AI-DLC の概要とチーム開発における適用例
はじめに
最近は SDD(Spec Driven Development)により Agentic Coding の精度を高める方法論が注目されていると思います。
本記事では、私が最近、AWS による AI-DLC のハンズオン(本来2-3日かかるAI-DLC Unicorn Gymの半日簡易版)を受けたり、 AI Engineer Code Summit に参加し、セッションやワークショップでの議論を通じて AI-DLC の理解を深められたこと、 そして、実際にプロジェクトの立ち上げや既存サービスに対する新機能追加において AI-DLC を適用してみた経験を踏まえ、 使える知見を共有したいと思います。
本記事では、まず AI-DLC の概要を説明し、その後、具体的な適用例を紹介します。
後続記事 AI-DLC を実行するために有用なプロンプト例 では、実際に使えるプロンプトを紹介します。
AI-DLC とは
AI-DLC(AI-Driven Life Cycle)は、ソフトウェア開発プロセス全体に AI エージェントを統合し、 各フェーズでの効率化と品質向上を図る方法論です。
AWS により提唱され(参照)、概要をまとめると以下のようになります。
- Inception: 作りたいもののビジョンや要件を定義し、ユースケース、ユニットへ落とし込みます。
- Construction: Inception フェーズで定義された要件に基づき、論理設計やドメインモデルを構築し、コードやテストの生成を行います。
- Operation: 作ったシステムのデプロイを AI を活用して自動化します。
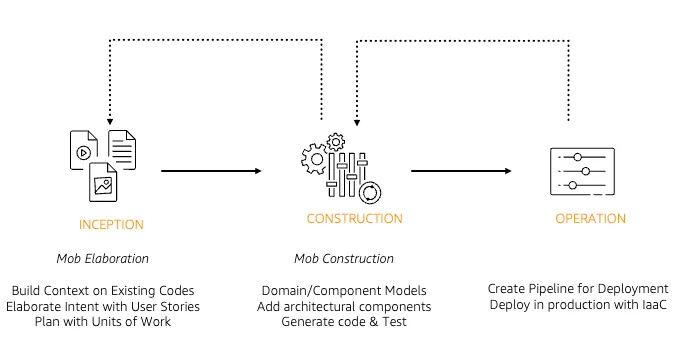 https://aws.amazon.com/jp/blogs/devops/ai-driven-development-life-cycle/
https://aws.amazon.com/jp/blogs/devops/ai-driven-development-life-cycle/
AI-DLC のポイント
この手法の利点としては、AI の持つ汎用的な開発知識を活用しつつ、自身の持つドメイン知識を組み合わせることで、 迅速かつ高品質なソフトウェア開発が可能になる点です。
特に以下の3点が重要です。
- AI の Foundation Model の知識を引き出す
- 途中の成果物をファイルに保存する
- コンテキストマネジメント
1. AI の Foundation Model の知識を引き出す
生成 AI は広範な知識を持っています。 「EC を開発したい」というような一般的な要件に関しては、必要な機能や設計パターン、ベストプラクティスを熟知しています。
AI-DLC では、この知識を最大限に引き出すために、「指示をする」のではなく、質問をするような形で AI に働きかけます。 また、一般的な知識から、特定のドメインや環境に紐づいた意思決定が必要なポイントは、 AI から質問を投げかけてもらうことで、こちらの意図に沿った形で開発を進められます。
AI からの質問例
ステップ1: プロジェクト要件の明確化
プロジェクトの目的と範囲を定義する
[Question] このプロジェクトの主な目的は何ですか?
[Answer] ECサイトの構築
[Question] 対象ユーザーは誰ですか?(例:開発者、エンドユーザー、研究者など)
[Answer] エンドユーザー
[Question] 実装したい主な機能は何ですか?(できるだけ具体的に記述してください)
[Answer] スマホの売買機能
ステップ2: 技術スタックの決定
使用する技術を確定する
[Question] 使用する主要な技術スタックを教えてください:
フレームワーク(例:React, Vue.js, Flask, FastAPI, Spring Bootなど)
AIライブラリ(例:TensorFlow, PyTorch, LangChain, OpenAIなど)
データベース(例:PostgreSQL, MongoDB, MySQL、不要など)
デプロイ環境(例:Docker, Kubernetes, AWS, GCP、ローカルのみなど)
[Answer]
hogehoge...
2. 実装するのに必要な情報をファイルに保存する
AI-DLC を進めるときに特に重要だと感じる点は、実装するのに必要な情報をチャットなどのコンテキスト内でのみ保持するのではなく、 適宜ファイルに保存し、AI に参照させながら後続タスクを実行することです。
この理由として、次の点が挙げられます。
- 再現性向上
- 並行性向上
- AI のコンテキストウィンドウの節約
再現性向上
成果物をファイルに保存することで、特定の AI セッションに依存せず、保存された成果物を基に同じタスクを繰り返し実行できます。
例えばタスクを ToDo リストとしてファイルに残すことで、途中でセッションが切れても、同じタスクを再度実行できます。
resume 機能を使えば近いことができると思うかもしれませんが、ファイルで保存することで次の様なアプローチも可能になります。
- 途中で セッション(コンテキスト)が失われた場合の復帰
- 別 PC や、PC<>サーバー間での作業継続も可能
- 途中から利用する AI モデルの変更
- 比較的速度の早い Amazon Q、Claude Code で大枠を作成したあと、codex で細かい詰めを行うなど。逆も然り
- git worktree を用いて複数ブランチで同じタスクを同じポイントから実行し、最良の結果を選択する
並行性向上
並行性向上は、依存関係のない別タスクを並行して実行できる点を指します。
AI との会話を通じてプランニングを行ったときに、その予定が特定の AI セッションとのコンテキストにしかない場合、
逐次的にタスクを実行する必要があります。
しかし、タスクをファイルに保存しておけば、依存関係のないタスクは別セッションで同時に実行でき、全体の開発時間を短縮できます。
これをローカルで行う場合は git worktree を用いると便利ですし、クラウドサービスを用いる場合は実行環境ごとに別ブランチをチェックアウトして、 それぞれのタスクを実行するイメージです。
AI のコンテキストウィンドウの節約
AI のコンテキストウィンドウは、大きくなるほど特定の意図に沿った回答が得られにくくなり、かつ反応は遅くなる傾向があります。
そのため、コンテキストの節約は、アウトプットの質、開発体験の両面で重要です。
これはコンテキストをファイル化するだけでなく、一定の粒度に分割し、一度に参照しなければいけないものを減らすことで実現できます。
AI に作業に関係のある情報のみを参照させ、コンテキストウィンドウの使用量を抑えます。
たとえば、Inception 過程において、全体のプランは見通しの良さのためにひとファイルで整理しつつも、 各タスクの実行時には、依存関係のないタスクグループごとにファイルを分割し専用の実行プランのファイルを作成し、 実行時にはそのファイルと、関連するプログラムなどのファイルのみを AI に参照させます。
3. コンテキストマネジメント
コンテキストマネジメントは、AI に提供する情報を適切に管理し、必要な情報のみを提供することです。
前述のファイル化もこの一環ですが、AI に提供する情報を整理し、適切なタイミングで提供することが重要です。
コンテキストの節約は大切ですが、AI に提供する情報の質も重要です。
必要な情報が不足してしまったら、期待したアウトプットが得られない可能性があります。
この実現には様々なアプローチがあると思います。 ファイルベースで考えると、インデックス用のサマリファイルを作成し、作業の概要、もしくはリポジトリの構成をまとめ、 詳細のファイルは別に設ける形です。リポジトリの内容に関しては、コード自体がその詳細を担うこともあります。
Serena MCP のようなツールを用いて、リポジトリ全体をインデックス化し、AI に必要な情報のみを提供する方法もあります。 特定の階層ごとに README ファイルをおいてそれ以下の内容を要約し、 AI が各プログラムファイルの内容を逐一読まなくても内容を把握できるようにするアプローチもあるでしょう。 プロンプトキャッシングの仕組みを持つモデルを利用する場合は、それを前提にしたコンテキストマネジメントも考えられます。
これについては、良い方法を見つけたらぜひ私に教えてほしいです。 :)
AI-DLC のリアルワールド SDLC への適用
ここまでは AI-DLC の概要、特に SDD 的なアプローチについて説明しました。
チームでプロジェクトワークを行うには、プログラムを書くだけではなく、チーム内の連携を意識した動き方が必要です。
そのため、Inception->Construction->Operation の文字面で表される以上に多くの事を考慮する必要があります。
具体的にはチケットの作成タイミング、コードレビュー、ドキュメント作成などです。
そもそも SDLC とは?という方は、拙著 エンジニアリング組織開発 の第5章をご覧ください! :)
冗談はさておき、5 年前の記事がこちらにありますので、気になった方はご参照ください。
現時点で私が有効だと感じている AI-DLC のフローは次のものとなります。
大枠としては次の流れのイメージです。
- プロダクトマネージャー・エンジニアで作りたいものを定義し、AI を用いて SpecFiles (要件仕様書) を作成する
- SpecFiles を元に作業計画を立て、タスクをチケット化する
- AI を用いて SDD(Spec-Driven Development)で実装
- エンジニアとのやり取りを通じて精度を高めた実装結果から SpecFiles と照らし合わせて検証・フィードバックを行う
- 成果物の検証
図では Operation の部分は割愛しています。 定義上は CI/CD や IaC の構築の部分が主の理解ですが、 アラート監視やインシデント対応などでの AI 利用の文脈を含んで考えると、AI Agent活用方法は更に広がります。

図では表しませんでしたが、SpecFiles 作成後に、Mock の画面などを作成して、ユーザーストーリーの確認を行うフェーズを入れることも有効です。
おわりに
本記事では AI-DLC の概要と、私が考えるチーム開発における適用例を紹介しました。 AI の Foundation Model の知識の活用、途中の成果物のファイルへの保存、コンテキストマネジメントが重要なポイントであり、 特にファイルへの保存は、再現性、並行性、コンテキストウィンドウの節約に寄与するため積極的に取り入れることをお勧めします。
今後も実行を重ね、より良い方法を模索していきたいと思います。 一緒に AI-DLC を活用し、プロダクトの開発と手法自体の進化を目指していただける方は、ぜひお声がけください!