dbt incremental model の挙動について調べてみました
こんにちは。株式会社 Belong の DataPlatform チームに所属する Shuhei です。 Belong に入社して 3 ヶ月が経ちました。毎日が風のように走っていきます。日々学びを噛み締めています。
Belong の DataPlatform チームでは、dbt-core を用いて、BigQuery 上にあるデータ分析基盤を構築しています。現在、私は絶賛 dbt お勉強中です 💪
先日、dbt の incremental model にふれる機会があり、とてもおもしろい機能だなと思う反面、難しさも感じました。今回の記事は、自分の学びを深めるためにも、そんな incremental model について記していきます。
incremental model とは
incremental model とは、dbt の materializaitons のうちの 1 つです。incremental model の特徴は、既存のデータを再計算するのではなく、新しいデータや変更されたデータのみを追加・更新する点にあります。
| Materialization | 説明 |
|---|---|
table | データベースにデータが保存されず、その都度クエリを実行します。 |
view | データを物理的にテーブルとして保存します。 |
ephemeral | 中間テーブルなどの用途として一時的に使用されるテーブルで、テーブルとして保存されません。 |
materialized view | SQL の実行結果を保存しておき、結果に差分があるときには差分のみを読み込む |
incremental | 新しいデータや変更されたデータのみを追加・更新します。 |
incremental model には、次のメリットがあります。
- パフォーマンスの向上
- 新しいデータや変更されたデータのみを処理するため、クエリの実行時間が短縮されます。
- コスト削減
- 処理対象を最小限にすることで、データウェアハウスの使用コストを抑えることができます。
一方で、公式ドキュメントからは、view, table, incremental model の順に複雑性が増していくような印象を受けました。view, table, incremental model のそれぞれの特徴を踏まえたうえで、materialization を選択したいものです。
We’ll explore this in-depth throughout, but the basic guideline is start as simple as possible. We’ll follow a tiered approached, only moving up a tier when it’s necessary.
🔍 Start with a view. When the view gets too long to query for end users,
⚒️ Make it a table. When the table gets too long to build in your dbt Jobs,
📚 Build it incrementally. That is, layer the data on in chunks as it comes in. ※ 引用:https://docs.getdbt.com/best-practices/materializations/1-guide-overview#guiding-principle
このように、incremental model はいい感じの挙動をしてくれそう!と思う一方で、用法の難易度は高そうだなと思いました。
incremental model を configurations から理解してみる
どのようなところに難しさがあるのか、実際に体感してみるために incremental model を触ってみました。公式ドキュメントを読みながら、いくつかの configurations を通して、少しずつ理解してみます。
incremental model の挙動の特徴は、初回実行では create table、 2 回目以降の実行では merge を実行する点にもあると思います。そのそれぞれにも注目していきながら、挙動を確認していきます。
is_incremental() macro
まず、 is_incremental() を使用することで、どのレコードを増分対象にするかフィルタする ことができます。
is_incremental() は True, False を返す macro です。基本的には incremental model の初回実行では False となり、それ以降の実行時は True となります。
次に is_incremental() を使用する場合と、使用しない場合の例を見ていきましょう。
今回は、下記のような簡単な incremental model を作成してみることを考えてみます。ソースとなるテーブルとして、id, name, address, created_at, updated_atのカラムをもつテーブルを作成し、50 件ほどのテストデータを用意してみました。
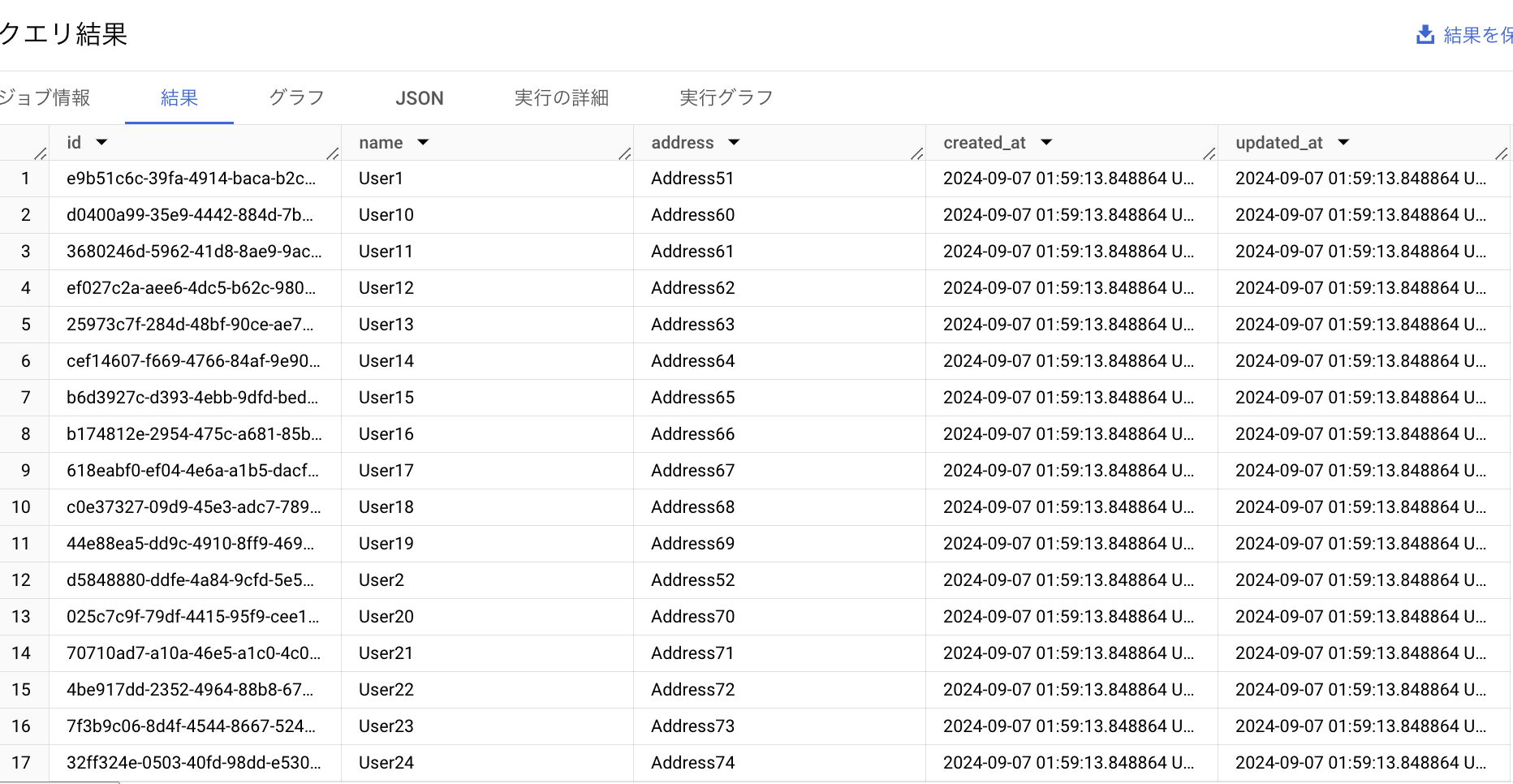
is_incremental() を使用しないとき
is_incremental() を使用しない例として、下記のようなクエリを用意しました。
{{
config(
materialized = 'incremental'
)
}}
select
id,
name,
address,
created_at,
updated_at
from [ source table name ]
この状態で dbt run すると 、下記のようなクエリにコンパイルされ実行されます。
初回実行時
select 文の結果を保持するテーブルを作成する create table 文が生成され、実行されます。
CREATE OR REPLACE TABLE
[ incremental model name ] OPTIONS() AS (
SELECT
id,
name,
address,
created_at,
updated_at
FROM
[ source table name] );
2 回目以降の実行時
MERGE 文が生成され、実行されます。少し中身を見てみましょう。
DBT_INTERNAL_SOURCE のデータを DBT_INTERNAL_DEST に merge し、マッチしないレコードを insert していることがわかります。
一方で on 句には FALSE という条件が指定されているため、実際にはマッチング条件が存在せず、すべての行が新規行として扱われることを意味します。
MERGE INTO
[ incremental model name ] AS DBT_INTERNAL_DEST
USING
(
SELECT
id,
name,
address,
created_at,
updated_at
FROM
[ source table name ] ) AS DBT_INTERNAL_SOURCE
ON
(FALSE)
WHEN NOT MATCHED
THEN
INSERT
(`id`,
`name`,
`address`,
`created_at`,
`updated_at`)
VALUES
(`id`, `name`, `address`, `created_at`, `updated_at`)
このクエリを実行したとき、作成した incremental model においては重複が発生してしまいました。
select
name,
count(*) as cnt
from [ incremental model name ]
group by id, name, address, created_at, updated_at
having cnt >= 2
order by name
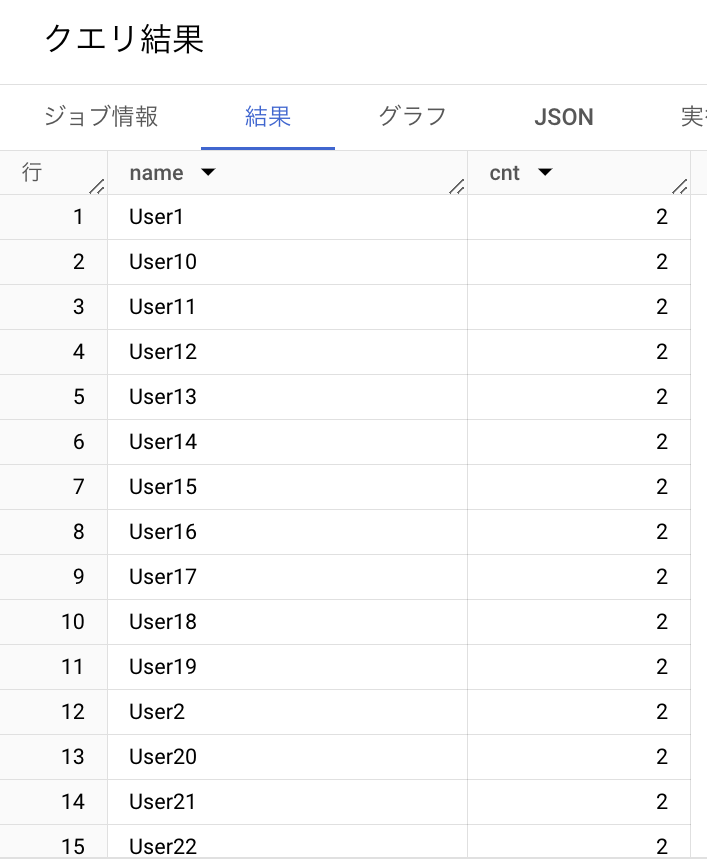
これではやや使いづらいと感じてしまうかもしれません。なにか増分対象を制御する方法があればよいのですが...
is_incremental() を使用するとき
それでは、is_incremental() macro を使用してみましょう!
is_incremental() を使用する例として、下記のような SQL を用意しました。
{{
config(
materialized = 'incremental'
)
}}
select
id,
name,
address,
created_at,
updated_at
from [ source table name ]
{% if is_incremental() %}
where updated_at > (select max(updated_at) from {{ this }} )
{% endif %}
where 句の部分で is_incremental() を用いています。True となるときには、this (現在の incremental model) の updated_at よりも新しい updated_at のみを select するように、レコードを絞り込んでいます。
この状態で dbt run すると 、下記のようなクエリにコンパイルされ実行されます。
初回実行時
select 文の結果を保持するテーブルを作成する create table 文が生成され、実行されます。これは is_incremental() を使用しないときと同様ですね。
CREATE OR REPLACE TABLE
[ incremental model name ] OPTIONS() AS (
SELECT
id,
name,
address,
created_at,
updated_at
FROM
[ source table name] );
2 回目の実行時
is_incremental() を使用しないときと比較すると、where 句の部分で差異があります。is_incremental() が True となり、where 句が効いていることがわかりました。
MERGE INTO
[ incremental model name ] AS DBT_INTERNAL_DEST
USING
(
SELECT
id,
name,
address,
created_at,
updated_at
FROM
[ source table name ]
WHERE
updated_at > (
SELECT
MAX(updated_at)
FROM
[ incremental model name ] ) ) AS DBT_INTERNAL_SOURCE
ON
(FALSE)
WHEN NOT MATCHED
THEN
INSERT
(`id`,
`name`,
`address`,
`created_at`,
`updated_at`)
VALUES
(`id`, `name`, `address`, `created_at`, `updated_at`)
この where 句のおかげで、現在の updated_at よりも新しい updated_at を持つレコードのみが insert されます。
したがって、is_incremental() を使用しないときに見られた、レコードの重複は見られません。
select
name,
count(*) as cnt
from [ incremental model name ]
group by id, name, address, created_at, updated_at
having cnt >= 2
order by name
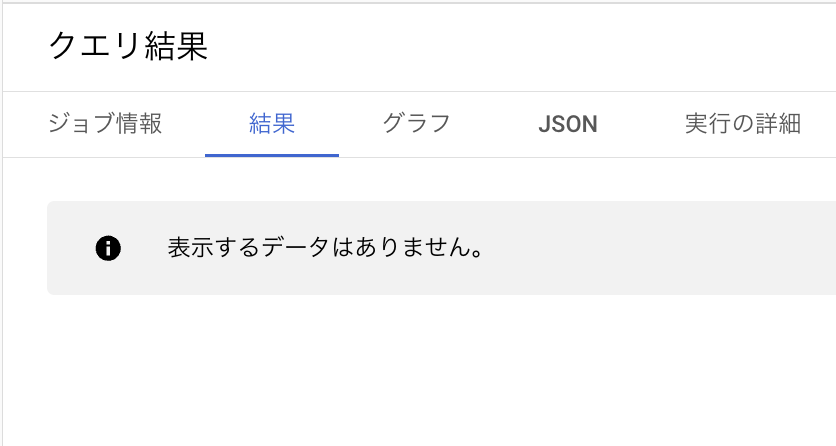
つまり、is_incremental() を使用することで、ソーステーブルのどのレコードを増分とするかをフィルタすることができ、適切な増分更新を実現することができそうです!
unique key
unique key を指定することで、増分のデータを insert するか、update するかを制御することができます。
incremental model のデフォルトの設定では、増分のデータは insert されます。しかし、新規のレコードは insert を、更新されたレコードは update をしたいケースもきっとあることでしょう。
今回は下記のシナリオを考えてみます。
シナリオ: ユーザー名 "User1" を "UserX" に変更
1. 初期状態:
- レコード:
User1, 過去時刻のupdated_at2. 更新後:
- レコード:
UserX, 現在時刻のupdated_at
では、このようにユーザー名が変更になったケースを想定して、name が User1 のレコードについて、name を UserX に、updated_at を現在時刻のタイムスタンプに更新してみます。下記の SQL を実行して準備を整えます。
update [ source table name ] set name = 'UserX', updated_at = current_timestamp where name = 'User1'
unique key を指定しないとき
それではまず、unique key を指定しないケースを考えてみます。
前述の例で用いた SQL をベースに考えてみましょう。
{{
config(
materialized = 'incremental'
)
}}
select
id,
name,
address,
created_at,
updated_at
from [ source table name ]
{% if is_incremental() %}
where updated_at > (select max(updated_at) from {{ this }} )
{% endif %}
この状態で dbt run してみます。 SQL は前述の例と同じなので、実行されるクエリの詳細は割愛し、結果にのみ注目してみます。

この結果の図から、同一 id で重複が発生していることがわかります。name, updated_at を更新したレコードが増分データとして insert されるといった挙動ですね。
unique key を指定しないとき
それでは、unique key を指定して、どのように挙動がかわるか見ていきましょう。
このような SQL としてみました。unique key として id を指定しています。
{{
config(
materialized = 'incremental'
unique_key = 'id'
)
}}
select
id,
name,
address,
created_at,
updated_at
from {{ source('ext', 'src_user_address') }}
{% if is_incremental() %}
where updated_at > (select max(updated_at) from {{ this }} )
{% endif %}
この状態で dbt run すると、下記のようなクエリにコンパイルされ実行されます。
MERGE INTO
[ incremental model name ] AS DBT_INTERNAL_DEST
USING
(
SELECT
id,
name,
address,
created_at,
updated_at
FROM
[ source table name ]
WHERE
updated_at > (
SELECT
MAX(updated_at)
FROM
[ incremental model name ] ) ) AS DBT_INTERNAL_SOURCE
ON
( DBT_INTERNAL_SOURCE.id = DBT_INTERNAL_DEST.id )
WHEN MATCHED THEN UPDATE SET `id` = DBT_INTERNAL_SOURCE.`id`, `name` = DBT_INTERNAL_SOURCE.`name`, `address` = DBT_INTERNAL_SOURCE.`address`, `created_at` = DBT_INTERNAL_SOURCE.`created_at`, `updated_at` = DBT_INTERNAL_SOURCE.`updated_at`
WHEN NOT MATCHED
THEN
INSERT
(`id`,
`name`,
`address`,
`created_at`,
`updated_at`)
VALUES
(`id`, `name`, `address`, `created_at`, `updated_at`)
unique_key を指定しないときのクエリでは、 on 句に FALSE という条件が指定されているため、実際にはマッチング条件が存在せず、すべての行が新規行として扱われていました。
その一方で、unique_key = id を指定すると、on 句に DBT_INTERNAL_SOURCE.id = DBT_INTERNAL_DEST.id という条件が指定されました。ソースとなるデータとターゲットとなるデータの id が一致するとき、update されるようになっています!
実際のデータも見てみましょう。

この結果の図から、name が User1 から userX に更新されており、同一 id で重複する行は存在していないことがわかりました。unique_key を指定したことにより、増分データが insert ではなく update されました!
まとめ
以上、is_incremental() と unique_key の configurations を通して、incremental model について知ることができました。とりあえず materializations を incremental model にすれば増分データの更新が気軽にできる、というよりは configuration を適切に指定しないと全く使えないデータにもなりかねない難しさが印象的でした。
特に、unique_key の指定にあたっては、ソースデータ側にも unique であることを保証するための dbt test を追加するなどの工夫が必要そうだなと思いました。
今回紹介した configurations の他に、例えば strategy という重要な configrations もありますが、これはまた今度触れてみます!
Belong ではこのように dbt を用いた DWH の構築を積極的に実施しています!dbt がお好きな方、少しでも気になるよというははぜひ Belong Entrance Book for Engineer をご覧ください!