Data Agent で変わるデータエンジニアの役割と拡がる共創の基盤
こんにちは。データプラットフォームチームの @kobori です。 先日 Las Vegas にて Google Cloud Next '25 が開催されました。
弊社ではカンファレンス渡航補助プログラムという制度があり、一定の要件を満たすことで参加費や交通費、宿泊費の補助と日当の給付を受けることができます。 今回は本プログラムを利用して、Google Cloud Next '25 に現地参加してきました。
Google Cloud Next はもちろんですが、海外カンファレンスへの参加には憧れがあったものの、自分の人生においては縁のないものだと思っていたため、今回の機会は個人的に非常に嬉しいものでした。
今回の Next は、おそらく誰もが予想していた通り、AI や Agent にテーマがフォーカスされていた印象です。 キーノートセッションは Veo 2 により生成された映像から始まりましたが、その映像は、生成 AI による動画生成、音声生成の能力の高さをアピールしているようで、第 7 世代 TPU の Ironwood の発表は、AI への力の入れ具合を主張しているように感じられました。
そんな雰囲気の今回の Next ですが、 私は Data Agent に注目しました。 Data Agent の登場によるデータ基盤とデータエンジニアのあり方について少し考えを巡らせてみたため、本記事ではその考えをまとめてみました。
Data Agent
Data Agent は昨年の Google Cloud Next Tokyo '24 のキーノートでも登場していました。 スニーカーの売上を例に、売上数の異常検知からその原因の特定までを対話形式で行っていたデモが印象に残っています。
今回の Next のキーノートでは、Data Agent として 3 種類のロール別 Agent が紹介されていました。
- データエンジニアリングエージェント
- データカタログの自動生成、メタデータの構築、データ品質の監視、パイプラインの構築など、データエンジニアリング業務を広くサポートするエージェント
- データサイエンスエージェント
- データのロード、特徴量エンジニアリング、モデルのトレーニングや予測までをサポートするコーディングパートナー
- データアナリストエージェント
- 自然言語による対話形式での分析をサポートし、チャートの作成や可視化を行うエージェント
本記事では、この中でもデータエンジニアリングエージェントにフォーカスしたいと思います。 データサイエンスエージェントは BigQuery Colab Enterprise notebook に埋め込まれており、既に GA の機能のようです。 データアナリストエージェントは、対話形式で分析をサポートしてくるようですが、Looker との相性がよいようで、データの民主化に一役買ってくれそうなエージェントです。こちらはまた別記事にて触れたいと思います。
キーノート中では、アメリカ・ネバダ州の政府機関である Nevada DETR というプロジェクトにおける活用事例が紹介されており、 BigQuery pipelines や Data canvas に埋め込まれた Data Enginering Agent を使い、データの結合とクレンジングを行うパイプラインの構築を効率化し、 さらに、Colab Enterprise notebook 上でのデータ分析でも Data Science Agent を活用して素早くインサイトを導出する流れが実演されていました。 「Easy」というキーワードとともに、「従来であれば数ヶ月かかっていた作業が、Agent の活用により数分で完了する」データサイエンスの未来が表現されていました。
Data Engineering Agent
Data Engineering Agent については、「Automate data pipelines with AI agents in BigQuery」というセッションで解説されていました。 セッションによると、Data Engineering Agent は今年の後半を目安にリリース予定とのことですが、部分的には利用できる状況とも言えそうです。
例えば、BigQuery data preration では、自然言語による指示によりデータの前処理のクエリを生成することができます。
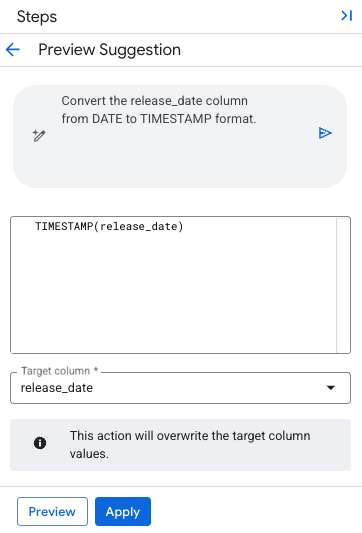
まだ preview 中のようですが、BigQuery data canvas でも自然言語プロンプトによる分析機能が利用可能です。
これらの機能に加えて、セッションではより自律的で高度に機能する Agent が紹介されていました。 自然言語による指示でパイプラインを構築可能にすることで、データエンジニアに限らず、データアナリストやデータサイエンティストもデータパイプラインの構築に携われるような未来を描いているようです。
セッション中でのデモでは、BigQuery pipeline Studio から自然言語による指示により、GCS のデータを読み込み、前処理を施した上で、別のテーブルと結合する一連の流れを実演していました。 作成されたパイプラインはコードとして出力されますが、出力されたコードは既にパイプシンタクスが用いられていました。 SQL を自動生成するにあたり、従来の SQL 構文よりもパイプシンタクスの形式の方が Agent が構造を理解しやすかったのでしょうか? パイプシンタクスの導入すら、Agent を本格的にシステムに組み込むための布石だったとしか思えません。。
Agent は、BigQuery Studio だけでなく、CLI や API からも利用可能となるようです。 既存のパイプラインやメタデータを活用してパイプラインを生成するようになるため、メタデータ整備は重要になりそうですが、これもまた、今回の BigQuery の update により効率化できそうです。 詳しくはまた別記事にて触れたいと思います。
データエンジニアの役割
Data Agent の活用はいまや急務だと感じています。 弊社のデータプラットフォームチームは現在 2 名体制と小規模で、日々発生するタスクのすべてを捌ききれているとは言えません。
データ活用が事業成長の鍵を握る今の時代において、私たち自身がデータ活用のボトルネックになるわけにはいきません。
チーム拡張のための採用活動も進めていますが、Data Agent の活用ももう一手として、今すぐ取り入れるべきアプローチだと感じています。 エージェントの支援を得ることで、これまでデータエンジニアが担っていた業務の一部を非エンジニアに開放できれば、私たちはより本質的な課題に集中することができます。 データユーザも自由にデータにアクセスができるようになり、結果として会社全体の意思決定のスピードも高まるはずです。
エージェントの登場によって「自分の仕事がなくなるのでは?」と不安になる気持ちも正直なところ持っています。 ただ現実には、すでにタスクは溢れており、いかに負荷を軽減し、より価値の高い領域に時間を割けるかに意識を向けるべきフェーズなのかもしれません。
仕事はゼロサムではありません。 Agent によって役割が変化していくことを受け入れ、変化を活かす側に立つ意識を持つべきだと思いました。
これまでは「データ基盤を構築すること」がデータエンジニアの役割でしたが、 これからは 「誰もが構築しやすい基盤を設計すること」に役割が変わっていく のかもしれません。 思えば、dbt ももともとはデータアナリストによって生まれたツールでした。 自身の得意な SQL を使い、パイプラインを自分たちの手で管理できるようにすることで、よりスケーラブルかつアジャイルなデータ活用の実現を目指していたように思います。
同じように、Data Agent もデータ活用に近い人たちが、自分たちの手でニーズを形にしていくためのツールになるのだと思います。 それにより、我々データエンジニアの役割が代替されていくことは自然な流れであり、それを阻害せず、推進するのがこれからのデータエンジニアの役割になるのかもしれません。
データエンジニアの責任
ソフトウェアエンジニアは「正しく振る舞うコード」を書くことが求められます。 一方で、データエンジニアが提供するのは「コード」ではなく「データ」です。 そして、データにおいては常に完璧な精度が求められるわけではありません。
大事なのは、
- おおまかな傾向が見えること
- 重要なインサイトが得られること
- そこに妥当な根拠があること
だと思っています。
この視点に立つと、コードが読めるエンジニアだけがデータ基盤の開発を担う必要はないのかもしれません。 データの違和感は利用者自身が最も気づきやすいですし、速度感を持って柔軟に扱えるデータ基盤の方が求められているかもしれません。
エージェントの力を借りながら、非エンジニアのメンバーが自分たちでパイプラインを作ることも可能になるため、 これからのデータエンジニアには、正しいデータの提供ではなく、正しく使えるデータ基盤を提供することや、 その自由さから生まれるカオスを統制していくことが求められるのかもしれません。
まずは Mart から
Data Agent をすぐに活用していきたい気持ちはありますが、実際に移行のコストなどを考慮すると現実的ではないのかなと思います。 弊社では dbt-core を用いて DWH を構築しておりますが、すぐに全面的に移行することは難しいのが現状です。
Data Engineering Agent の正式なリリースはまだ先のため、まずはデータ活用に近い Mart 部分から、Data Preparation や Data Canvas などを開放し、少しずつ Agent を導入していける素地を整えていければよいなと考えています。
さいごに
今回は初めての Google Cloud Next 現地参加ということで、非常に貴重な機会をいただき、今は感謝の気持ちでいっぱいです。 現地の熱も感じることができ、より一層自分も仕事に力が入ります。 今回の Next に参加して得られた学びを、自分たちのチームやプロダクトにどう還元していけるか、試行錯誤を続けていきたいと思います。 また、来年の Next では、是非登壇する側に立ちたいと密かな野望を抱えています。
このように、弊社ではエンジニアの技術力向上のための制度も整えられております。 弊社に興味を持たれた方は、是非 Entrance Book を覗いてみてください! データプラットフォームチームも絶賛募集中です!