Observability overview
はじめに
本ブログでは Observability の概要について触れます。
先日 GCP の公式ユーザーグループの Jagu'e'r の、
私がコアメンバー (運営委員的なもの) を務める SRE/o11y 分科会で Observability の概要と GCP での適用例 というタイトルでプレゼンテーションを行いました。
このブログはそのプレゼンテーションの内容を抜粋して書き起こしたものになります。
Observability とは
Observe + Ability = 観察できること(可観測性) であり、システムで何が起こっているかをどれだけ理解できるかを示すシステム特性の 1 つです。 よく o11y と略されます。
なぜ Observability が大切なのか
システムの安定稼働や問題の早期対応には平均検出時間(MTTD)、復元時間(TTR) を最小化できることが大切であり、 o11y はその実現に必要な要素です。
Observability が高くなるほど以下ようなことが実現可能になります。
- 問題が起きたことに気づける
- 問題がどこで起きたかわかる
- 問題が起きそうなことがわかる
- 対応が必要な問題だけわかる
まず、問題の調査を開始するには問題が起きたことに気づける必要があります。次に問題を解決するためにはどこで問題が起きており、原因や影響が何なのか知る必要があります。 システムを運用する上ではここまでは必ず達成したいラインです。
更に発展すると問題が起きそうなことがわかるようになります。例えば、急なトラフィックの増加が観測され、そのままだとサーバーの CPU やメモリのキャパシティ的にサービスがダウンすることが予想されるため先回りして対応するといったものです。
ここから更に発展すると対応が必要な問題だけわかるようになるというような世界もあります。 AI Ops などで問題のパターンを学習し、例えば CPU 使用率が一定量を超えるのは一時的なのか長期化するのかなどを判別し、対応が必要なものだけアラートを出すというようなものです。
Observability の 3 本柱
Observability では重要とされる以下の 3 つの要素があります。
- Metrics
- Traces
- Logs
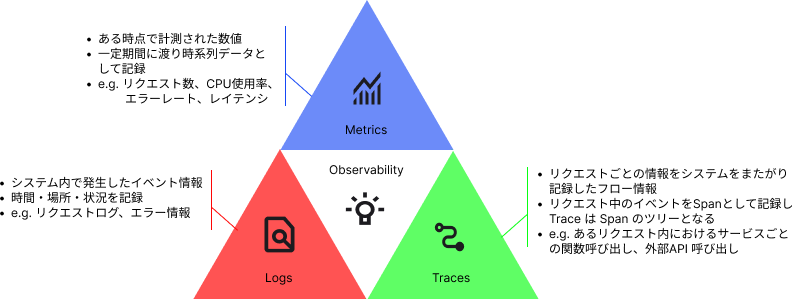
以下ではこれらの要素の深堀りをしていきます。
Metrics
Metrics とは一定の期間にわたって測定された数値であり、タイムスタンプ、名前、KPI、値などの属性を記録したものを指します。 Metrics はモニタリングで時系列に可視化したり、アラートの発火、分析に用います。
引用:https://cloud.google.com/monitoring/dashboards
Metrics の利用はまず SRE 本で紹介されているゴールデンシグナル に着目すると大事なポイントを抑えられます。
- Error - サービスが失敗する割合
- Latency - サービスがリクエストの処理にかける時間
- Traffic - サービスに対する要求の量
- Saturation - サービスの利用リソース量が最大にどれだけ近いか
Metrics として利用できるものはこの他にもたくさんあり、例えば GCP だと 膨大なリスト が公開されています。 サービスの特性や Metrics を用いて何をしたいのか、どう可視化・分析したいのかによって利用するものを選択します。
Trace
Trace はリクエストの処理経路を End to End で表すものです。
リクエストに対して実行された各処理 (Span) を、それを実行したマイクロサービスや関数レベルで可視化します。
Trace はリクエストの経路の明確化やボトルネックの発見に利用でき、TraceID を引き継ぎ Span を作成してくことでサービス(インスタンス)をまたいだリクエストの経路を表現可能です。

引用:https://opentelemetry.io/docs/concepts/observability-primer/
運用時にはプロダクトチーム全体で Span を作成するポリシーを策定し実装すると要所要所での状態の把握がしやすくなります。
Span 作成ポイントの例
- DB アクセス時
- 外部サービス呼び出し時
- 複雑な処理
Logs
Log は特定の時点で発生したイベントのテキストレコードのことを指します。
Log を有用なものにするためには以下の情報を含めたいです。
- 場所
- アプリケーション名
- インスタンス名
- ゾーン
- 時間
- タイムゾーンも含める
- 状況説明
- 何を行った・行おうとしたか
- 対象を特定するための情報
- ドメインに関連するユニークな ID
この他にも、以下のようなルールを設けチーム全体である程度のログメッセージの質を保てる用にすると良いです。
- 英語で書く
- 主要な処理の開始前に必ず書く
- 外部サービス呼び出し前に必ず書く
- ログレベルの基準を明確化
- e.t.c.
GCP の場合は LogEntry と呼ばれる構造化ログ が利用可能で、上に挙げたような情報ををプラットフォーム側で差し込み記録してくれます。 LogEntry にはメッセージ以外にも自身でフィールドを追加して記録することが出来るので、アプリケーションの状態を把握するために利用すると便利です。
まとめ
本ブログでは Observability について触れました。Observability は Metrics、Traces、Logs の 3 つの主要な概念があり、プラットフォームやツールを用いると計測がしやすくなります。 ただ、Observability の向上はツールを導入しただけで実現されるものではなく、逆にツールにより観測用のリソースが消費されることで状態が悪化することもあります。 観測結果をもとにサンプリングレートや取得する情報を変えることで長期的・継続的に最適化していくことが必要です。
また、Observability はインフラを整えたりダッシュボードを作成するのと関連して SRE の文脈でよく出てきますが、Trace の Span を実装したり Log を書き込むのは SWE (ソフトウェアエンジニア) の役割です。 Observability の向上は SRE と SWE の共同作業によって実現可能となります。
最後に、Belong ではエンジニアを募集しています。良いログをとにかく書きたいサーバーサイドエンジニア、o11y を向上させたい SRE など様々なポジションがあります。 本記事で Belong に興味を持っていただけたらぜひエンジニアリングチーム紹介ページを確認していただき、カジュアル面談等お声がけいただけたら嬉しく思います。