AI Agent とは何か - Agent と Workflow の構成要素
Overview
2025 年は AI エージェント元年と言われています。
特にエンジニアの場合、これまでは生成 AI とのチャットでプログラムを生成していたり、 GitHub Copilot などでコードを補完してもらうことが多かったと思いますが、 今年はコーディングエージェントが盛り上がっており、複数の種類にも触れ、日常的に AI エージェントを利用する機会が増えてきました。
本記事では、Kaggle のホワイトペーパー、Anthropic の Building effective agents を参考にしつつ、 「そもそも AI Agent ってなんだっけ」という部分を言語化しつつ、 AI エージェントの構成要素、Agent タイプと Workflow タイプについて整理していきます。
AI Agent とは
AI エージェントとは、自律的に行動し、人間からの明確な指示がなくても特定の目標を達成するために独立して行動できるアプリケーションとされています。
従来のプログラムが事前に定義された命令に従って動作するのに対し、AI エージェントは、周囲の環境を認識し、その情報に基づいて意思決定を行い、行動できます。 これは、単に事前に設定されたルールに従うだけでなく、自ら学習し、経験を積むことで、より効率的に目標を達成できるようになる可能性を秘めていることを意味します。
たとえば、「来週末、景色の良い温泉宿に泊まりたいんだけど、予算はこれくらいで、2 名で予約してほしい」と AI 旅行エージェントに伝えたとします。
AI エージェントは、まずユーザーの好み(予算、場所の希望、過去の旅行履歴など)や現在の状況(日付、人数など)を認識します。
そして、その情報に基づいて複数の宿泊施設や交通手段の選択肢を自律的に検索・比較検討します。
さらに、空室状況、リアルタイムの交通情報、天気予報といった外部環境の変化も把握し、最適な旅行プランを意思決定します。
そして、いくつかのプランを提案するだけでなく、もしユーザーが特定のプランを選べば、その承認を得て実際に宿泊施設や交通機関の予約手続きまで行動し、
予約完了の確認通知を送るといった一連のタスクを完遂します。
この一連のプロセスの中で、もし最初の提案が希望と完全に合致しなかった場合、そのフィードバック(例:「もう少し静かな場所がいいな」)から学習し、
次の提案を改善するといった経験を積むことも可能です。
このように、AI エージェントは単なる情報提供に留まらず、目標達成に向けて能動的に動き、環境と対話しながらタスクを実行する能力を持っています。
AI エージェントの構成要素
AI エージェントが自律的に機能するためには、いくつかの重要な構成要素が必要です。 ここでは主要な 3 つの要素、「モデル」「ツール」「オーケストレーションレイヤー」について見ていきましょう。
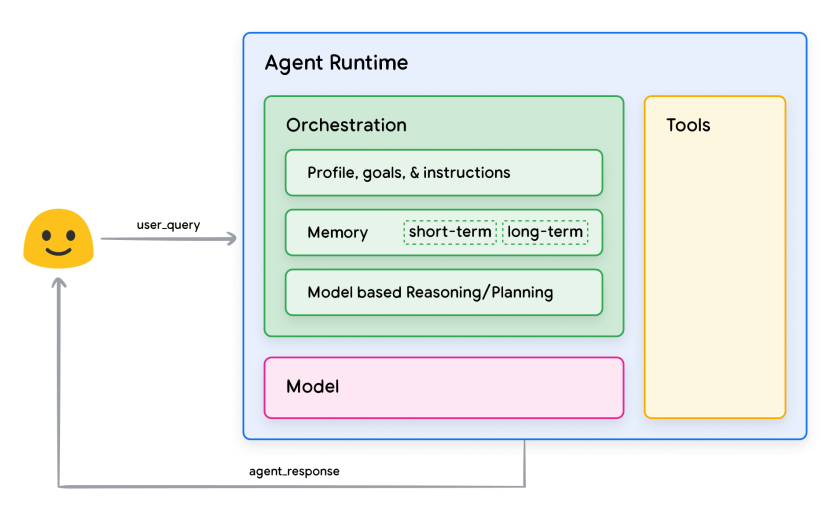
引用: Agents Whitepaper, Kaggle: Figure 1. General agent architecture and components
モデル
「モデル」とは、主に言語モデル (LM) のことを指します。 AI エージェントの頭脳に相当し、情報の処理、理解、そして意思決定の中心的な役割を担います。
人間が言葉を理解し思考するように、モデルは大量のテキストデータで学習し、自然言語による指示や情報を解釈します。 行いたいタスクに適したモデル(例えば、文章生成が得意なモデル、特定の専門知識を持つモデルなど)を選択し、 そのモデルに対して適切な指示(プロンプト)を与えることで、AI エージェントは目標達成に向けて動き出します。
そのため、エージェントが利用するモデルは 1 つの場合もあれば、タスクの複雑性や目的に応じて、複数の異なる種類のモデルを組み合わせて利用することもあります。
ツール
「ツール」は、AI エージェントが外部のデータやサービスと連携できるようにするための手段です。 モデル自体は、学習データに含まれない最新の情報や、プライベートなデータベース、外部システムの機能に直接アクセスすることはできません。 ツールは、このモデルの能力と外部世界との間のギャップを埋めるために不可欠です。
例えば、次のようなものがツールの役割として挙げられます。
- データベースへのアクセス(顧客情報の検索など)
- API の呼び出し(天気予報の取得、カレンダーへの予定登録など)
- インターネット検索(最新ニュースの収集など)
- ファイルの読み書き
最近注目されている Model Context Protocol (MCP) のような仕組みも、 モデルが外部ツールと効果的に連携するための標準化されたインターフェースを提供するものであり、広義にはツールの一つと考えることができます。
エージェントにおいてツールを利用する場合、AI(モデル)がそのツールをいつ、どのように利用するのが適切なのかを理解する必要があります。 これには、ツールの機能、必要な入力、期待される出力などをモデルに正しく伝えるプロンプトエンジニアリングが重要になります。
AI エージェントが利用できるツールには、主に「エクステンション」「ファンクション」といった種類があります。
エクステンション
エクステンションは、標準化された方法で、外部の API と連携するためのツールです。これにより、エージェントは外部システムが提供する機能を活用できます。
具体例:
-
Google カレンダー API との連携(予定の確認・登録)
-
Slack API との連携(メッセージの送信・チャンネル情報の取得)
-
Salesforce API との連携(顧客データの参照・更新)
-
これらのエクステンションを利用することで、エージェントは外部からの情報取得、データの更新、通知の送信といったアクションを実行できます。
ただし、標準化された API ベースのエクステンションを利用する際には注意が必要です。 自然言語による曖昧な問い合わせをモデルの解釈のみに依存して API 呼び出しを行うと、意図しないパラメータで API が実行されたり、エラーが発生したりと、不安定な挙動になりがちです。 そのため、API をどのように使うのか(エンドポイント、メソッド)、API 呼び出しに必要な項目は何か、エラーが発生した場合はどのように処理するかなどを、 具体的な例を交えつつ事前にエージェントに教え込み、設定しておく必要があります。
ファンクション
ファンクションは、特定のタスクを実行するためのプログラムです。 ソフトウェア開発の世界では、特定のタスクを実行するための再利用可能なコードのまとまりをファンクション(関数)と呼びますが、AI エージェントにおいても同様の意味で使われます。
重要な点として、ここで言うファンクションは、(エクステンションとは異なり)直接的な外部 API 呼び出しをエージェント自身が行わないものを想定しています。
ファンクションを利用することで、API エンドポイントを呼び出すための詳細なロジックや実際の実行処理をエージェントのコア機能から切り離し、 アプリケーション全体のデータフローをより細かく開発者が制御できるようになります。
次のような場合にファンクションが有効です。
- 認証処理の分離: API 呼び出しに OAuth 認証のような複雑な認証が必要な場合、認証情報の取得や管理はクライアント側のアプリケーションで行い、エージェントは認証済みトークンを利用する、あるいは API 呼び出しに必要な情報をファンクションで整形するだけに留める。
- レスポンスデータの整形・絞り込み: API からのレスポンスデータが大量であったり、エージェントが必要とする形式と異なる場合、ファンクションを使って必要な情報だけを抽出・変換してからエージェントに渡す。
- 計算処理やデータ変換: メールアドレスの形式チェック、数値計算、特定のフォーマットへのデータ変換など。
ファンクションはエージェントの内部処理をシンプルに保ちつつ、より安全で堅牢なシステム連携を実現するのに役立ちます。 たとえば、Google の OAuth 認証を利用するケースを考えると、
- 認証情報の取得といったセキュリティに関わる部分はクライアント側で実行
- API 呼び出しに必要なリクエストパラメータの整形などをエージェントとファンクションが協力して実行
- 最終的な API 呼び出しはクライアント側が実行
という流れが考えられます。
オーケストレーションレイヤー
オーケストレーションレイヤーは、AI エージェント全体の動作を統括する、文字通り「指揮者」のような役割を果たします。 エージェントが情報をどのように取り込み、内部で推論を行い、その結果に基づいて次の行動や意思決定をどのように導き出すか、という循環的なプロセスを規定し、管理します。
この過程で、オーケストレーションレイヤーはユーザーからの指示を解釈し、タスク達成のために最適な「モデル」を選択し、 必要な「ツール」を適切なタイミングで連携させ、一連のタスクを実行していきます。
オーケストレーションレイヤーには、主に以下の要素を管理することが期待されます。
Reasoning and Planning
Reasoning (推論) と Planning (計画) は、エージェントが賢く振る舞うための中心的な機能であり、 「Prompt Engineering」のテクニックにより実現されます。
計画の過程では、LLM に対して段階的な指示を与えつつ、次のようなことを行います。
- 推論を行いつつタスクの分解: 大きな目標を達成可能な小さなサブタスクに分割
- これまでの情報や実行タスクに対する考察 (Reflection): 過去の行動とその結果を評価し、学びを得る
- 将来の意思決定を改善するための適応学習: 考察に基づいて、今後の行動計画を修正
- これまでの結果に対する批判的分析: 計画通りに進んでいるか、問題はないかを客観的に評価
Chain-of-Thought (CoT)
CoT は、Wei et al. (2022) で紹介された手法で、複雑な問題に対して、 モデルに中間的な思考のステップを明示的に生成させることで、最終的な回答の質を向上させます。 たとえば、「A と B の違いは何か」という問いに対し、いきなり結論を出すのではなく、「まず A の特徴を列挙し、次に B の特徴を列挙し、それらを比較することで違いを明確にする」といった思考の連鎖を促します。 これはチャット形式のインターフェースでもユーザー自身が活用しやすいテクニックです。
ReAct
ReAct は、Yao et al. (2022) で紹介された手法で、Reasoning (推論) と Acting (行動) を組み合わせ、反復的にタスクを遂行します。 現在の状況を分析し(Reason)、その分析結果に基づいて具体的な行動(Act)を起こし、行動の結果(Observation)を観測し、再び次の推論を行う、というサイクルを繰り返します。
- タスクを達成するために必要な行動 (Act) とその理由 (Reason) を推論します。
- 行動を実行し、その結果を観測します。
- 得られた結果(観測)から、再度次に必要な行動とその理由を推論します。
- 最終的な答えが生成できるまで上記を繰り返す。
たとえば、「近所でマグロを釣る方法を教えて」という指示を与えられた場合、ReAct は以下のような流れで処理を進めることが考えられます。
- 推論(Reasoning): 「マグロが釣れる場所」と「マグロの釣り方」の情報が必要だと判断する。
- 行動(Action): 地図情報 API(ツール)を使って近所の釣り場情報を検索する。
- 観測(Observation): 釣り場情報 A、B、C が見つかった。
- 推論(Reasoning): 次に「マグロの釣り方」を調べる必要がある。また、釣り場情報の中から最も近い場所を特定する必要がある。
- 行動(Action): Web 検索(ツール)で「マグロ 釣り方」を調べる。
- 観測(Observation): マグロの釣り方に関する情報 D が得られた。
- 推論(Reasoning): 釣り場情報 A が最も近い。情報 D と釣り場 A を組み合わせて回答を生成する。
- 行動(Action): 「近所の釣り場 A で、情報 D の方法でマグロを釣ることができます」と回答する。
Tree-of-thoughts (ToT)
ToT は Yao et al. (2023) で紹介された手法で、CoT をさらに発展させたものです。 CoT が一本の思考の鎖を辿るのに対し、ToT は推論の過程を木構造で表現し、複数の可能性(思考の分岐)を同時に検討します。 探索的なタスクや戦略的な先読みが必要なタスクに非常に適しており、複数の選択肢を評価し、最も有望な思考のパスを選択することで、より質の高い結論を導き出すことを目指します。
Memory (記憶)
Memory は、エージェントが過去の情報を保持し、それを将来の意思決定や対話に活用するための仕組みです。 人間が短期的な記憶と長期的な記憶を持つのと同様に、エージェントの記憶も主に 2 つの形式で考えられます。
-
短期作業記憶 (Short-term Working Memory)
- 現在の対話やタスク処理中のコンテキスト情報(ユーザーの直近の質問、エージェント自身の推論過程、ツールからの応答など)を一時的に保持します。
- この情報は、In-Context Learning(プロンプト内で例示することでモデルの応答を誘導する手法)などに活用され、直近の文脈に基づいた適切な応答を生成するのに役立ちます。
- コンテキストウィンドウの制約の中で、どの情報を保持し、どの情報を忘れるかというコンテキスト管理もここに含まれます。
-
長期記憶 (Long-term Memory):
- 対話の履歴、ユーザーの好みや属性情報、過去に解決した問題の知識など、将来にわたって参照される可能性のある情報を恒久的に保存します。
- この長期記憶にアクセスすることで、エージェントはよりパーソナライズされた対応を行ったり、過去の経験から学習して同様のタスクをより効率的に処理したりすることができます。ベクトルデータベースなどが長期記憶の実装によく用いられます。
State (状態管理)
短期記憶はフレームワーク等によっては State と表現されることもあります。
State と表現される場合、特にエージェントが現在実行中のタスクの状況や、エージェント自身の内部状態を管理するための情報を指します。
- タスクの完了状態: 現在のタスクがどの段階にあるのか(開始前、実行中、完了、失敗など)を追跡します。
- 繰り返し行われるタスクの進行状況管理: 複数のステップからなる複雑なタスクや、定期的に実行されるタスクの進行状況を管理し、中断からの再開などを可能にします。
- 内部的な状態: エージェントが特定のモード(例:質問応答モード、タスク実行モード)で動作しているかなどの内部状態を保持します。
Agent タイプと Workflow タイプ
AI エージェントと一口に言っても、その振る舞いや設計思想にはいくつかのバリエーションが存在します。 ここでは、Anthropic 社が提唱する「Agent タイプ」と「Workflow タイプ」という 2 つの主要なカテゴリに着目し、その違いと類似性、そして構成要素との関連について見ていきましょう。
どちらのタイプも、LLM とツールを活用して特定の目標を達成しようとする「エージェントシステム」の一種であるという点では共通しています。 しかし、その自律性の度合いや制御の所在に大きな違いがあります。
Workflow タイプ
- 定義: LLM とツールが、事前に定義されたコードパスやロジックフローに従って連携するシステムです。タスクの実行手順や条件分岐が比較的明確に定められています。
- 特徴
- 予測可能性: 実行フローが明確なため、動作がある程度予測しやすく、デバッグも比較的容易です。
- 一貫性: 同じ入力に対しては、ほぼ同じ結果やプロセスを辿ることが期待できます。
- 向いているタスク: 請求書の処理、定型的なレポート作成、特定の条件下での通知送信など、手順が比較的固定化されている、よく定義されたタスク。
- 構成要素との関連:
- オーケストレーション: より手続き的で、ルールベースに近い、あるいはシンプルなシーケンスや条件分岐に基づいた制御が中心となります。Reasoning and Planning の自由度は比較的低く、設計者が定義したフローに沿って動作します。
- ツール: 使用するツールやその呼び出し方も、ワークフローのステップとして事前に組み込まれていることが多いです。
Agent タイプ
- 定義: LLM が、タスクの状況に応じて自身のプロセスやツールの使用方法を動的に判断し、指示するシステムです。固定された手順に縛られず、より自律的に振る舞います。
- 特徴:
- 柔軟性: 予期しない状況や曖昧な指示に対しても、LLM の推論能力を活かして適応的に対応しようとします。
- モデル駆動の意思決定: 次に何をすべきか、どのツールを使うべきかといった判断を、LLM 自身が主導して行います。
- 向いているタスク: 複雑なリサーチ、オープンエンドな問題解決(例:「最高の旅行プランを提案して」)、対話を通じた共同作業、状況が刻々と変化する環境でのタスク遂行。
- 構成要素との関連:
- オーケストレーション: より動的で、LLM の高度な Reasoning and Planning 能力(CoT, ReAct, ToT など)を最大限に活用します。状況を理解し、計画を立て、行動し、結果を評価して次の行動を決定するという、より自律的なループが中心となります。
- ツール: モデルが状況に応じて利用可能なツール群の中から最適なものを選択し、その使い方を判断します。ツールとのインタラクション自体が、モデルの推論プロセスの一部となります。
- Memory と State: 過去の経験や現在の状態を正確に把握し、それを次の行動計画に反映させる能力がより重要になります。
Agent と Workflow の類似性と違いのまとめ
| 特徴 | Workflow タイプ | Agent タイプ |
|---|---|---|
| 制御の主体 | 事前定義されたロジック、開発者 | LLM 自身 |
| 自律性 | 低い | 高い |
| 柔軟性 | 低い | 高い |
| 予測可能性 | 高い | 低い(状況による) |
| コスト | 低~中 - コンテキストの内容次第だが、作業タスク都度の LLM 利用のため Token 消費は比較的抑えられる | 高い - タスク実行毎に LLM の判断が入るため API 利用の場合は Token 消費量が大きくなりがち |
| 得意なタスク | 手順が明確な定型タスク | オープンエンドな問題、複雑で非定型なタスク |
| オーケストレーション | 手続き的、固定的 | 動的、適応的、LLM の推論主導 |
| 構成要素 | モデル、ツール、オーケストレーションは共通して持つが、オーケストレーションは決定的 | モデル、ツール、オーケストレーションは共通して持つが、オーケストレーションは動的で設計思想と複雑性が異なる |
結局のところ、Workflow タイプも Agent タイプも、AI エージェントという大きな枠組みの中に位置づけられます。
どちらのタイプを選択するかは、解決したい課題の性質、求められる自律性のレベル、そして開発リソースや許容できるコストによって決定されるべきです。
シンプルなタスクや定型的なものであれば Workflow タイプで十分な場合もありますし、より複雑で自律的な振る舞いが求められる場合は Agent タイプのアプローチが有効になるでしょう。
同時に、コストにも注意をはらい、そもそも AI エージェントが必要なのか、エージェント化するのであれば、コストが高くとも柔軟性の高い Agent タイプにするのかシンプルな Workflow タイプにするのか、という観点での検討も必要です。
まとめ
本記事では、AI エージェントの基本的な定義から、その頭脳となる「モデル」、手足となる「ツール」、 そして全体を指揮する「オーケストレーションレイヤー」という 3 つの主要な構成要素、さらには「Agent タイプ」と「Workflow タイプ」という 2 つの振る舞いの違いについて解説しました。
これまでに Belong で作成してきたものは、主に Workflow タイプの AI エージェントでしたが、 今後はより自律的な Agent タイプ、特にデータ探索周りにおいて、活用を進められたらと考えています。
本記事で Belong に興味を持っていただけたらぜひエンジニアリングチーム紹介ページを確認していただき、カジュアル面談等お声がけいただけたら嬉しく思います。
- 生成 AI を積極的に扱うチームの求人
さいごに、2025-06-18 に開催される、AI Engineer Summit 2025 でも、 本記事の内容を更に発展させた、AI エージェントに関するセッションを行う予定ですので、ぜひご参加ください。
References
- Agents Whitepaper
- Building effective agents
- Prompt Engineering Guide
- AI Engineer Summit 2025
- ReAct: Synergizing Reasoning and Acting in Language Models
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- What's next for AI agentic workflows ft. Andrew Ng of AI Fund