Event Sourcing 入門編
はじめに
こんにちは。Belong Inc. で Backend Engineer を担当している niwa です。
近年、システム設計の文脈において Event Sourcing という単語を目にする機会が多くなりました。
Event Sourcing は DDD の文脈と共に語られることが多く、弊社も DDD のプラクティスを適用したシステム設計を行っている最中ということもあり、絶好の機会と思い Catch-Up を行いました。
本記事では入門編と題し、 Event Sourcing について、その特徴、および従前の State Sourcing とはどのような違いがあるのかを紹介したいと思います。
State / Event Sourcing
State Sourcing
一般的に使われることの多い、「アプリケーションが最新のデータの状態をストレージに永続化して利用する」パターンのことを State Sourcing と呼びます。
例として、State Sourcing で「財布の残高が 3 万円である」という状態を表現する場合は、下記のようなデータがストレージに記録されます。
| 残高 | 最終更新時刻 |
|---|---|
| 30000 円 | 2023-03-26 12:00:00 |
Event Sourcing
それに対し、「データに対して行われたすべての事実 ( = Event )を永続化する」というパターンが、Event Sourcing です。
Event Sourcing においては、ストレージに最新の状態は保存されません。最新の状態の導出は「過去の Event の記録を全て再適用する」ことにより行われます。
文章だと少しわかりにくいですが、上の例と同じように、「財布の残高が 3 万円である」という状態は、下記のようなデータによって表現されます。
| Event | 発生時刻 |
|---|---|
| 入金 (10000 円) | 2023-02-15 10:00:00 |
| 入金 (10000 円) | 2023-03-10 12:00:00 |
| 出金 (5000 円) | 2023-03-12 12:00:00 |
| 入金 (20000 円) | 2023-03-20 15:00:00 |
| 出金 (5000 円) | 2023-03-26 12:00:00 |
上記 Event を全て読み込み、アプリケーション側で「過去の値から順に、全ての Event を適用する」ことによって、「3/26 12:00 時点の財布の残高は 30000 円である」という状態の導出が行われます。
State Sourcing の特徴
我々が実際に開発するシステムについて、CRUD ( CREATE / READ / UPDATE / DELETE ) ができること、という要件を求められる機会は非常に多いです。そして、 State Sourcing のアプローチはこの CRUD に非常によく適合しています。
CRUD は状態について着目した設計思想であり、 基本的に CRUD が提供するものは「最新のデータを取得および操作するためのインターフェース」です。
State Sourcing において取り扱うものも「最新のデータ」であるため、両者の関心毎は共に一致しています。
ただ、State Sourcing の特性として、「なぜデータが今その状態になっているか」というコンテキスト、および履歴が失われてしまう、という点が挙げられます。現実世界においては、データの最新の状態とは別に、データがどのような変遷をして現在の状態になっているか、という点に価値がある場合があります。(ex: ユーザの行動分析 / 在庫の推移 など)
定期的なシステムの Snapshot を保存するなど、ある程度ストレージ側の対応によって実現できる部分もあるかとは思いますが、本質的にこの点をカバーするためには、アプリケーション自体の機能要件として、データの更新と同時に、履歴を発行して保存することを担保する、というアプローチが必要になります。
また、「最新のデータを永続化する」という要件上、データの更新を行う際に関しては、必ずロックを獲得することによるデータ整合性の担保が必要になります。 システムの利用者が多くなる、システム自体が取り扱うデータが大きくなるなどの最中に、この特性がスケーラビリティの問題を生むケースは多々存在します。
Event Sourcing の特徴
まず、第一に「過去のどの時点の状態でも復元可能である」ことが挙げられます。 先に述べたように、 Event Sourcing アーキテクチャにおいては、ストレージに「過去に発生した全ての Event 」が記録されます。
冒頭に紹介した Event 履歴を再掲します。
| Event | 発生時刻 |
|---|---|
| 入金 (10000 円) | 2023-02-15 10:00:00 |
| 入金 (10000 円) | 2023-03-10 12:00:00 |
| 出金 (5000 円) | 2023-03-12 12:00:00 |
| 入金 (20000 円) | 2023-03-20 15:00:00 |
| 出金 (5000 円) | 2023-03-26 12:00:00 |
この状態において、先程は「全ての Event を順に適用する」ことによって、最新の財布の残高を導出しました。ということは、特定の時刻までの Event を適用することで、特定時刻での財布の残高を導出することが可能になります。
仮に「2023-03-11 00:00:00」時点の財布の残高を知りたい場合、「発生時刻が 2023-03-10 23:59:59 以前」の Event 全てを適用することにより、2023-03-11 00:00:00 時点の財布の残高 ( = 20000 円 ) が導出可能 という形です。
また、この「全てのイベントの履歴を保持している」という特性は、未知の要件に対しても適合できる可能性が高い、という点も持ち合わせています。
例えば、「2023-03に 1 回以上出金したユーザ一覧を知りたい」と言う要件が発生したとします。
この場合、 当初の State Sourcing では 該当する情報が欠落しているため、「ユーザの出金履歴」という新たなデータ構造の定義が必要になります。また、過去のデータに対しての履歴は存在しないため、遡って対象ユーザを抽出する作業は難しくなります。
Event Sourcing においては、過去に発生した Event が全て永続化されているため、出金 Event の有無をチェックすることで当該ユーザの抽出が可能です。
また、スケーラビリティという観点でもメリットがあります。 Event Sourcing においては、ストレージにおいては発生した Event の追加のみを行います。これは即ち、「既存のデータに対しての更新は発生しない」ということを意味します。そのため、整合性担保のロックを行う必要がなくなり、スケーラビリティの向上につながります。
Event Sourcing の課題
ここまで Event Sourcing のメリットを紹介してきましたが、当然本手法にも State Sourcing と比べて問題があります。
データ容量の増大
Event Sourcing の実現にあたっては、データに対して発生した Event を全てストレージに記録する必要があります、そのため、最新のデータのみを保持する State Sourcing と比べ、データ保管に必要なストレージの容量は大きくなります。
状態導出のためのコスト
最新のデータの状態を導出するためには、データに対して発行された全ての Event を再生する必要があります。発行された Event が多くなるにつれ、状態導出のためのコストは高くなっていきます。
Snapshot Approach
上記の課題に対応するため、Snapshot Approach というパターンが一般的に知られています。
Snapshot Approach では、定期的にデータの状態を Snapshot として保存し、その Snapshot から Event の適用を開始することで、状態導出のコストを軽減することができます。
Snapshot Approach の適用例
財布の残高 モデルに、2023-03-14 00:00:00 時点での残高を保持している Snapshot の概念を追加します。データイメージとしては、下記のようになります。
Snapshot
| 残高 | 時刻 |
|---|---|
| 15000 円 | 2023-03-14 00:00:00 |
Event
| Event | 発生時刻 |
|---|---|
| 入金 (10000 円) | 2023-02-15 10:00:00 |
| 入金 (10000 円) | 2023-03-10 12:00:00 |
| 出金 (5000 円) | 2023-03-12 12:00:00 |
| 入金 (20000 円) | 2023-03-20 15:00:00 |
| 出金 (5000 円) | 2023-03-26 12:00:00 |
上記 Snapshot がある場合、
- Snapshot から、データの
2023-03-14 00:00:00時点での状態を復元 - その後、
2023-03-14 00:00:00以降の Event のみを適用
という手順を踏むことで、Event の適用件数を抑えつつ、最新の状態を復元することが可能になります。
Snapshot の保存間隔については、適用した Event の件数毎 / 定期的な間隔毎 など、システムの特性に応じて適切な閾値の選択が必要です。
検索要求に対して
ここまで敢えて触れてきませんでしたが、「最新のデータ一覧に対して、条件を指定しての検索を行いたい」というユースケースを考えてみます。 ストレージ上には最新の状態は存在しない (上記で述べた Snapshot も最新に近しい状態ではあるが、厳密に最新とは言い切れない) ため、最新のデータはアプリケーション側で Event を適用して導出する必要があります。 愚直にやると、アプリケーション上で検索対象になり得る全てのデータの最新の状態を導出した上で、検索条件に合致したものをアプリケーション内で選定し返却する、という実装になってしまいます。 理論的にはできなくなさそうですが、全てのデータに対しての最新状態を適用するコストやメモリ使用量の観点から、データ量が少し増えた段階でかなり厳しくなってしまいそうです。
このような場合どのような手法が取れるかというと、 Event のストレージとは別に検索用の Model を用意し、検索のオペレーションに関してはそちらに担わせる、というアーキテクチャ ( Read Model Architecture )が提唱されています。
下図が 財布の残高 モデルに、Read Model Architecture を適用した例です。
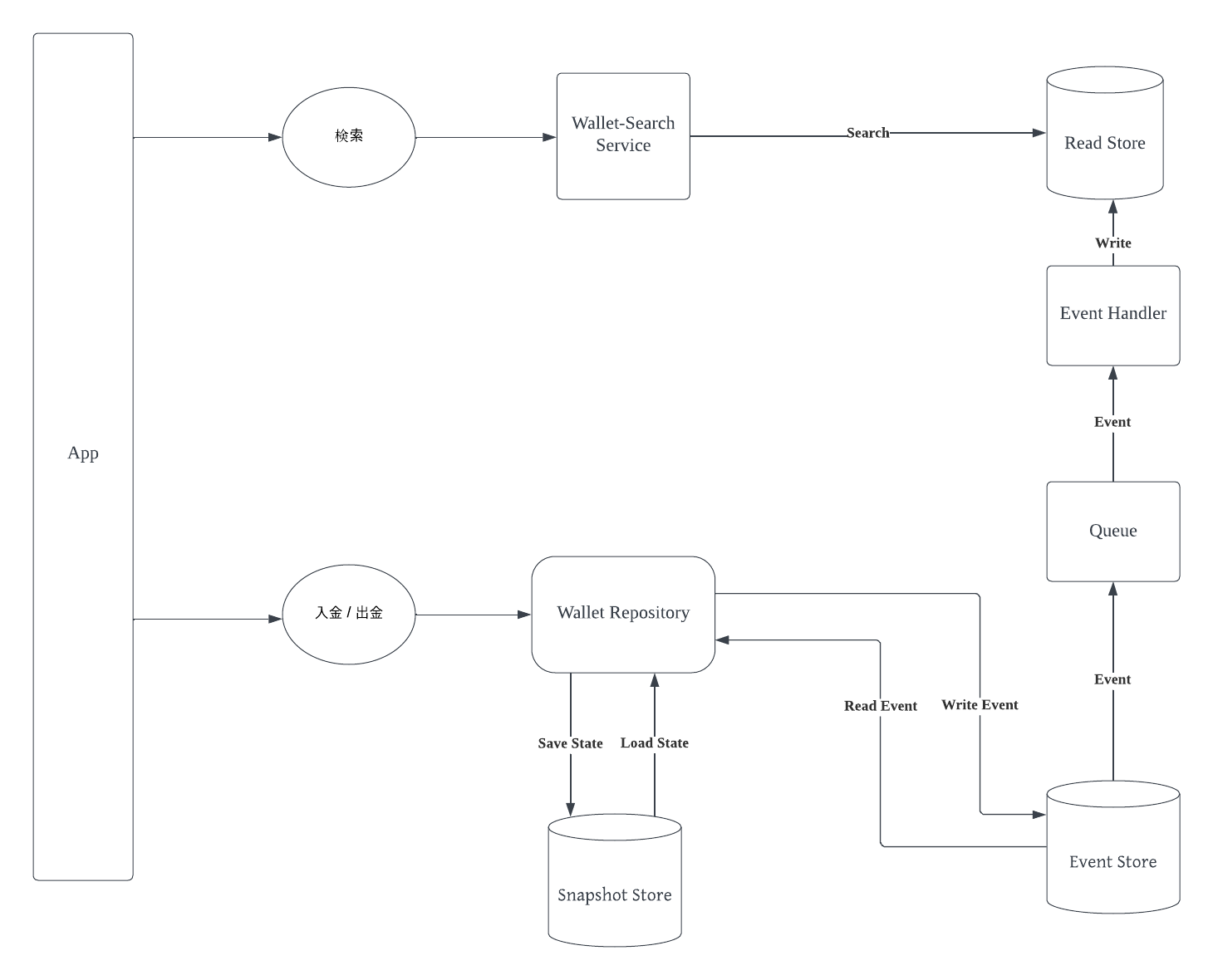
今回は「最新のデータに関して検索を行う」というユースケースのため、 Read Store は 最新の財布の残高一覧を保持します。
入金 / 出金 処理が行われると、Event Store に対して Event が発行されます。
発行された Event は、Event Store に永続化されたのち、Queue 経由で Event Handler に伝播されます。
Event Handler は受け取った Event (入金 / 出金 ) を解釈し、 Read Store に永続化されているデータを更新します。
検索処理は Wallet Repository を経由せず、検索用のサービス Wallet-Search Service により、Read Store に対して検索が行われる、という形になりました。ここまで来ると、システム構成の形としては CQRS とほぼ一緒になりますね。
このような Architecture を適用することで、 Event Store へのデータ追加のスケーラビリティを担保しつつ、ユースケースとして求められる最新データの検索を実現できるようになりました。
上記の形を取る場合、Event Store の更新が Read Store に伝播されるまでにタイムラグが発生するため、検索結果については結果整合性に基づく形となります。ここが許容されるかどうかも、アーキテクチャ選定の上の重要なポイントになります。
まとめ
今回は Event Sourcing について、Pros / Cons を示した上で、Cons を緩和するためのパターンをいくつか紹介しました。
次回は go のコードを示した、具体的な実装例にも踏み込めればと思っています。
最後に、Belong Inc. では我々と一緒にサービスの成長にコミットしてくれるメンバーを募集中です!
ぜひ エンジニアリングチーム紹介ページ をご覧いただけたら幸いです。