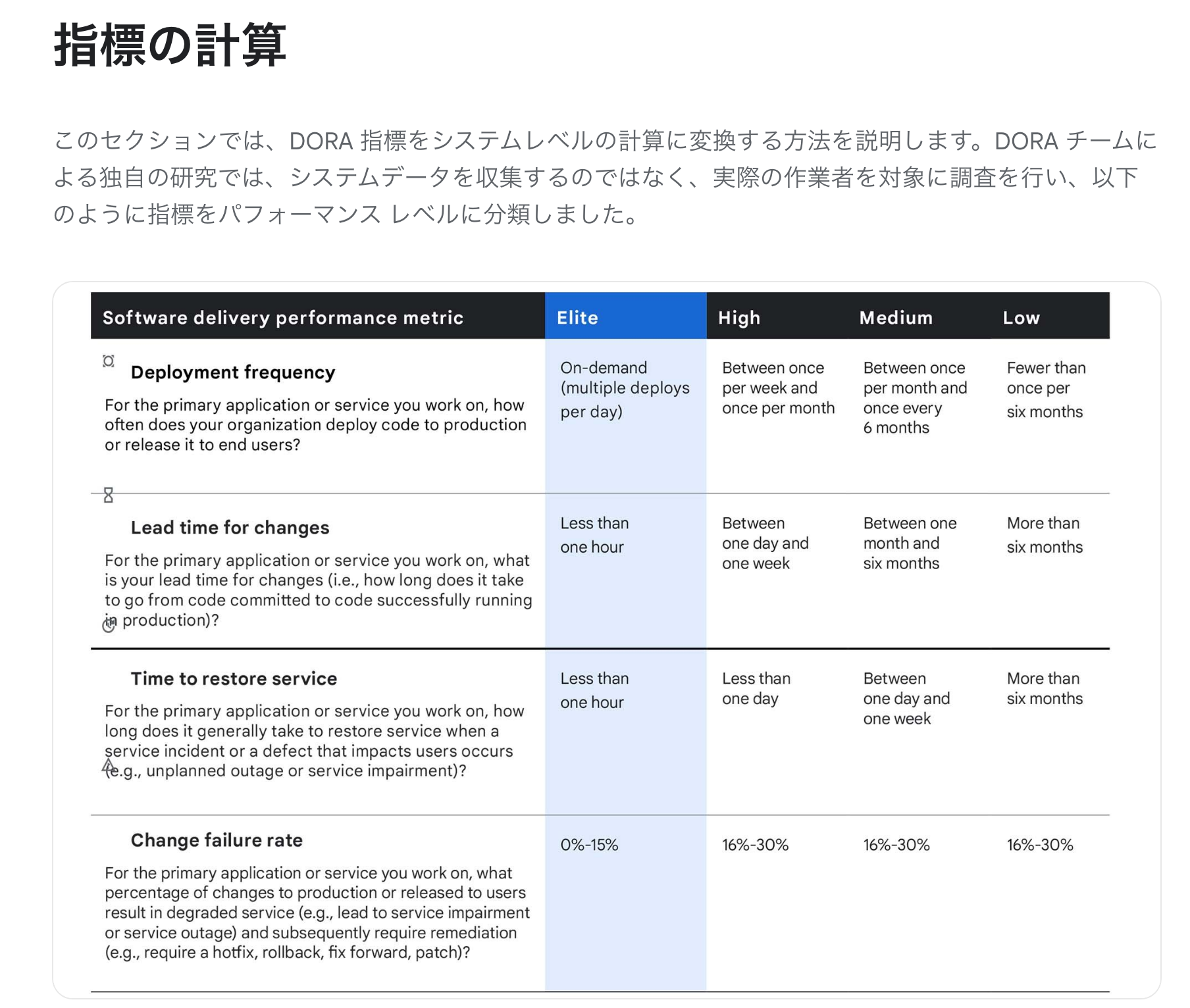
◻︎ Four Keys とサポート活動
私たちの活動を紹介する前に、DevOps チームのパフォーマンスを示す概念として用いられる Four Keys という考え方に触れます。
 (参考: https://cloud.google.com/blog/ja/products/gcp/using-the-four-keys-to-measure-your-devops-performance)
(参考: https://cloud.google.com/blog/ja/products/gcp/using-the-four-keys-to-measure-your-devops-performance)
どの観点も重要なのは論じるまでもありませんが、システムサポートの観点においては特に、Time to restore service という点を重視することで活動の品質をあげることができます。
記載の通りこれは、「本番環境で障害が起きてから、その問題が回復するまでにどれだけ時間がかかったか」を測る指標になります。
Google の基準によれば、それが 60 min 以内であれば Elite チームと言って差し支えないということになります。
システムの規模や発生した問題のレベルによっては、常に 60 min 以内に問題回復することが最善であるとは思いませんが、一つの数値目標目安として十分有用であると思います。
ただし、サポート活動に関する数値基準はこの Time to restore service だけではありません。
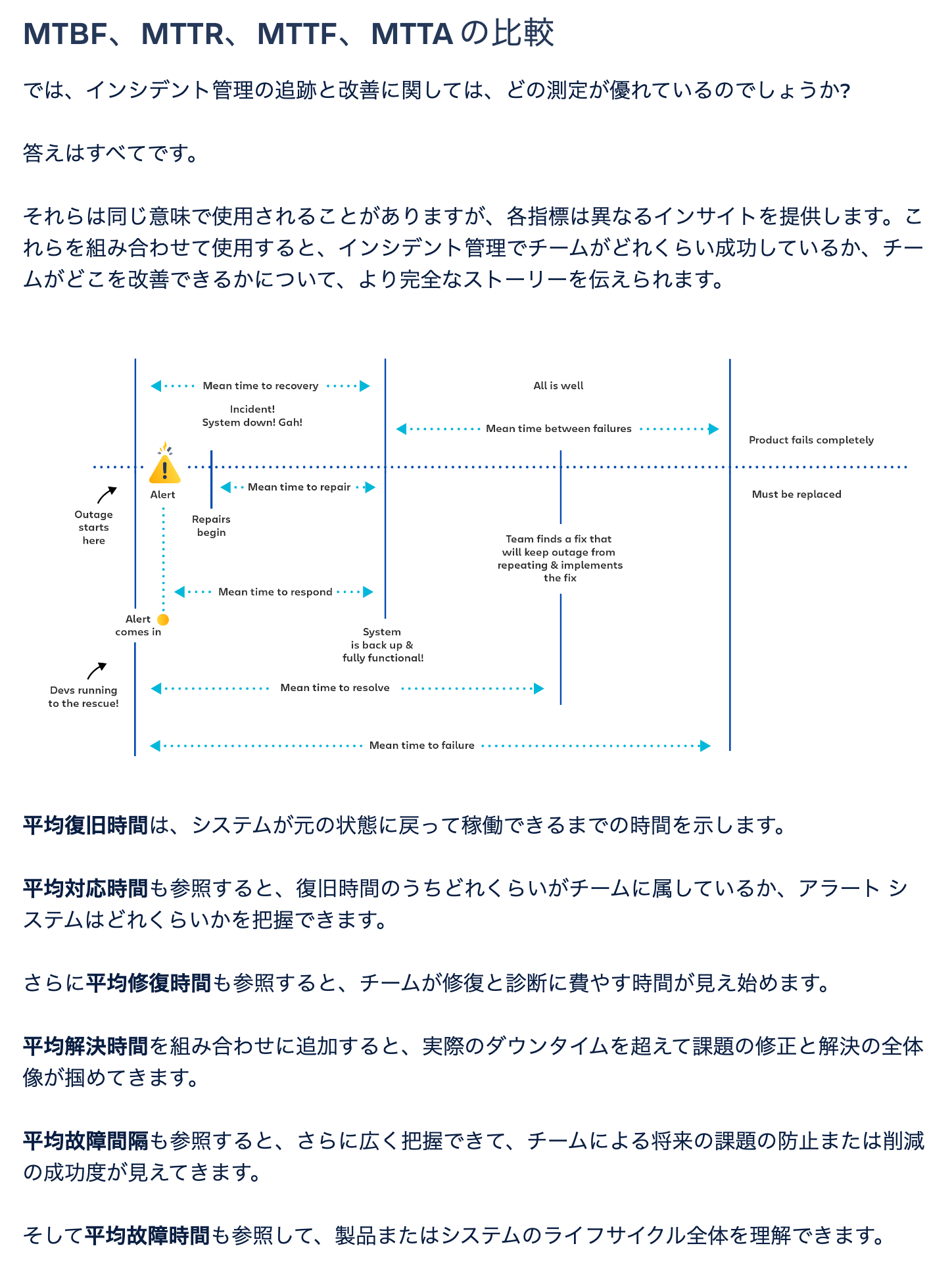
例えば Attlasian が提供する Common Metrics のページでは、その他の指標も多く紹介されています。
 (参考: https://www.atlassian.com/ja/incident-management/kpis/common-metrics)
(参考: https://www.atlassian.com/ja/incident-management/kpis/common-metrics)
本質的にはどの指標も価値あるものですが、どの指標がチームやシステムに価値をもたらすかは、状況によって異なります。 アラート検知が遅いのであれば MTTA が、障害が多すぎるのであれば MTBF が、価値ある指標になります。 指標を適当に使用するのではなく、自分たちにとって最も価値があると思われる指標を取捨選択して運用していくことが最も重要であると、私たちは考えています。
◻︎ 評価指標について
上記を踏まえてですが、私たちのサポート活動においては以下の評価指標を用いています。
- Time to Acknowledge ( TTA )
- Time to Repair ( TTRepair )
- Time to Resolve ( TTResolve )
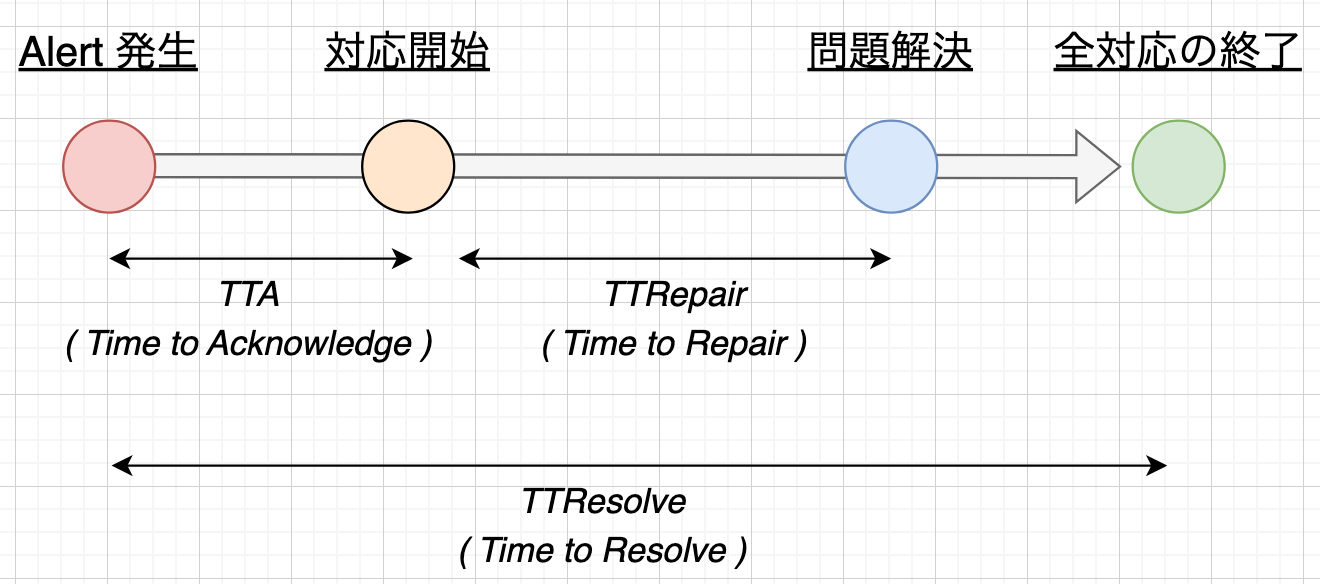
- TTA とは、アラートが発生してから最初の対応が行われるまでの時間になります。これが短い場合、新規アラートが放置される時間が短く即座に何かしらの対応を始められている、ということになります。
- TTRepair とは、対応を開始してから問題が解決するまでの時間になります。これが短い場合、問題解決のための行動が速やかに行えている、ということになります。 Incident 対応の場合は問題解決後に PoMo の作成などを行う必要がありますが、PoMo の作成速度などは重視していないため、問題解決までを終点とした Repair 値を使用しています。
- TTResolve とは、アラートが発生してから全ての対応が完了するまでの時間になります。通常のアラート対応の評価にはこちらを使用しています。
発生するアラートが既知の問題なのか未知の問題なのか、あるいは大規模な障害なのか小規模な障害なのか、
など問題の性質によって TTA/TTR は必ずしも小さくすることができない場合があります。
従って絶対の評価基準としてこれらの値を用いることはしていません。
しかし時間的な目標があれば対応時間という意識をもたらすことができるため、私たちのチームではこれらの数値について目標を定めて、毎週の活動を数値ベースで振り返っています。
各数値における目標は、以下の通りです。
- アラート対応について
- TTA ... 30 min 以内
- TTRepair ... なし
- TTResolve ... 60 min 以内
- Incident 対応について
- TTA ... 30 min 以内
- TTRepair
- Sev3 ~ 4 の Incident ... 14 days 以内 ( = 遅くとも次回のリリースまでにシステム修正を行う )
- Sev1 ~ 2 の Incident ... 60 min 以内 ( = まずはロールバックによる回復を検討し、それが難しい場合にはパッチリリースやメンテナンスによる復旧を図る )
- TTResolve ... なし

この目標を達成できているかどうかの確認については、週次で行っている定例会にて Looker Studio を使用して行っています。
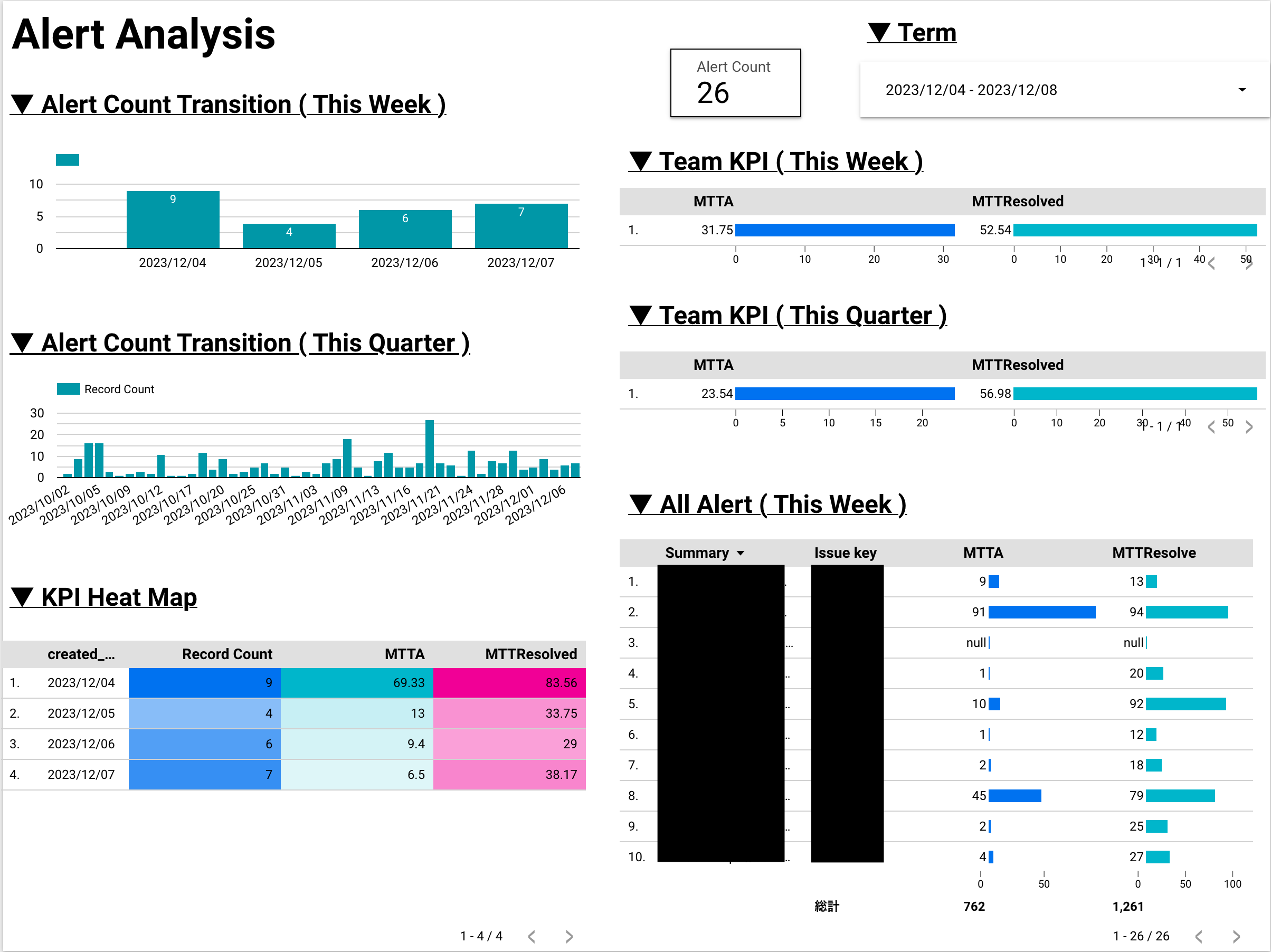 ( これは Alert のページ )
( これは Alert のページ )
▼ 使用ツールについて
私たちのサポート活動では主に以下のツールが用いられています。
- Slack ... アラート用、Incident 用の channel を使用したり、Slack ワークフローを使用することで作業を自動化したりなどを行う。
- Jira ... サポートタスクを自動で Jira にてチケッティングし、ステータス管理や TTA/TTR の記録、活動の分析などを行う。
- Confluence ... トラブルシューティングや問い合わせ対応、各機能の仕様などをまとめ、サポート活動時に参照する。
- Zapier ... Slack と Jira を連携させ、自動チケッティングや Incident 発生時の初動自動化などを行う。
- Looker Studio ... 毎週のサポート活動内容を分析するために使用する。
▼ 実践してみての所感など
私が担当しているシステムは 2020 年に初回リリースが行われたので、上記サポート運用は 3 年ほど続けてきたことになります。( 最初から今の形ではなかったのですが )
最後にここまで運用してきて、学んだこと・思ったことなどを少しまとめます。
- 数値管理は難しい
- これに限ったことではありませんが、TTA/TTR は活動振り返りの目安にはなりますが、評価には使えません。個人の成績を確認するというスタンスではなく、チーム全体として TTA/TTR の数値の変遷に着目した方が実りが多いです。
- TTA/TTR は数値で活動を振り返るための良い指標ではありますが、これを計測・記録するのはすごく手間です。
私は提唱者なので手間を惜しみませんでしたが、今後担当者が変わった折には、費用対効果を考えるとやめてしまうのもありだと思っています。
- 対応マニュアル・ランブックは役に立つ
- Incident 対応はその場の機転が重要でありマニュアルやテンプレートは必要ない、という考え方をたまに目にします。
過去に縛られない柔軟さももちろん重要ですが、しかし重要な対応や急ぎのアクションを行う時には、無駄な思考ポイントを減らすこともまた重要です。
誰に連絡して、最初のレポートテンプレートはこうして、といった思考介入の余地が少ない定型のタスクについては、
マニュアルやランブックを作成する方がサポート活動全体の品質は上がると考えています
- Incident 対応はその場の機転が重要でありマニュアルやテンプレートは必要ない、という考え方をたまに目にします。
過去に縛られない柔軟さももちろん重要ですが、しかし重要な対応や急ぎのアクションを行う時には、無駄な思考ポイントを減らすこともまた重要です。
誰に連絡して、最初のレポートテンプレートはこうして、といった思考介入の余地が少ない定型のタスクについては、
マニュアルやランブックを作成する方がサポート活動全体の品質は上がると考えています
- 対応記録はしっかり残す
- アラート対応や問い合わせ対応を行うのは当然として、その時の対応記録を残すのも重要です。そのアラートはどの機能に関するものなのか、エラーメッセージはどのようなものなのか、誰が、どのように対応したのか、などです。
特に意識したいのは、検索容易性です。アラートや問い合わせ記録の種類が 100 を超えてくると、過去の類似対応を探すのがそもそも難しくなってきます。
ログメッセージをしっかり記載しておく、ラベリング管理しておく、など、将来利用できる形で記録を残しておく意識はとても大事です。
- アラート対応や問い合わせ対応を行うのは当然として、その時の対応記録を残すのも重要です。そのアラートはどの機能に関するものなのか、エラーメッセージはどのようなものなのか、誰が、どのように対応したのか、などです。
特に意識したいのは、検索容易性です。アラートや問い合わせ記録の種類が 100 を超えてくると、過去の類似対応を探すのがそもそも難しくなってきます。
ログメッセージをしっかり記載しておく、ラベリング管理しておく、など、将来利用できる形で記録を残しておく意識はとても大事です。
- 自作ツールは運用が大変
- 私たちはアラートの発生 → チケットの作成 → 更新 → クローズ、までを手製のノーコードワークフローで処理しています。が、システムの更新などで容易に動かなくなりますし、メンテナンス性を高めるのも骨です。
サポート活動は一過性のものではないので、活動がある程度の規模・期間に渡ることが見込まれるのであれば、PagerDuty などのサービスを利用することを検討する価値があると思います。
- 私たちはアラートの発生 → チケットの作成 → 更新 → クローズ、までを手製のノーコードワークフローで処理しています。が、システムの更新などで容易に動かなくなりますし、メンテナンス性を高めるのも骨です。
サポート活動は一過性のものではないので、活動がある程度の規模・期間に渡ることが見込まれるのであれば、PagerDuty などのサービスを利用することを検討する価値があると思います。
- 自然状態では「経験のある人」に仕事は集中する
- レイヤー体制を取っているとはいえ、自身で問題が解決できない場合にはエスカレートを行いますし、Incident 発生時の Owner 業務も自然と慣れている人がやりがちなので、自然状態では経験が一部の人に集中することになります。
本当に緊急度が高い時には経験のある人が迅速に対応することが望ましいですが、そうではない場合 (緊急度が低い、少し時間の猶予がある) などには、経験のある人とない人が一緒になって問題を整理してみる、経験のない人にコミュニケーション作業を任せてみる、
などチーム全体としてレベルアップできるような意識があるとサポート活動が属人化せず、全体として良い感じになるかなと思いました。( なんでもそうか )
- レイヤー体制を取っているとはいえ、自身で問題が解決できない場合にはエスカレートを行いますし、Incident 発生時の Owner 業務も自然と慣れている人がやりがちなので、自然状態では経験が一部の人に集中することになります。
本当に緊急度が高い時には経験のある人が迅速に対応することが望ましいですが、そうではない場合 (緊急度が低い、少し時間の猶予がある) などには、経験のある人とない人が一緒になって問題を整理してみる、経験のない人にコミュニケーション作業を任せてみる、
などチーム全体としてレベルアップできるような意識があるとサポート活動が属人化せず、全体として良い感じになるかなと思いました。( なんでもそうか )
- 必要なことは変わっていく
- 担当しているシステムは、3 年間で規模も利用人数も大きく変わりました。状況が変われば、サポートとして必要なことも変わっていきます。
サポート活動の性質上ワークフローやルールを決めていくことが多いので、サポートに長く関わっていると気持ちが保守的になっていきます。
しかしシステムは問答無用で形を変えていきます。
一度固めたルールに固執せず、現状に合わせて改善を加えていく姿勢、そしてそれを拒絶しないマインドが大事だと学びました。( なんでもそうか )
- 担当しているシステムは、3 年間で規模も利用人数も大きく変わりました。状況が変われば、サポートとして必要なことも変わっていきます。
サポート活動の性質上ワークフローやルールを決めていくことが多いので、サポートに長く関わっていると気持ちが保守的になっていきます。
しかしシステムは問答無用で形を変えていきます。
一度固めたルールに固執せず、現状に合わせて改善を加えていく姿勢、そしてそれを拒絶しないマインドが大事だと学びました。( なんでもそうか )
- 敬意だいじに
- レイヤー構造は作業分担ができる反面、定型業務は L1 レイヤーの人が行うことになります。 私のチームではレイヤー間の分断は発生しませんでしたが、他レイヤー (特に下位レイヤー) への敬意が損なわれた場合には、協力体制はいとも簡単に崩壊すると思います。 他人への敬意を忘れないように、というのはこれからも意識しなければいけないことです。( なんでもそうか )
▼ 終わりに
今回は弊社の基幹システム開発チームで行っている サポート活動についての解説記事でした。 もし更にご興味があれば、気軽にお問い合わせいただければと思います。
また弊社 Belong では一緒にサービスを育てる仲間を募集しています。
もし弊社に興味を持っていただけたら エンジニアリングチーム紹介ページ をご覧いただけたら幸いです。
では今回はここまで。ここまでご覧いただき、ありがとうございました。