Cloud Tasks の採用を検討した話
はじめに
Belong では Google Cloud を利用しています。私のチームでは、非同期処理のプロダクトとして Pub/Sub の Push Subscription を利用することが多かったのですが、 要件を考えると Cloud Tasks のほうが適切ではないか? と感じることがありました。
結論から述べると結局採用には至らず、今の状態から変えることはなかったのですが、その経緯や採用に至らなかった理由を共有します。
なぜ Cloud Tasks の採用を検討したか
まず、私たちのある API の処理にフォーカスしたアーキテクチャを以下に示します。なお、Pub/Sub では Push subscription を利用しています。
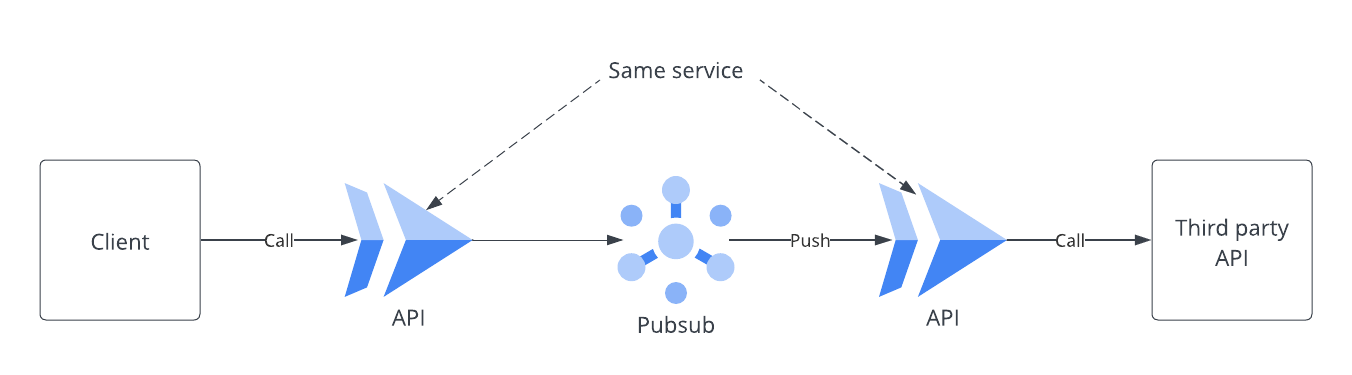
前述の図のアーキテクチャを採用している理由 = 要件は以下の通りです。
- ユーザー呼び出しの API の一部処理の非同期化
- 外部 API の呼び出しでレスポンスに時間かかるものがあり、その部分を非同期化したい
- 非同期化した外部 API 呼び出しが失敗したときの自動リトライ
- 外部 API の呼び出しは 500 エラーが返ってくることがあり、その場合に自動的にリトライしたい
最初は社内知見もあったことから Pub/Sub を採用しましたが、前述の要件は Cloud Tasks と Pub/Sub のどちらでも実現可能です。 なお Cloud Tasks と Pub/Sub の違いについては、Cloud Tasks か Pub/Sub かの選択 に詳しく記載されています。
前述のドキュメントを読んで自身の処理の一部を非同期化という要件は明示的な呼び出しに該当するため、本来は Pub/Sub ではなく Cloud Tasks が適しているのでは? と感じたところがきっかけでした。 加えて、Pub/Sub ではあまり考慮できていなかった外部 API に適用されているレート制限やシステムへの負荷も Cloud Tasks の配信レートの管理機能でより適切な管理ができるのではないかと考えました。 実際に Cloud Tasks のユースケース にも「サードパーティ API 呼び出しレートの管理」とあります。
いまより適切な管理ができて、Pub/Sub も Push Subscription であったことから Cloud Tasks に差し替えるコストもあまりかからないと考えました。 そこで検討に至ったのが経緯です。
Cloud Tasks を試しに組み込んでみてわかったこと
ドキュメントを読むと書いてあるものが多いですが、実際に触ってみて採用した場合に私たちのサービス特性や開発チームの体制上、やはり困ることがあるかなと思ったことを挙げます。
レート制限はパラメータ通りには機能しない
Cloud Tasks は、レート制限の定義 で触れられていますが、トークンバケットアルゴリズムに従ったレート制限によりワーカーへの転送量を制限しています。
検証として以下のように設定をした Queue を作成しました。
- 最大レート: 50/s
- 最大同時タスク: 500
- 最大バーストサイズ: 10
トークンバケットアルゴリズムの通りであれば、バケットには最大 10 のトークンが溜められるため同時には最大に 10 のタスクが実行されます。 その後は 50/s の速度でバケットにはトークンが補充されるため、それに補充速度に合わせて最大同時タスク = 500 までタスクが実行されると考えました。 前述のキューに対して、まず 10 タスクを同時にスケジュールなしで投入してみました。
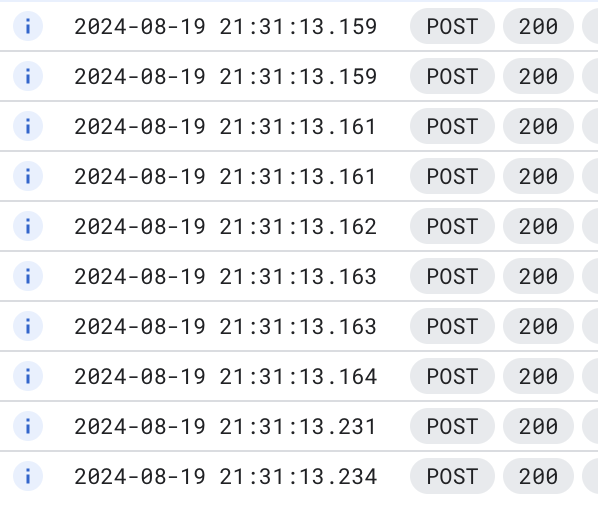
すると結果は想定通り、10 タスクが同時に実行されました。
次に同様に 20 タスクを同時にスケジュールなしで投入してみました。
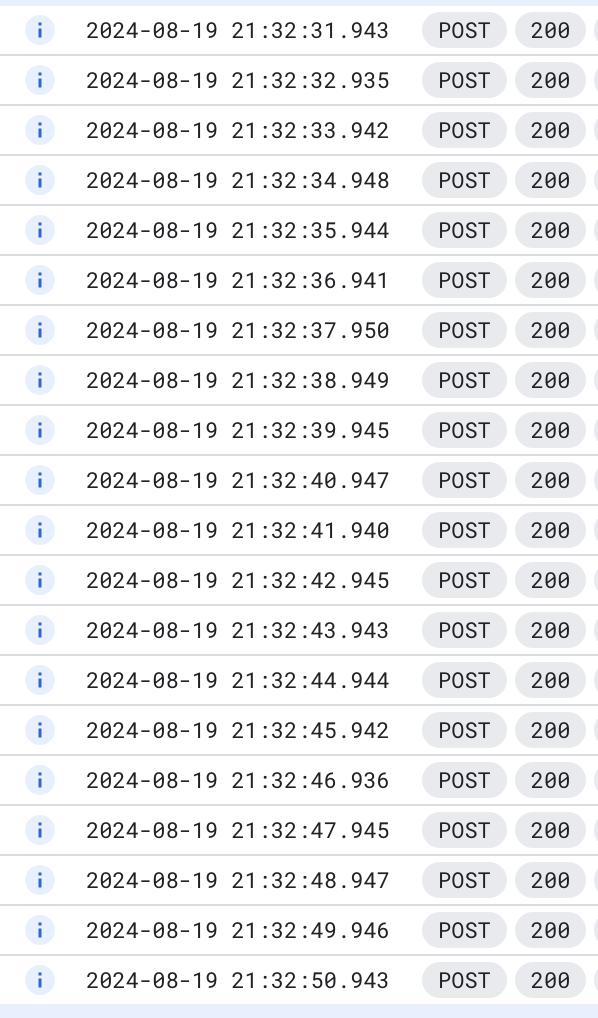
すると結果は 1 秒ごとに 1 つずつタスクが実行される結果になりました。 これは前述のトークンバケットのアルゴリズムから自分が想定していた挙動から異なるものでした。
スケーリングのリスク管理 の冒頭にあるトラフィックパターンに応じて負荷を動的に変更するという記載があります。 ドキュメントから直接な記載を見つけることができませんでしたが、恐らく内部的にスロットリングが行われていると考えています。
実際にワーカーが 429/503 レスポンスを返した場合やエラー率が高いケースでは、スロットリングが行われるようで proto 定義にも記載があるようです。
- https://zenn.dev/castingone_dev/articles/70a9901364c8c0
- https://stackoverflow.com/questions/76884932/cloud-tasks-stops-sending-requests-after-a-certain-number-of-requests-to-a-cloud
このスロットリングの制御により 5XX になったケースですぐにリトライしたいでもすぐにリトライされないためタスクを作り直す、という回避策が取られているようでした...。 スロットリング自体はサービスが過負荷になるのを避けるために必要な制御であるものの、これらの挙動はやや使いづらいと感じてしまいました。
実際に私たちのアーキテクチャで非同期化していた部分は可能な限り即時で実行するのが望ましいというのがありました。 しかし、前述の画像のログのような挙動であることから Cloud Tasks は即時実行したい非同期処理にはあまり向かず、あくまで流入量を制御したり、特定の時間にスケジューリングして実行する目的で利用するのが良さそうという結論になりました。
この挙動が決め手となって Cloud Tasks の採用を見送ることになりました。
タスクは削除される
再試行パラメータの設定 で説明されている通り Cloud Tasks でもタスクの実行が失敗した際にリトライを行うことができます。 しかし、設定した条件までリトライしても成功しなかった場合はタスクは削除されます。
そのため Cloud Tasks はそれそのものをタスク管理として用いるのではなく、タスクのトリガー&リトライ機構として利用するのが良いと考えます。 つまり、より適切にタスク管理をしたい(e.g. 成功しなかったものを保持して確認、必要に応じて再実行する)場合にはタスクの情報や状態を DB で管理する必要があります。 但し、簡易的にリクエストヘッダーに含まれる X-CloudTasks-TaskRetryCount などを参照して、アプリケーション側で条件を満たしていたらタスク内容をどこかに通知・保存するなどの対応は可能であると考えます。
一方でこの観点で Pub/Sub では、リトライしても成功しなかった(= Subscriber から ACK が得られなかった)メッセージを溜めておく Dead-letter Topic があります。 リトライしても成功しなかったメッセージを後から確認し、手動で再送するといったことを手軽に行うことが可能です。 加えて Pub/Sub では シークを使用してメッセージを再生、削除するのように成功・失敗に関わらずにある時点からのメッセージを一括で再送(実質タスクの再実行)が可能です。 これら Pub/Sub の機能は前述の通り、タスクの情報や状態を DB で管理することによって実現は可能かと思いますが、そこにコストをかけずお手軽に実現できる点は魅力であるかと考えています。
タスク実行順序はベストエフォート
これは元々過去に調査した段階で把握していたことで今回の記事の趣旨からはやや外れるのですが、個人的に抑えておくべき特性だと考えたので記載しています。
Cloud Tasks は、キューに登録されたタスクの順序はベスト エフォートで保持されます。 基本的に FIFO で処理されると思われますが、スケジュール時刻が同一のものやリトライが発生した場合などはその順序が保証されません。 よって、短時間に複数の非同期タスクが発行され、その実行順序が重要な場合には別の方法で整合性を取るための仕組みを用意する必要があります。
Pub/Sub では Ordering Key を利用することで順序を保証した配信が可能です。 但し、Ordering Key を指定しない場合と性能などのトレードオフがあったり、考慮すべき事項が増えるため注意が必要です。 こちらの記事に考慮すべき事項がわかりやすくまとまっていますので、興味があれば読んでみるとよいかと思います。
Queue の制約
キューの削除で説明されている通り、一度キューを削除してしまうと同じ名前で 7 日間作成することができません。 Belong では IaC として Terraform を利用しており、開発環境では各開発者が自身の変更内容を apply することがあります。 そのため他の人の apply により開発・検証段階で Queue の削除が発生する可能性があります。 このような開発体制のもとでは、この制約は開発進行のブロッカーになり得るので注意が必要です。
権限周りの設定
どこかにまとまっているかもしれませんが、権限周りの設定が少し分かりづらかったので記載します。
まず Cloud Tasks にタスクを発行するには、タスクを発行するサービスに紐づくサービスアカウントに対して roles/cloudtasks.enqueuer の IAM ロールの付与が必要です。
また、認証付き HTTP タスクを作成する に従って、Cloud Run や Cloud Function に対して OIDC トークンを利用した認証を行うには利用するサービスアカウントに対して、
invoke 権限(Run の場合は roles/run.invoker)と roles/iam.serviceAccountUser のロールの付与が必要です。
あまりわかりやすくないかもしれませんが、図にまとめると以下のように設定する必要があります。
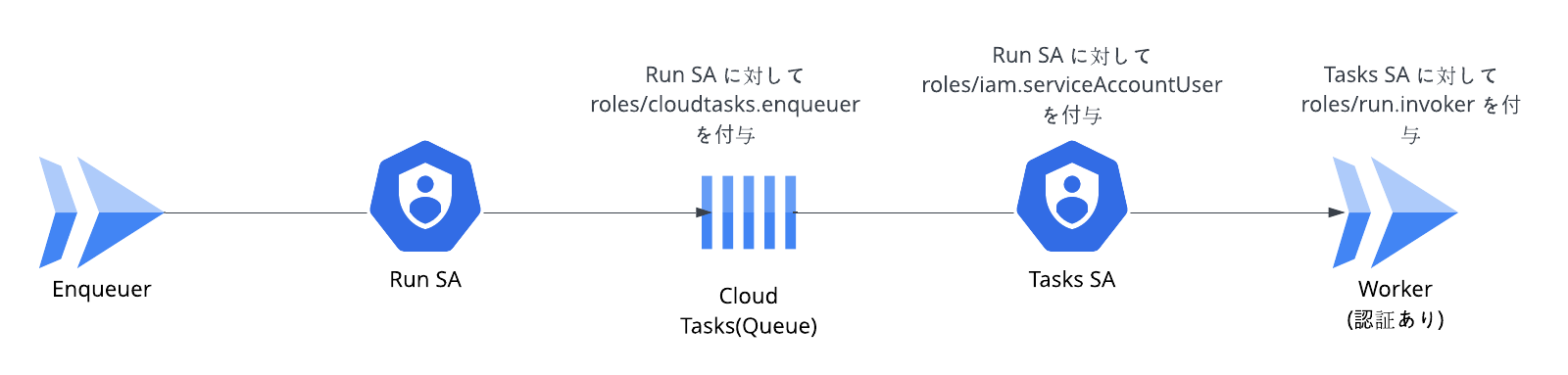
なお、上図ではプロジェクトレベルではなくリソースレベルでの権限付与を想定しています。
IAM Role 付与にはプロジェクトレベルでの付与とリソースレベルの付与があります。
個人的なプラクティスですが、必要でなければ基本リソースレベルでの付与が望ましいと考えます。
例えばサービスアカウントにプロジェクトレベルで roles/run.invoker を付与すると、そのプロジェクト内の任意の Run の呼び出しが行えてしまいます。
リソースレベルでの付与であれば、特定の Run に対してのみ呼び出しが行えるようになります。
具体例として、特定のキューに対してのみあるサービスアカウントがタスクを作成できるようにするためには以下のコマンドを実行します。Terraform の場合は、google_cloud_tasks_queue_iam_member あたりを参照してください。
gcloud tasks queues add-iam-policy-binding $QUEUE \
--project=$PROJECT \
--location=$LOCATION \
--member=serviceAccount:$EMAIL \
--role=roles/cloudtasks.enqueuer
Pub/Sub を採用するときの注意点
ここまでで述べたことの裏返しではあるのですが、Pub/Sub の Push Subscription には明示的なレート制限の指定ができず、 Slow-start アルゴリズムに従って配信を行います。
つまり、ワーカー側が過負荷になって処理できなくなるまで基本的にレートを上げて配信を行います。
多量のアクセスによってシステムが過負荷になる可能性があるなど、流入量に対して慎重になる必要がある場合には Cloud Tasks の利用を検討する必要があるかと思います。 また、イベント駆動アーキテクチャなどを採用しているが前述のような要件を気にする必要がある場合には Buffered Task の利用も検討できます。 Cloud Tasks release notes の通り、少し前の 2024/3/18 に GA になっています。 なお、Buffered Task も通常の Task と同様に上で述べたようなスロットリングのような制御が存在しています。
加えて、Push Subscription には 10 分間のタイムアウトがあるため長時間かかる処理を非同期化したい場合には採用できない可能性があります。 一方 Cloud Tasks では HTTP ターゲットのタスクのタイムアウトは 30 分までとなっており、ある程度の時間の実行を行うことができます。 また、Cloud Tasks 以外にもスケジューリングが固定であれば Cloud Scheduler + Cloud Run (jobs) という組み合わせも検討できるかと思います。
まとめると今回私たちが Pub/Sub のままにできた理由として以下があるということになります。
- 非同期化した処理部分は外部 API 呼び出しのために少し時間がかかるものの負荷の観点では軽量
- 外部 API の呼び出しは数秒から数十秒程度で完了する
- DB へのアクセスも重いクエリではない
- そもそも本来 Pub/Sub のユースケースが想定しているような大規模なメッセージ流入がない
- 現在の利用想定上システムが過負荷になるレベルの流入する可能性が低い
- 実際ある程度スパイクすることはあるが、処理できなくなるほど負荷がかかったケースはない
おわりに
今回は Cloud Tasks の採用を見送った経緯について述べました。
振り返ってみると、ドキュメントの読み込みが甘かったりと反省すべき点があるものの実際に触ってみることで得られる知見は多かったです。
システムの特性などを踏まえて利用するサービスの Pros/Cons やトレードオフを理解することは重要です。 また、例え要件を綺麗に満たした理想のサービス・アーキテクチャがあっても、その時点では過剰であったり、実現にコストがかかり費用対効果が良くなかったりすることもあります。 その時の適切な構成を考えることは、いつやっても難しいと思う反面、学びを得る重要な機会でもあると感じています。
Belong では、課題に対してこれはこうするとよいのではないか? という意見や提案を歓迎しています! もし興味があればぜひ Entrance Book をご覧ください。