Next'24 から学んだ GenAI の基礎
はじめに
渡航補助プログラムで初渡航 & Next'24 に参加してきました! でも軽く触れた通り、今回の Google Cloud Next'24 では生成 AI(GenAI) に関する発表が主であり、非常に力を入れられていることを肌で感じてきました。
本記事ではセッションを通じて得た知識をもとに GenAI やそれを利用したアプリケーション構築の基礎についてまとめてみました。
RAG
RAG(Retrieval Augmented Generation)は、LLM(Large Language Model)が学習していない内容についても回答できるようにするためのアプローチです。 具体的には、回答に必要な情報を質問と一緒に渡す手法です。
RAG の基本的な流れ
RAG の基本的な流れは以下の通りです。
- クエリ内容を Vector Store に問い合わせ、追加の情報を取得(Retrieve Arguments)
- クエリ内容と追加情報を利用してプロンプト内容を作成
- プロンプトを LLM に入力し、出力を得る(Generate)
セッション内では、Google Cloud のリリースノートや Go のパッケージ情報を追加の情報とする RAG アプリケーションのデモが行われていました。

Vector Search
文章や画像などのデータを数値ベクトル表現に変換することを Embedding といいます。 Embedding を行うことでデータ同士の類似度をベクトル空間内でのユークリッド距離やコサイン類似度などで計算することが可能になります。
Retrieve Arguments では元の問い合わせ内容(文章など)を Embedding し、Vector Store から類似度が高いデータを LLM への追加情報として入力します。
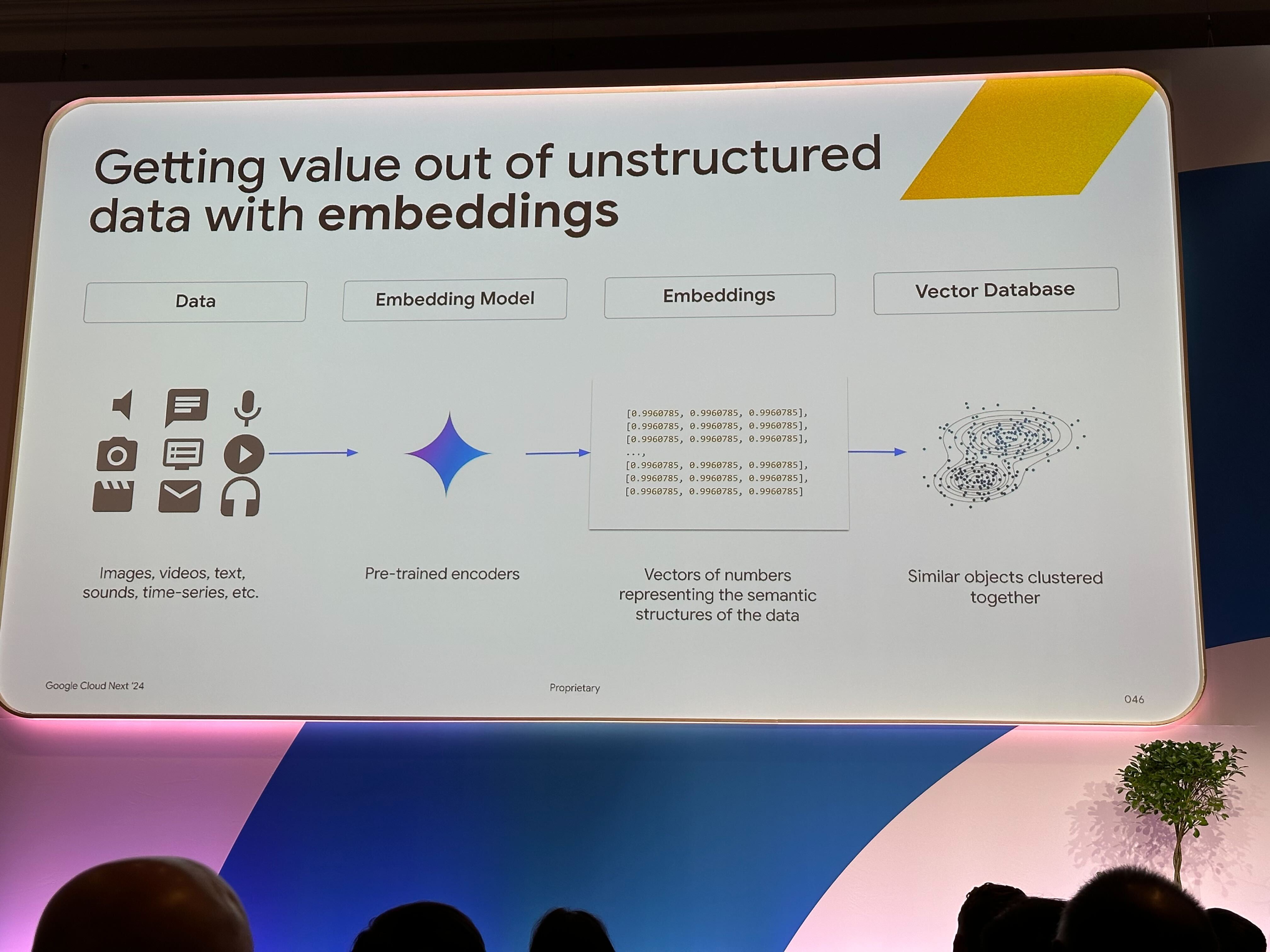

Embedding には、その名の通り Embedding Model を利用します。 セッション内では embedding-001 を API 経由で利用して、Embedding を行っていました。 また、以下の記事にもある通り Next'24 で新しい Embedding Model も紹介されています。

Gemini Model を利用して Go で Embedding を行う例
Gemini の Model を利用するには API Key が必要です。 API Key は以下のコマンドで作成できます。
gcloud services api-keys create \
--display-name="$DISPLAY_NAME" \
--api-target=service=generativelanguage.googleapis.com \
--project=$PROJECT
Go の Client Library は以下を利用します。推奨パッケージは Embedding は利用できるもののまだ機能が出揃っていない様子でした。
import (
"context"
"errors"
"fmt"
"os"
"github.com/google/generative-ai-go/genai"
"google.golang.org/api/option"
)
type Doc struct {
Title string
Content string
}
func EmbedDoc(ctx context.Context, doc *Doc) ([]float32, error) {
key := os.Getenv("API_KEY")
if key == "" {
return nil, errors.New("no API key")
}
client, err := genai.NewClient(ctx, option.WithAPIKey(key))
if err != nil {
return nil, err
}
defer client.Close()
model := client.EmbeddingModel("embedding-001")
res, err := model.EmbedContentWithTitle(ctx, doc.Title, genai.Text(doc.Content))
if err != nil {
return nil, err
}
if res.Embedding == nil {
return nil, fmt.Errorf("no embedding generated")
}
return res.Embedding.Values, nil
}
また、Vector Store として Vertex AI Vector Search を利用することできます。
これは ScaNN(Tree-AH と呼ばれる近似アルゴリズムを利用した ANN の実装)を採用したベクトル検索のためのプロダクトです。 ann-benchmark にもありますが、ScaNN は ANN の中でも高速で精度も高いとされています。 また、基本的な最近傍探索(総当たり)を選択して利用することもできます。これは基本的に正解データを扱う必要があるとき(e.g. インデックスの性能評価)に利用します。 総当たりでの検索は線形的に計算量が増加し、大量のデータや LLM のように高次元ベクトルを扱うケースで現実的な時間内に真の最近傍を求めることため、 ベクトル検索ではスケールしやすい ANN が利用されています。
なお、Next'24 では Firestore の Vector サポートも発表され、Google Cloud データベースプロダクトでも基本的にベクトル検索を扱うことが可能になっています。

GenAI モデルのカスタマイズ
GenAI のモデルをどのようにカスタマイズするかについて、以下の紹介がありました。
- Prompt Engineering
- 期待した出力を得られるようにタスクの詳細や十分な文脈を与えたり、いくつの例を(few-shot)挙げたりする
- Grounding (RAG)
- 外部ソースの特定のドメインのデータを入力に利用する
- Tuning
- 新たなトレーニングセットを元にモデルのパラメータを更新する

Prompt
プロンプトの入力内容によって出力が変わるため、基本的には何度も入力を調整することになります。 今回の Next'24 では、Prompt のパラメータを含むバージョン管理の発表と、それを評価・比較するためのツール群の発表もありました。
- Rapid evaluation
- AutoSxS

Tuning
Tuning には以下のような恩恵があります。
- 高品質な出力
- コスト削減の可能性
- RAG のように追加の情報を与えたり、few-shot を行わなくても良くなったりする
- 結果的にプロンプトのサイズ = トークンサイズが小さくなるためトークン単位の課金ではコスト削減につながる
- また、小さいモデルで良くなることで当然計算量が減るためレイテンシも改善される可能性がある

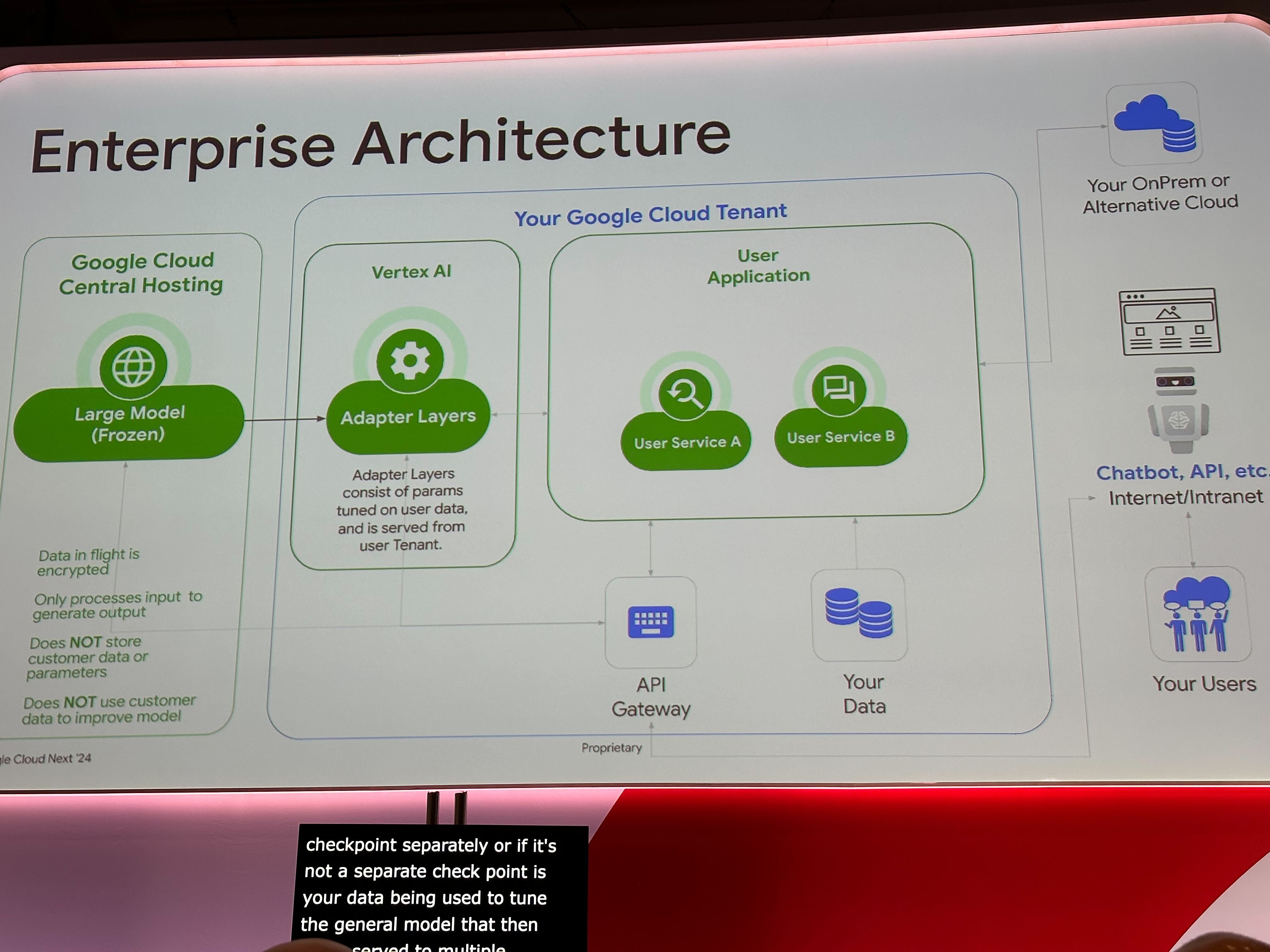
Google の Tuning は Adapter Layer と呼ばれる Gemini などの Google の基盤モデルとは切り離されたレイヤーに対して学習を行います。 これは LoRA (Low-Rank Adaption) に基づいていると言及されていました。
- 学習したパラメータ(Adapter Layer)は Google Cloud プロジェクト内に保存され、他の人がそれを利用することはできない
- 学習データが基盤モデル側で利用されることもない
- Gemini モデルの直接呼び出しと Gemini モデルを Adaption Tuning したモデルの呼び出しにかかるコストは同じ
- つまり適切に Tuning することで特定のユースケースで Gemini モデルより高精度なモデルを同一のコストで呼び出すことが可能になります
また、Distilling Step-by-Step という Tuning 方法が紹介されていました。 あるタスクに対する回答とその根拠を Teacher Model から作成し、それデータセットとして Student Model を学習するという手法です。 蒸留を行うことで、特定のタスクに対してサイズの大きいモデルから精度を落とすことなくモデルのサイズを小さくかつ高速に動作させることが可能になります。

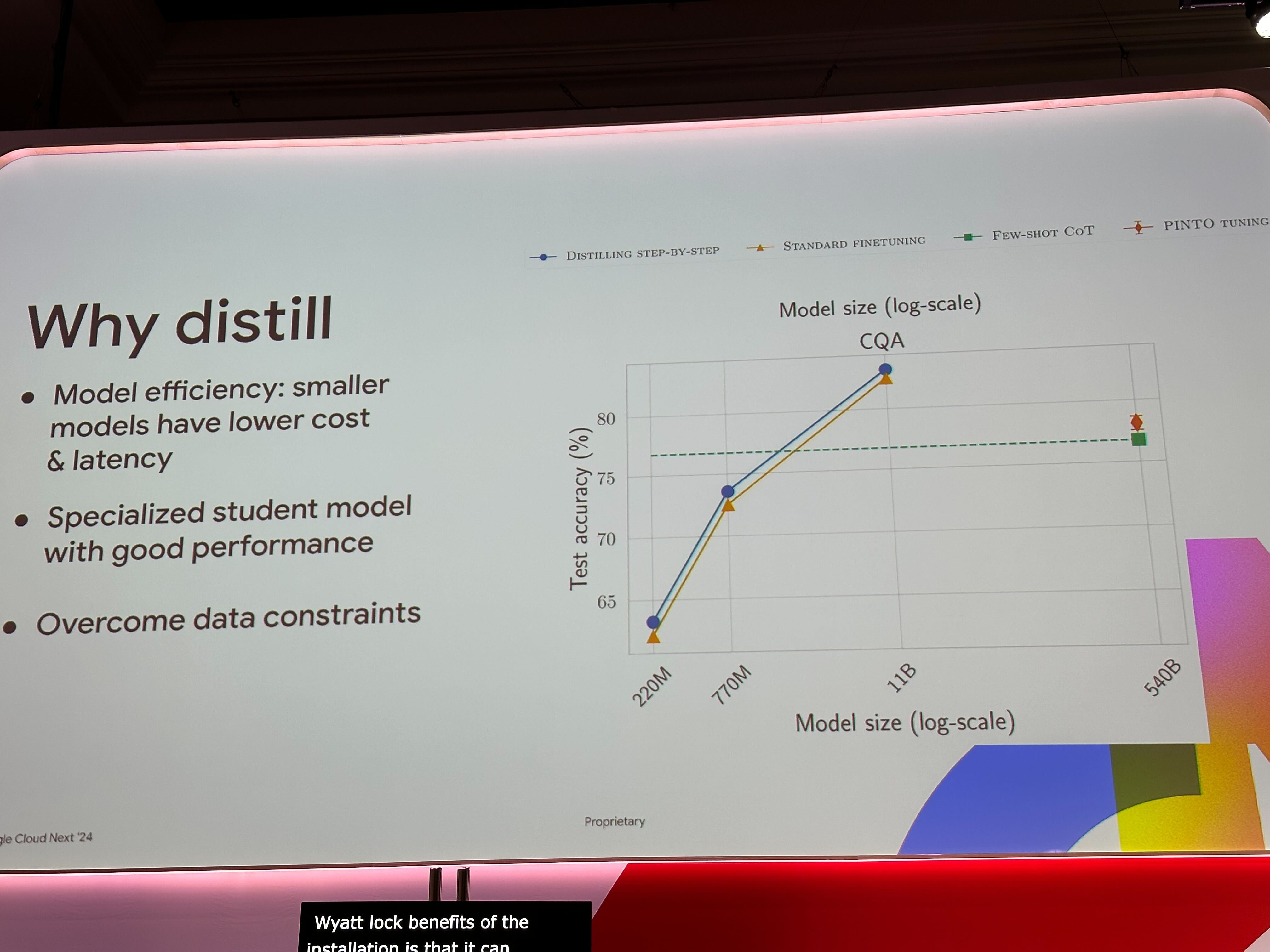
セッション内のデモでは、Gemini 1.0 Pro を Teacher Model、Gemma を Student Model として蒸留を行っていました。 なお、Gemini を Teacher Model とした Tuning は発表時点では Preview です。 Gemma も今回の Next'24 で GA となった軽量のオープンモデルです。別のセッションでは、Gemma を Ollama を使ってローカル PC で動作させていました。 そのまま利用すると当然 Gemini に比べて精度は劣りますが、適切に Tuning 出来ればローカルで動かせるレベルの計算リソースで済むのはメリットが有ると感じました。
GenAI アプリケーションの基本的なアーキテクチャ
GenAI アプリケーションの基本的なアーキテクチャ例として以下が紹介されていました。 実際には MLOps も含めて全体は複雑なアーキテクチャになるかとは思いますが、PoC やシンプルなアプリケーションであればこの構成で十分そうです。
- Cloud CDN (キャッシュ)
- Cloud Run (Application Serve)
- Vertex AI (LLM Serve)
- Cloud SQL (Vector Database)

また、新規データのベクトルデータを追加する際のアーキテクチャとして以下も紹介されていました。データを Cloud Storage にアップロードし、 PubSub を経由して非同期に Cloud Run jobs で Embedding を実行&保存というパターンです。 これも要件次第ですが、そのまま流用できそうで参考になりました。

GenAI アプリケーションの提供
セッション内では、Python は AI モデルの構築をすることに優れており、Go はそのモデルを提供するアプリケーションや開発やモデル構築に入力するデータ加工を行うアプリケーションの開発に優れているという紹介がされていました。
実際データサイエンス周りのエコシステムはやはり Python が強いですし、Jupyter Notebook などでデータの可視化も行いやすいです。 サンプルコードの充実度なども含め簡単なお試しをしたり、PoC を作る目的であれば現時点では Python でも良いかもしれないというのが正直なところです。 一方で Cloud Run などオートスケールするプロダクトを利用していて最低インスタンス数の設定が 0 の場合、スピンアップにあたりやすくなりやすくなります。 結果としてレスポンスに時間がかかり、それがネックになることがあるので最終的にはコンパイラ言語の Go を採用するのも良いのではないかと感じました(弊社の観点でも Python より Go を扱えるバックエンドエンジニアのほうが多いので、メンテナンスの観点でも良さそうではあります)。

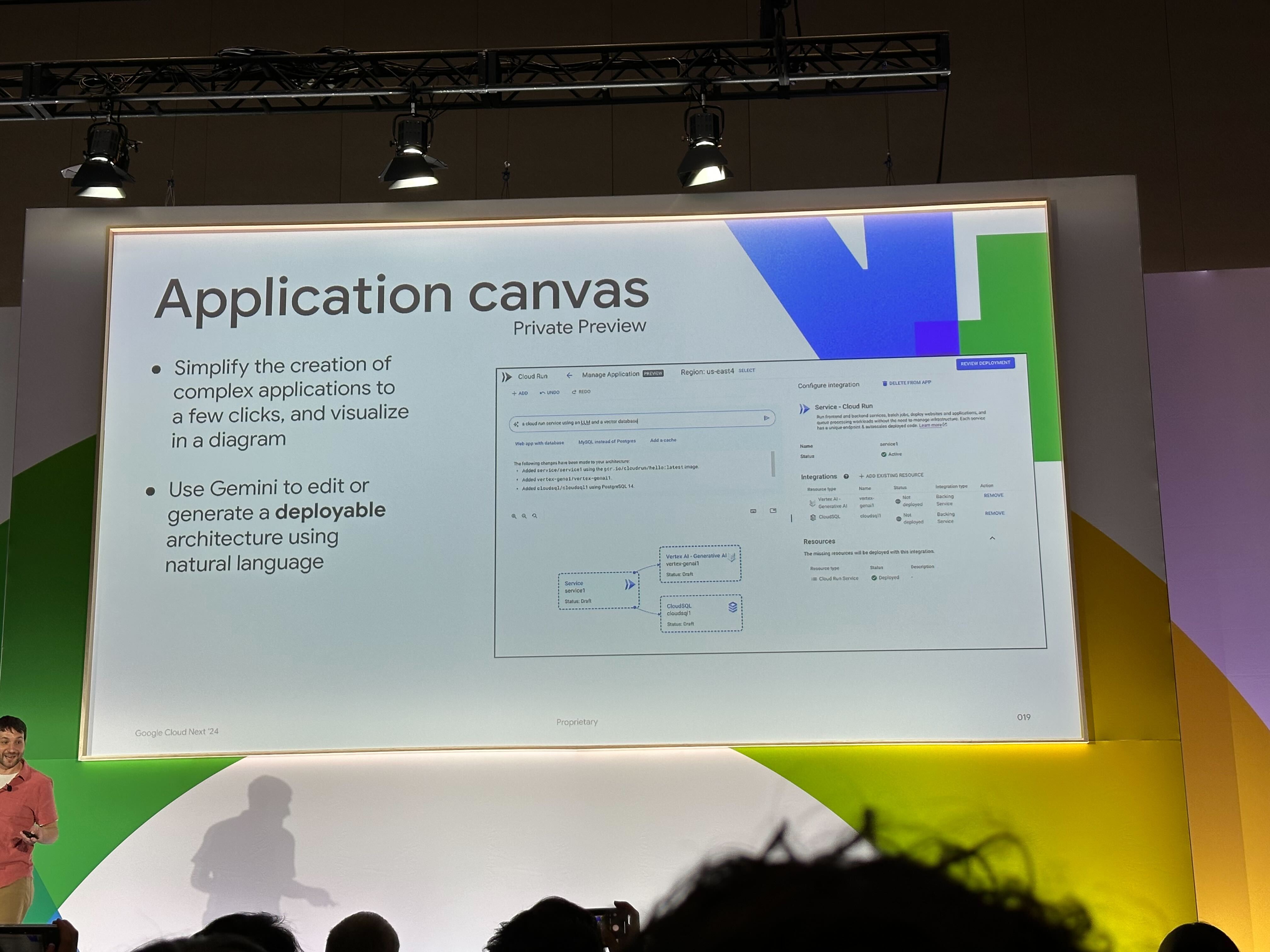
また、Cloud Run 枠としては発表時点では Private Preview でしたが、Integrations に Cloud SQL も追加されていたり、Application canvas という図形式でアーキテクチャデプロイできるようにもなるようでした。この図は手動で編集することもできれば、自然言語から生成を行うこともできます。 最終的には terraform などでの IaC 管理となるかとは思いますが、意外に API の有効化や権限付与が面倒だったりすることもあるので、PoC や試験的に Cloud SQL を Vector Database としてサクッとデプロイして使う際には良いかもしれません。

振り返り
今回の Next'24 を通じて、全体として AI アプリケーションの開発敷居はかなり下がっていたのだと感じました。 単に私が時代遅れなだけなのですが、高性能な GPU を手元に用意してモデルの学習と出力の計算を行っていたときと比べて、ずっとお手軽に高性能なモデルを Vertex AI 上でカスタマイズ・利用できるようになっていました。 加えて、GenAI を利用したアプリケーションの開発や MLOps 環境も既に整い始めており、今後はより AI を活用したアプリケーションが増えていくのではないかとも感じました。
おわりに
本記事では、Google Cloud Next'24 の内容を交えて GenAI アプリケーションについてまとめてみました。 現在社内でも GitHub Copilot Chat などを利用したり、RAG アプリケーションの PoC を行っていたりと AI を活用する流れがあります。 ご興味をもっていただけましたら、以下リンクをぜひご覧いただければと思います。