BigLake tables for Apache Iceberg in BigQuery の基本的な操作を体験する!
お久しぶりです。株式会社 Belong にて Data Platform チームに所属する Shuhei です。
Belong では BigQuery を用いてデータ分析基盤を構築しています。
今回は、以前から気になっていた BigLake tables for Apache Iceberg in BigQuery について調べてみました。本記事では、Open Table Format について整理しつつ、BigQuery で利用できる BigLake Iceberg テーブルについて、基本的な仕組みと操作方法を解説します。
Open Table Format とはなにか
まずは Open Table Format について簡単に整理しておきましょう。
Open Table Format は、ファイル形式や保存場所に依存せず、データレイク上のデータをテーブルとして扱えるようにするオープンな仕様です。
Open Table Format は大きく下記の 2 点によって構成されています。
- parquet ファイルなどのデータの実態
- テーブルの状態を管理するメタデータ
Open Table Format によって、従来のデータレイクでは困難であった、ACID トランザクションや既存データの柔軟な更新がサポートされるようになりました。
こちらについては次章 Apache Iceberg とはなにか で深堀りしてみます。
Apache Iceberg とはなにか
Open Table Format には、いくつかの実装(具体的な製品)が存在します。その中でも、現在 Google Cloud をはじめとする多くのプラットフォームで採用が進んでいるのが、Apache Iceberg です。
Apache Iceberg は、Netflix が大規模なデータレイクを効率的に管理するために開発したテーブルフォーマットで、スケーラビリティや信頼性に優れ、スナップショット管理や高速なクエリ実行などの機能を備えています。
前章 Open Table Format とはなにか では、テーブルの状態をメタデータとして管理していると説明しました。例えば Apache Iceberg では、以下のようなメタデータファイルがツリー構造となって存在します:
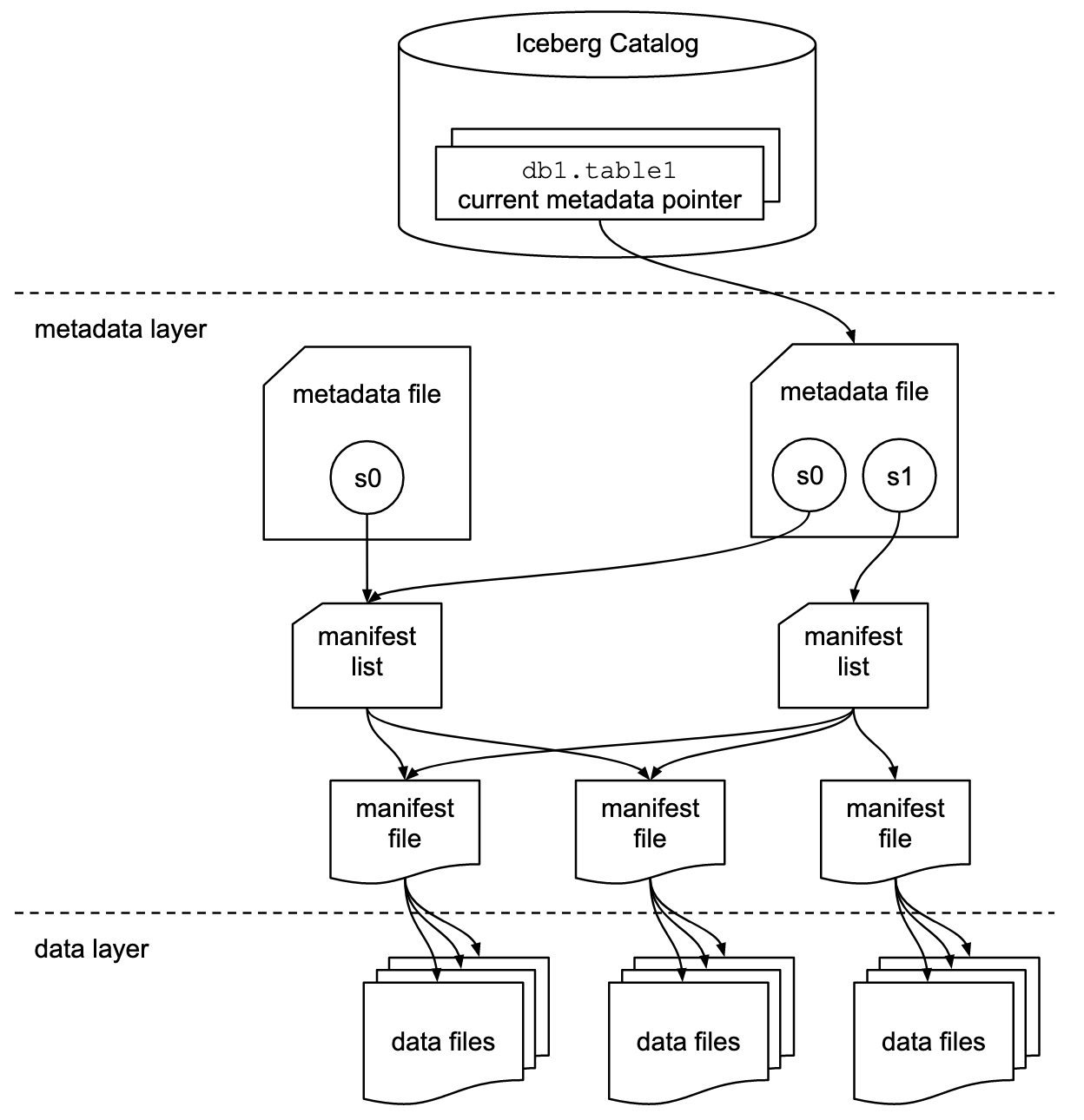 出典:https://iceberg.apache.org/spec/#overview
出典:https://iceberg.apache.org/spec/#overview
- catalog
- 最新の metadata file への参照を保持する
- metadata file
- 各時点のテーブルの状態 (スナップショット、スキーマ、パーティショニング等) を記録する
- データの変更時には、古いスナップショットファイルを書き換えるのではなく、新たなファイルとして記録される
- manifest list
- スナップショットと manifest file の対応を示す
- manifest file
- データの実体 (data files) の位置情報を示す
Apache Iceberg は以上のような仕組みを用いて、様々な機能を実現しています。代表的な特徴として下記が挙げられます。
- スキーマ進化 (Schema Evolution)
- スキーマの変更履歴をメタデータとして保持するため、スキーマを変更してもデータが壊れない
- パーティショニング (Hidden Partitioning)
- Hive Partitioning における dt=yyyy-mm-dd のような物理的なパーティションのカラム・フォルダ構造を意識することなくクエリできる
- タイムトラベル (Time Travel)
- テーブルの更新時に古いデータを削除することなく保持されるため、過去のある時点のデータにクエリすることができる
- ACID トランザクション (ACID Transactions)
Apache Icebergの持つメタデータ管理等の仕組みと、それを理解するクエリエンジンの連携により ACID を支える- Atomicity, Consistency
- データに変更があったときは、新たなメタデータファイルを作成し、最新の参照を古いものから新しいものに atomic に切り替える
- Isolation
- Optimistic Concurrency による同時実行制御
- Durability
- Time Travel 機能
BigLake tables for Apache Iceberg in BigQuery とはなにか
BigLake tables for Apache Iceberg in BigQuery により、Open Table Format の Apache Iceberg 形式で Google Cloud 上でデータレイクハウスが構築できるようになります。
Cloud Storage 上に存在する Apache Iceberg 形式のデータを、 BigQuery のテーブルのように、読み書き、更新、削除など柔軟な操作をすることが可能です。
アーキテクチャ
特に「ストレージ層」と「コンピュート層」に焦点を当て、簡単にアーキテクチャを整理していきます。
 出典:https://cloud.google.com/bigquery/docs/iceberg-tables
出典:https://cloud.google.com/bigquery/docs/iceberg-tables
ストレージ層
アーキテクチャの土台となるのがストレージ層になります。BigLake tables for Apache Iceberg in BigQuery ではデータの永続的な保管場所として Cloud Storage が使用されます。
- Open Data
- テーブルの実態となるデータは保持されます。parquet のようなオープンなファイル形式が使用されます。
- Open Metadata
- テーブル構造やパーティション情報、各時点でのテーブルのスナップショットなどのメタデータが格納されます。
ここで重要なのは、データの実体はあくまでもオープンなフォーマットで Cloud Storage に存在するということです。特定のデータベース製品に縛られたプロプライエタリなデータではないということです。
コンピュート層
データを加工・分析するために機能するのがコンピュート層です。BigLake tables for Apache Iceberg in BigQuery ではコンピュート層を用途によって選択可能となります。
- Google Cloud のリソース
- BigQuery
- Vertex AI
- Open-source なエンジン
- Apache Spark
- Trino
- ... etc
例えば、複雑な集計やアドホックな分析であれば BigQuery を、機械学習モデルと組み合わせたいなら Vertex AI を、大規模なバッチ処理をしたいなら Spark などと自由にリソースを選択することができます。
このような組み換え可能な柔軟性は、将来新たな最適なエンジンが誕生した場合もそれを採用しやすく、非常に強力な特徴と感じました。もちろん、エンジンによっては Iceberg の機能をすべて実現できるわけではなく、サポートされていない機能もあるため、その点は留意が必要ですね。
BigLake tables for Apache Iceberg in BigQuery の基本的な操作を学ぶ
それでは BigLake tables for Apache Iceberg in BigQuery の基本的な操作を体感してみましょう!
以降の操作は事前準備として下記を実施しているものとします。公式ドキュメントに詳細が記載されていますのでご覧ください。
- Cloud resource connection の作成
- 必要なロールの付与
加えて、事前にテスト用のデータを作成しました。
- データソースとなる parquet ファイルの GCS へのアップロード
- テスト用に
order_id,order_date,product,amountの列を持つ注文データを作成しました
- テスト用に
BigLake Iceberg table の作成
まずは BigLake Iceberg table を作成してみましょう。
CREATE OR REPLACE TABLE `test-project.test-dataset.test_iceberg_table` (
order_id INT64,
order_date DATE,
product STRING,
amount INT64
)
WITH CONNECTION `test-connection-name`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://test-bucket/test_iceberg_table/'
);
上記の SQL を実行することで Apache Iceberg 構成用の BigQuery テーブル が作成されます。
この時点ではテーブルは空です。
BigLake Iceberg table へ Data を Import
次に、Apache Iceberg 構成用の BigQuery テーブル にデータを Import してみましょう。
※ あらかじめ gs://test-bucket/source/test_iceberg_table 配下にソースとなる parquet ファイルをアップロードしています。
LOAD DATA INTO `test-project.test-dataset.test_iceberg_table`
FROM FILES (
uris=['gs://test-bucket/source/test_iceberg_table/source_data.parquet'],
format='PARQUET'
);
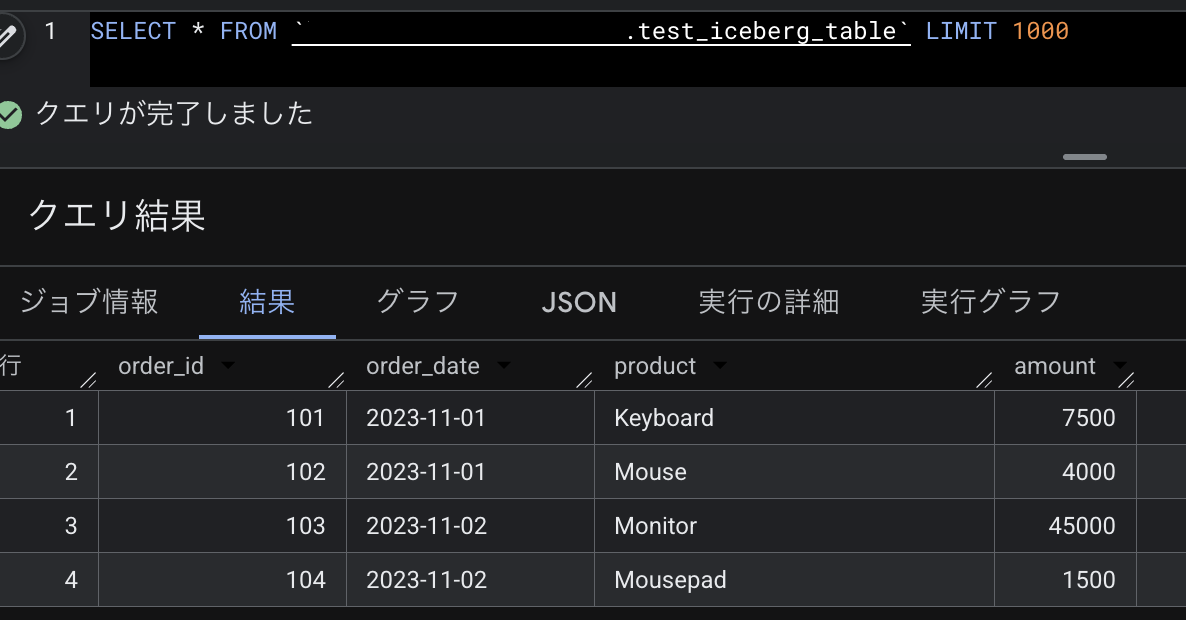
作成したテーブル test-project.test-dataset.test_iceberg_table に対してクエリしてみると、データが参照できるようになっていました。
また、Cloud Storage の gs://test-bucket/test_iceberg_table/data に parquet ファイルが作成されていることが確認できます。
$ gcloud storage ls gs://{bucket_name}/test_iceberg_table/data
gs://{bucket_name}/test_iceberg_table/data/87485d55-9a47-434c-827a-85dad874fee0-b18bee5d7124e1e5-f-00000-of-00001.parquet
LOAD DATA クエリにより、データの実体が gs://test-bucket/test_iceberg_table/data 配下に配置されることがわかりました。
BigLake Iceberg table の Schema を変更
続いて、スキーマの変更を試してみます。テーブルに新しい列を追加し、異なるスキーマのデータをロードした場合の挙動を確認します。
列の追加
まず、テーブルに列を追加します。
ALTER TABLE `test-project.test-dataset.test_iceberg_table`
ADD COLUMN new_column STRING;
列追加したソースデータを用意し、GCS にアップロードしておきます。そのファイルを LOAD DATA します。
LOAD DATA INTO `test-project.test-dataset.test_iceberg_table`
FROM FILES (
uris=['gs://test-bucket/source/test_iceberg_table/source_data_2.parquet'],
format='PARQUET'
);
テーブルを SELECT してみると列追加前のデータと列追加後のデータを両方取得できることを確認しました。
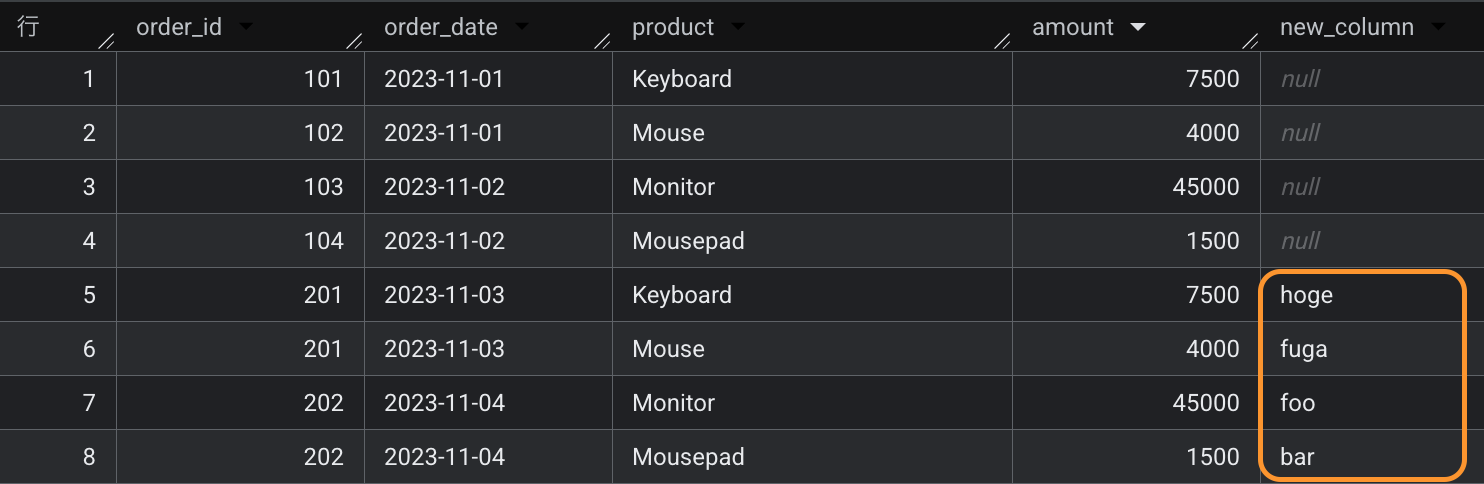
これは、同じくデータの実体が Cloud Storage に存在する従来の外部テーブルとは異なる特徴です。外部テーブルは定義済のスキーマを満たさないファイルが配置されれば、そのテーブルにはクエリできなくなり、テーブルが壊れてしまいます。
例:
Error while reading table: [table_name], error message: CSV processing encountered too many errors, giving up. Rows: 5; errors: 4; max bad: 0; error percent: 0
列名の削除
続いて、列の削除に対してはどのように挙動するでしょうか。
ALTER TABLE `test-project.test-dataset.test_iceberg_table`
DROP COLUMN new_column;
テーブルを SELECT してみると (もちろん new_column 以外のカラムにはなりますが) 列削除前のデータと列削除後のデータを参照することができました。
おわりに
今回 BigLake tables for Apache Iceberg in BigQuery の基本的な操作を体験してみました。
データレイクおよびデータウェアハウスを取り巻く基本的な知識を振り返りながら体験することで、この技術がデータ分析基盤にどのような価値をもたらすのか、いくらかイメージできたのかなと感じています。
2025 年 6 月本稿執筆時点では BigLake tables for Apache Iceberg in BigQuery は Preview の機能ではありますが、従来の BigQuery に実装されているタイムトラベル機能やカラムレベルセキュリティなどもサポートされているようです。今回は試すことができなかった機能もまたの機会に試したいと思いますし、今後のアップデートでどのように進化していくのかも楽しみです。
また、個人的には Schema Evolution の機能には特に魅力を感じました。最近、業務おいてファイルベースでデータ連携を行う機会が何度かありましたが、スキーマ変更への対応には難しさを感じていました。今回のテーマはもしかしたらヒントになるかもしれません。今回の執筆を通して学んだことを、うまく業務にも取り入れられないか模索していきたいと思います。
Belong ではこのように BigQuery を用いた DWH の構築を積極的に実施しています!Data Platform チームに興味を持っていただけた方は是非 Entrancebook をご覧ください!