Data Vault 2.0 の紹介と BigQuery で動く dbtvault のデモ
はじめに
BigQuery で利用可能な dbt のチュートリアルに基づいた dbtvault のデモを公開しました。
https://github.com/belong-inc/dbtvault-bigquery-demo
本記事ではまず Data Vault 2.0 についてなぜわたしたちが採用したいと考えているかを含めつつ説明し、その後に dbtvault のチュートリアルについての説明をします。
背景
Belong では現在データ分析基盤を鋭意作成中です。 データ基盤の構成は基本的には DMBOK に基づきつつ、Data Warehouse のレイヤーではスタースキーマ をベースで考えつつスクラップアンドビルドが可能な PoC ベースで早いフィードバックを得ながら技術検証やアーキテクチャの検証をしています。
このとき、過去のデータの取り込みを行う際に、最新のデータ時点で更新が起きている場合にどうするのか、また日毎のバッチ処理でも将来に渡ってデータを取り込む場合にも dimension テーブルでの内容に更新が起きたらどうするかといった点で議論になりました。
例えば Belong の場合中古携帯端末を扱うので device (product) の dimension が調達/在庫管理/販売など多くの文脈で依存される可能性がありますが、仮に SCD Type2 1 で運用をするのであれば、
device の dimension で更新が起きた時に関係のある全ての fact を更新する必要があるが大変だ、といった議論がされていました。
そんな折、Data Vault 2.0 の存在を知り、調査するにつれてこの仕組みは私達のユースケースに向いているものだという思いが強くなりました。 そして、Data Vault 2.0 を実現するためのフレームワークとして dbt の dbtvault パッケージの存在を知り、手元で試す過程で今回のチュートリアルのデモ作成に繋がりました。
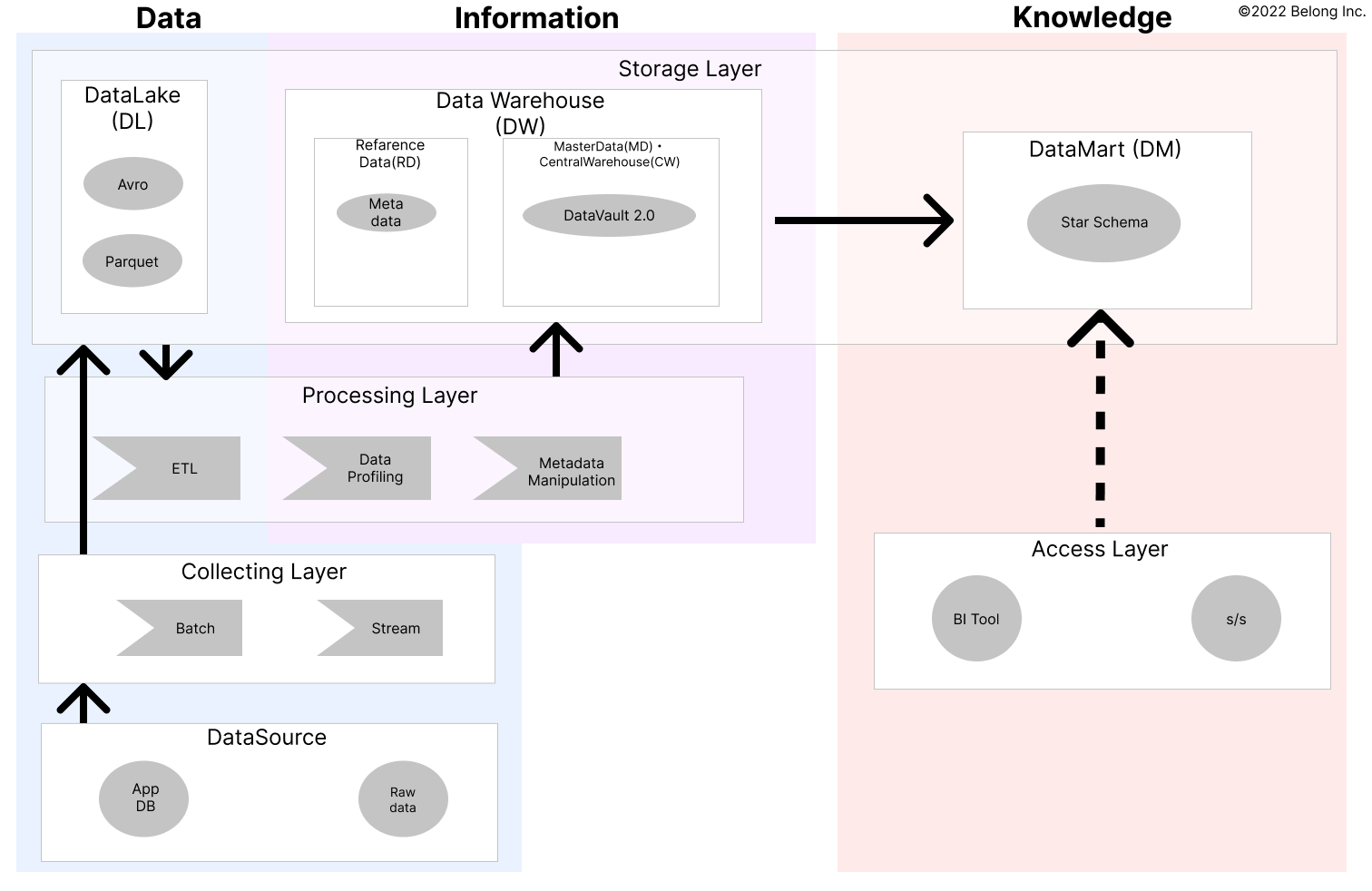 データ処理全体のイメージ2
データ処理全体のイメージ2
Data Vault 2.0 とは
正直な話、私は数日前に Data Vault 2.0 を知ったので現在 Data Vault 2.0 のスペシャリストというわけではありません。 Data Vault 2.0 を学ぶには以下のリソースがとても有用でした。
- What is Data Modeling and How Do I Choose the Right One?
- How to Build a Modern Data Platform Utilizing Data Vault
以下では Data Vault の特徴について軽く触れたいと思います。
Data Vault 2.0 とスタースキーマの構成の違い
以下のように、Data Vault 2.0 のテーブル構成自体はスタースキーマと比較的近いです。
スタースキーマ
- Fact Table
- ビジネストランザクションが発生したときに、ビジネスで記録されたファクト/メトリックを持つ。たとえば、営業部門のファクトテーブルは、売上、収益、販売コストなどのメトリックを記録する
- Dimension Table
- ディメンションテーブルは、ファクトテーブルで測定される情報定義する記述属性を持つ。ファクトテーブルと外部キーによって関連付けられており、分析時の情報の追加やデータ集約の軸に使う
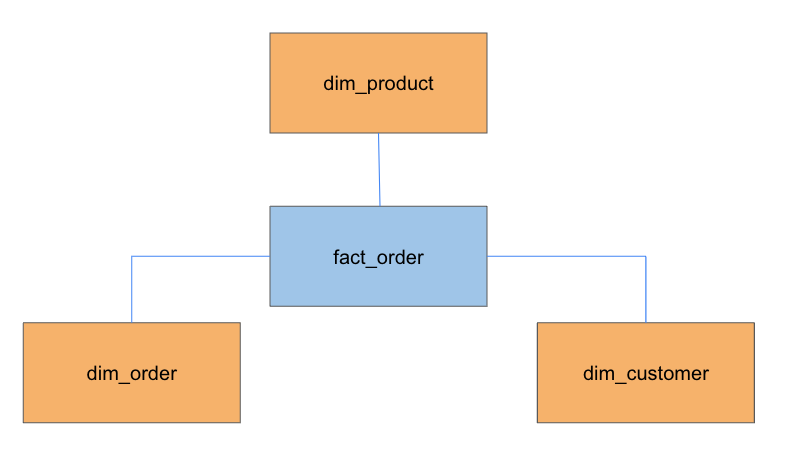
Data Vault 2.0
- Hub
- Hub はビジネスキー(データソースのアプリケーションで利用する ID)など変更されづらい情報のみ持つ
- Link
- Hub 同士や Satellite を含めたビジネスオブジェクトの関連情報を持つ
- Satellite
- ビジネスキーと紐付いたメタデータや記述属性の情報を持つ
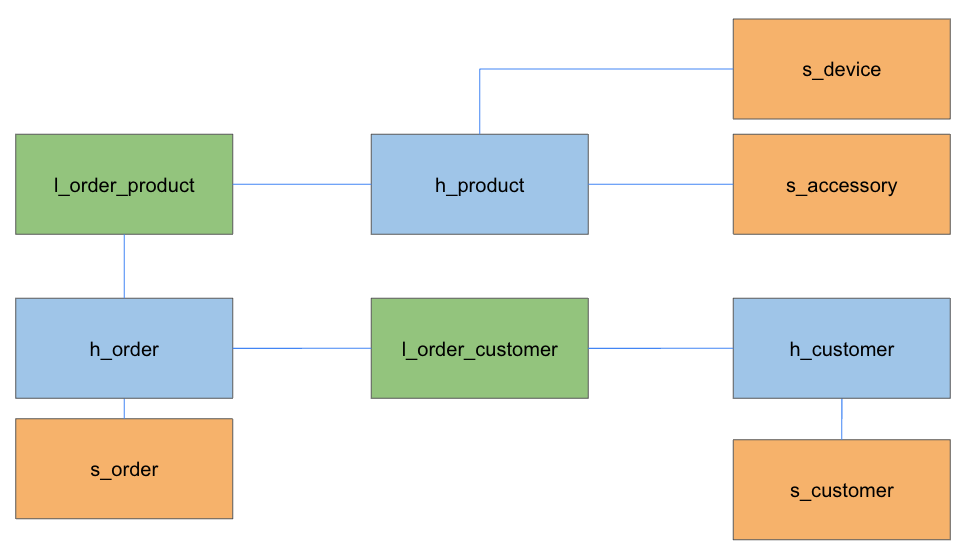
Data Vault 2.0 の特筆するべき特徴と利点
Data Vault 2.0 は運用を楽にできると予想されるいくつかの特徴がありました。
特徴
- テーブルのプライマリキーにはペイロードから生成するハッシュを用いる
- Hub はビジネスキーにより生成されるハッシュキー
- Link は 関連付ける Hub/Satellite の複数のビジネスキーにより生成されるハッシュキー
- Satellite プライマリキーは関連付けられる Hub/Link と同一ロジックのプライマリキー
- データソースで値が更新されたレコードは Satellite に新規レコードして追加
- Satellite は利用するフィールドの値を基に Hash を生成した Hash Diff Key を保持
- 各テーブルは DataSource、Loaded Date Timestamp を必ず持つ
利点
以下では上記で説明した特徴から私達の考える Data Vault 2.0 の利点を説明します。
テーブル間の独立性
Data Vault 2.0 で利用するプライマリキーの値は、ビジネスキー(e.g. アプリ側の RDB の主キー)などデータレイクレイヤー時点で既に存在する情報から導出できるため、各テーブルの行レコードは独立に生成し追加ができます。
スタースキーマの場合はサロゲートキーとして生成したキーをプライマリキーとして利用する事が多く、 dimensions を作成してから fact を作成しなければいけない依存がありますが、
Data Vault の場合は各テーブル並列で作成可能です。
更新管理
Hub や Link テーブルは基本的に 1 ビジネスキー(もしくはビジネスキーのコンビネーション) / 1 レコードの構成となり、何れかのフィールドで更新があった場合は Satellite にレコードを追加します。
Satellite 側では自身のプライマリキーは Hub・Link などの親テーブルのプライマリキーを利用し、同一のビジネスオブジェクトであれば 親テーブル<>Satellite 間で同一のプライマリキーを持つので履歴の管理が容易にできます。
このとき、最新のデータは Loaded Date Timestamp の最新の日付のデータを見つけるか、Load End Date Timestamp で 初期値を 9999-12-31 や null で持ち更新のレコードが入った場合にその日付で埋める仕組みで判別できます。
スタースキーマで SCD Type2 を用いる場合には dimension の値が挿入されると新レコードのプライマリキーを利用するために fact でも新レコードを追加することが多いですが、Data Vault の場合更新の影響は Satellite のみになり、
ビジネスオブジェクトの関連は Hub と Link のみに着目することで重複などを気にする必要がないという点も扱いやすいです。
重複管理
Satellite はビジネスキーを基に生成したハッシュ値であるプライマリキーとは別に利用するフィールドの値を基にハッシュ値を生成した Hash Diff Key を持ちます。
Data Vault 2.0 ではデータソースで更新があった場合、Satellite のみに更新レコードを追加しますが、レコード追加時にこの Hash Diff Key により値変更の有無が判別できます。
例えばデータレイクレイヤーで同一レコードを重複して取得してしまうこともありえますが、Satellite への追加時に既存レコードと追加予定レコードの Hash Diff Key を比較し同一の Key がない場合のみ追加を行うようにすれば
Vault の DW レイヤーでは重複を防ぐことが容易になります。
弱点
ここまで Data Vault 2.0 の良い点に多く触れてきましたが弱点もあります。 Vault の構成的にデータマートのレイヤーでファクトデータの集計を行ったりするのには不便なこともあり、BI ツールなどから利用するテーブルを構成するためには間にスタースキーマを挟む必要があるユースケースがあり得ます。 また、その事による追加のストレージコストが必要となるデメリットも挙げられます。
dbtvault BigQuery Demo
dbtvault は dbt を用いて Data Vault 2.0 を実現するためのフレームワークです。 現在速いスピードで開発が進められているようで、今年 3 月に BigQuery (以下 BQ) の対応が加えられ、 5 月のリリースで BQ の対応機能の範囲が増えています。
この dbtvault は dbt の機能をベースに SQL とテンプレートやマクロを用いて DB のテーブルなどを構成することが出来ます。
公式のチュートリアルも存在しますが、2022-05 時点では Snowflake の利用が前提になっています。
一方で、dbt 自体のチュートリアルは BQ を利用している物があり、dbt-tutorial という BQ の公開データセットも存在します。
やはり GCP のヘビーユーザーとしては BQ を利用したいので、今回は dbt の公開データセットを用いて dbtvault を試せるようなデモを作成しました。
Demo Overview
デモリポジトリ: https://github.com/belong-inc/dbtvault-bigquery-demo
詳細はデモのリポジトリの README に記述していますが、内容は簡単で Hub・Link・Satellite の構成のみを試しています。
データは BQ の公開データセットである dbt-tutorial の customers と orders の 2 つのテーブル(view)を利用して vault を構築します。
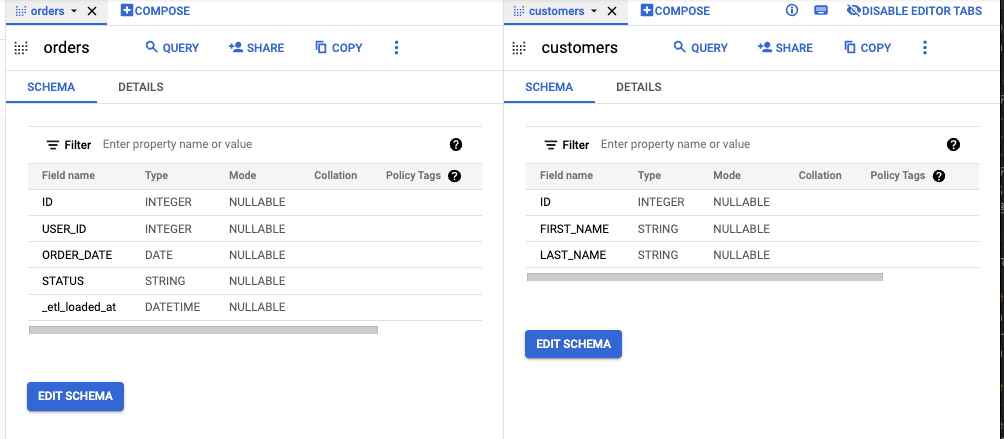
デモの実行後は以下のようなテーブルが作られます。
余談ですが、テーブルの名付けパターンを途中から変更しています。
参照元のテーブルは customers など複数形になっているので raw_staging までは合わせましたが、Link で customers_orders のような形にしたくないという個人的な好みから vault のレイヤー以降からテーブルは単数形になっています。

図にある通り stg のつくテーブル(view)が複数種類存在します。 dbtvault では基の raw data を手元に持ってくるための staging と、基のデータにハッシュ値や vault で必須とされるカラムを追加した staging を用います。
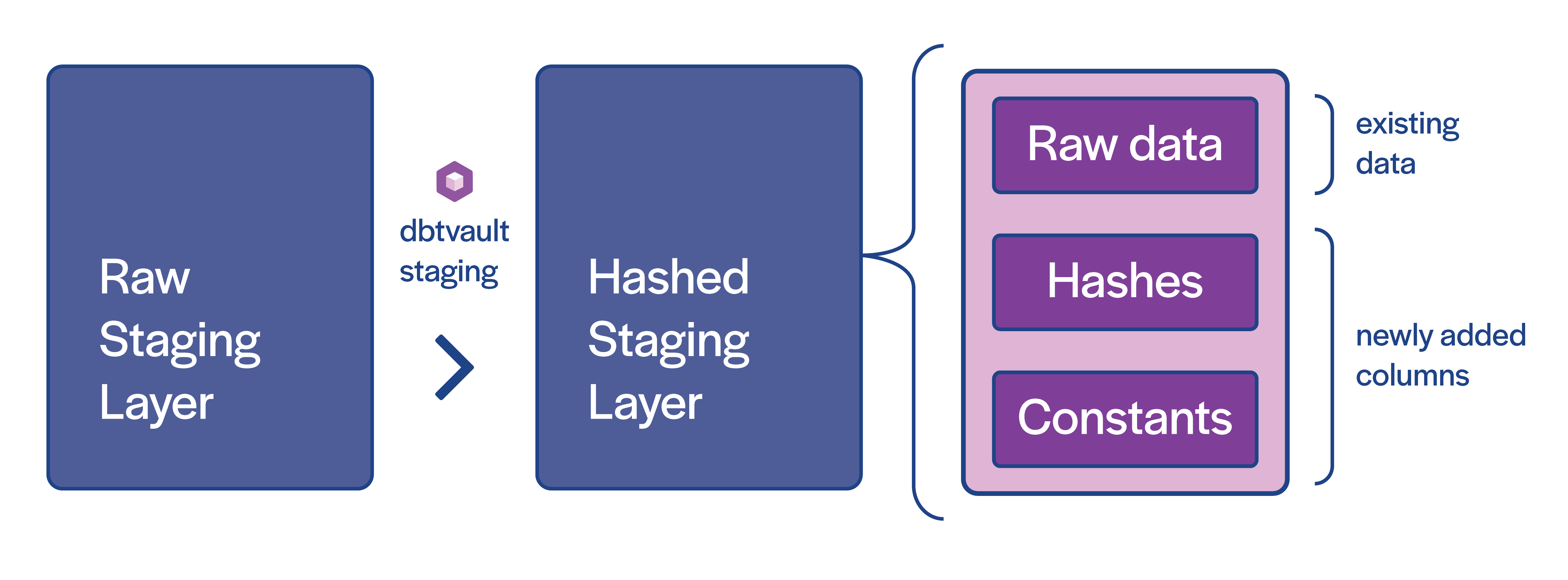 (dbtvault stating tutorial より引用)
(dbtvault stating tutorial より引用)
Hashed Staging Layer さえ作ってしまえば後はシンプルで、Hubs, Links, Satellites をそれぞれの元データを持つ Hashed Staging Layer から取得し挿入します。
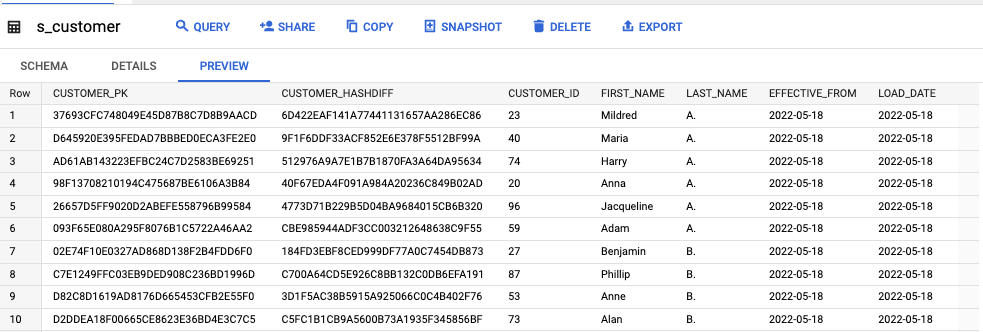
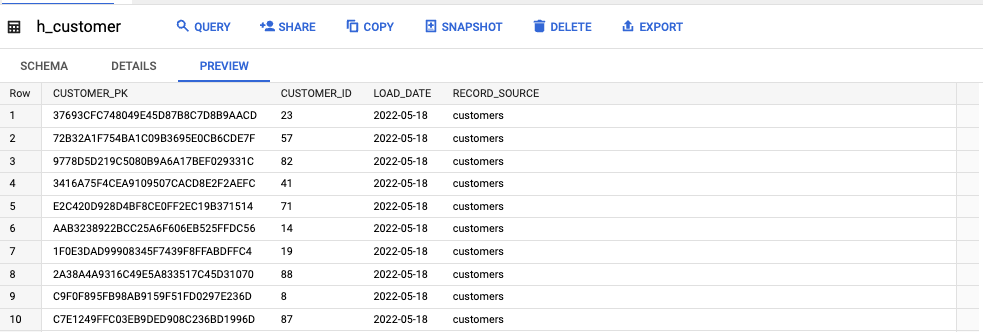
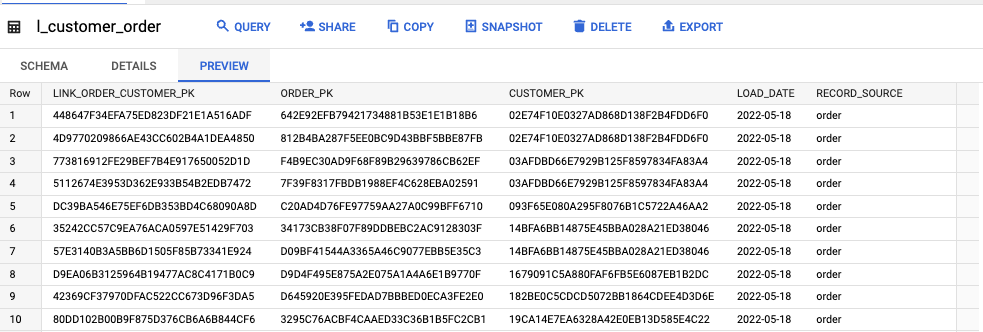
その結果今回は Hub・Link・Satellite がそれぞれ h_*・l_*・s_* と言ったテーブルで表現されています。
s_customer
h_customer
l_customer_order
おわりに
本記事では Data Vault 2.0 の説明と、Data Vault 2.0 を簡単に実現する dbtvault を BigQuery で試すためのデモを掲載したリポジトリの紹介をしました。
dbtvault を利用するととても簡単に Data Vault 2.0 の構成が実現でき、有用なフレームワークということを理解できました。
現在 dbtvault は v0 であり、リリースの度に大きめの変更が入るため個人的には本番での利用は少々待ちたいですが、長期的には 是非利用したいと思えるほどの便利さなので引き続きウォッチしていきたいです。
Belong ではエンジニアを募集しています。今回触れたデータプラットフォーム関連の開発を引っ張ってくれるエンジニアや、Go で API の構築や TypeScript と Next.js でフロントエンドの開発がしたいエンジニアなど様々なポジションでメンバーを募集しています。
もし興味を持って頂けましたら下記のエンジニアリングチーム紹介ページをご確認いただけたら幸いです。
References
- https://www.phdata.io/blog/how-to-model-and-choose-the-right-data-model/
- https://www.phdata.io/blog/building-modern-data-platform-with-data-vault/
- https://www.scalefree.com/scalefree-newsletter/insert-only-in-data-vault/
- https://dbtvault.readthedocs.io/en/latest/
- https://docs.getdbt.com/tutorial/learning-more/getting-started-dbt-core#connect-to-bigquery