AI Hackathon with Google Cloud で入賞した話 ~概要編~
はじめに
先日行われた AI Hackathon with Google Cloud において、
私と @kobori が本業のプロジェクトとは別にチームを組んで参加し、ベスト・オブ・リテール賞を受賞しました。
本記事では今回ハッカソンに提出したプロジェクト 「b-moz」 の概要と、技術的なポイントについて紹介します。
AI Hackathon with Google Cloud とは
AI Hackathon with Google Cloud は Google Cloud Japan が主催する AI 関連のハッカソンであり、 Google Cloud の AI と Computing プロダクトを少なくとも一つづつ使ってアイデアを実現するというコンセプトのものでした。
ハッカソンのプロジェクトページを見る限りでは、参加登録者は 485 名、一部メンバーはチームを組みチーム数は 87 でした。 この参加者数から、最終的に提出されたプロジェクトは 33 プロジェクトであり、アイディアを実現しプロジェクトを提出するだけでも一定の難しさを感じられます。
b-moz
今回のハッカソンでは、小売業における共通の課題である、商品カタログデータの収集を自動化するプロジェクト 「b-moz」 を提出しました。 b-moz は Gemini、Cloud Run、 Google Custom Search Engine などを用いて公開情報から商品カタログデータを収集し、データベースに格納するシステムです。
着想の背景
EC を始めとして、小売を行う場合は適切な在庫管理や売買管理のために商品のカタログマスタが必要となります。
Belong では社内で統一したカタログを用いるためのデータベース、Model Catalog を管理しており、現在のところそのデータの収集はほぼ手動で行われています。
スマホをはじめとしたスマートデバイスは定期的に新しい商品が発売され、特に Android スマホは様々なメーカーやキャリアから発売されるため、継続的な情報の収集が必要となります。
しかし、Model Catalog に追加するために正確な情報を集める時間的・人的なコストは少なくありません。
また、Belong のオペレーションセンターは年間 100 万台規模でデバイスを扱うため、カタログデータの不足により一部の商品の情報登録を止めてしまうとボトルネックとなってしまい影響が大きくなります。
そこで、本ハッカソンでは LLM と Web 検索を活用し、カタログデータの収集を自動化することで、データ収集のコスト削減と、データ利用の迅速化ができるのではないかという考えでプロジェクトを立ち上げました。
b-moz は百舌鳥が獲物を狩った後に溜める習性を持っていることになぞらえてカタログを収集する百舌鳥(モズ)をイメージしています。
機能
本ハッカソンで作成した主な機能は次に挙げる 2 つです。
- 最新商品情報の収集
- 最近発売・発表された商品情報を集め、その商品名(モデル)と付随する情報(e.g. メーカー、シリーズなど)を取得する
- 商品の詳細の取得
- 商品名から売買に必要なカタログ情報を収集する
- 例:
- スマホ
- モデル名
- ストレージ
- 色
- PC
- モデル名
- CPU
- メモリ (RAM)
- ストレージ
- 色
- スマートウォッチ
- モデル名
- 色
- 素材
- 大きさ
- スマホ
これらの機能は、Google 検索を用いてストレージやカラー展開などカタログの構成要素を持つ情報元を見つけ、 LLM を用いて情報の取捨選択を行い、必要な情報を抽出することで実現しました。
b-moz の技術構成
構成としては、Cloud Run 上で Python、Flask で API を構築しました。
LangChain を用いて、 Google Custom Search Engine を Retriever とした RAG のチェインを構築し、LLM のモデルには Vertex AI の Gemini を用いました。
全体像は次のようになります。
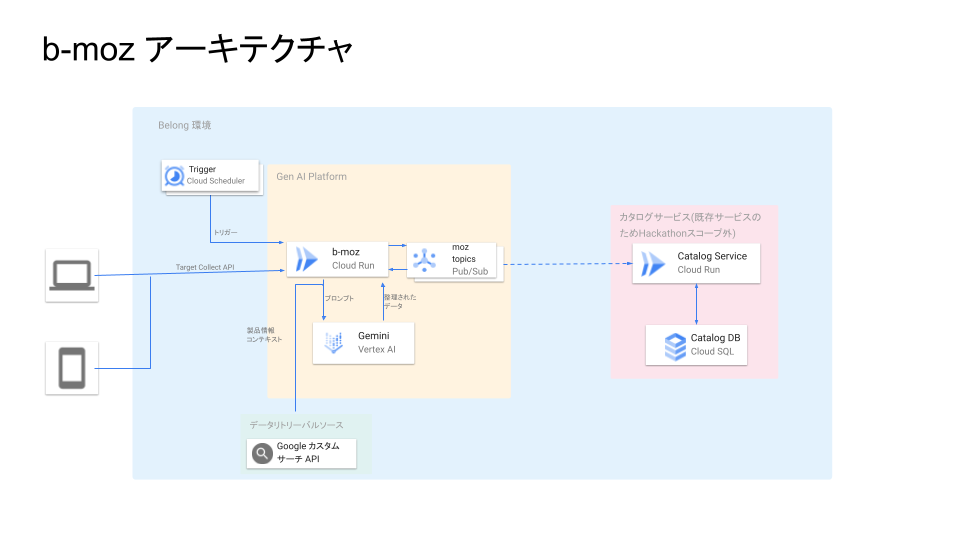
今回のアプローチでは、情報を抽出するにあたって次の点が課題となりました。
- 検索結果に情報は含まれているものの意図通りの情報が抽出できない
- JSON が返らない、もしくは稀に指定とは異なる形式の JSON が返される
1 つ目の課題に関しては、 プロンプトエンジニアリングで対応しました。 具体的には、 Few-Shot プロンプティング (Brown et al.) を用いて、抽出したい情報の具体例や、 起きうるパターンをプロンプトの中で例示することで、LLM が想定する値や回答パターンを想定しやすいプロンプトを作成することでハルシネーションの出現を抑え、必要な情報を抽出可能にしました。
2 つ目の課題は response_mime_type を指定することで JSON で値を返すことの強制力を持たせました。
この機能は 2024 年の夏頃に使える様になった機能であり、今回のハッカソンで初めての利用となりました。
公式ページ には Google 提供の Python クライアント用のサンプルがありますが、
今回は LangChain を通しての Gemini 利用となったため、利用方法が当時は明確ではないという課題に直面しました。
そのためデバッグしながらライブラリのコードを読み込んだところ、以下の形で llm のモデルに bind をすることで有効になることがわかりました。
my_chain = (
...
| prompt # 事前定義した prompt
| llm_gemini.bind(response_mime_type="application/json") # LLM に JSON でのレスポンスを強制する
| SimpleJsonOutputParser() # JSON として結果をパースするときのお作法
)
b-moz の検証
今回のハッカソンでは、「作って動いて満足」ではなく、効果の検証も行いたいと考えていました。
今回取り組んでいる課題は分類問題として解釈可能と考え、分類問題の評価指標である F1 スコアやそれに紐づく指標を用いて検証を行いました。
評価に関する詳細は @kobori の 記事 に記載されています。
今後の展望
今回は具体的に存在する課題から着想を得てハッカソンのプロジェクトを立ち上げました。 そのため、ハッカソン用に構築した仕組みを基に、Belong 社内のモデルカタログのデータ収集を自動化するプロジェクトを立ち上げ、現在はその検証を行っています。
b-moz は、これまで収集から検証まで含めて数日かかる事もあった新しい商品カタログ情報の登録プロセスの、特に収集部分を劇的に短縮することに貢献します。 今後は更に、これまで人手で行ってきた情報の検証も含めたプロセスの自動化を狙っていきます。
おわりに
本記事では、AI Hackathon with Google Cloud で受賞したプロジェクト 「b-moz」 の概要について紹介しました。 既存の課題から、思いつきで立ち上げたプロジェクトでしたが、LLM の得意な情報抽出の役割を活かし、高い精度での効率的な情報収集を実現することができました。 アイディアの着想から検証まで、短期間でのプロジェクト立ち上げを通じて、新たな技術の可能性を感じることができました。
Belong では LLM を用いた取り組みを積極的に行っており、今後も LLM を活用したプロジェクトを進めていく予定です。 プラットフォームチームで、SRE やデータチームと密に連携しつつ、LLM を活用した新たな取り組みを進めていきたい方は、ぜひお声がけください。 弊社エンジニアリングチームの情報は エンジニアリングチーム紹介ページ をご覧ください。