Google Cloud で Grounding (RAG) を行うためのリファレンス集
Overview
本記事は 2024 年 4 月において、Google Cloud のプロダクトを用いて RAG (Retrieval-Augmented Generation) を代表とした Grounding を行う方法の調査内容です。
Google もブログやサンプルプログラムなど Generative AI の情報を多く出しており参考になる一方で、
短期間でプロダクト名が変わっていたり、内容が変わってブログからのリンク切れも多いため、調査開始後につまずいてしまうこともあります。
そこで、思い出したときに参照しやすいように、プロダクトの説明・ユースケース例・サンプルコードなどを独断で選び、後で確認したいときに使えるリファレンス集を作りました。
リファレンス集には 3 月頃から調査し、PoC を作成した上で学んだ内容や、 Google Cloud Next' 24 で発表された内容などを含みます。
リファレンス集にのみ興味がある場合は Reference を参照してください。
TL;DR
- Grounding によりより正確でコンテキストを持った回答を生成することが可能
- Google で Grounding で利用しやすいデータストアは次の通り
- Vertex AI Vector Search
- Vertex AI Search
- Database (CloudSQL, Alloy DB, etc...)
- データの範囲・ユースケース・規模によってデータストアの選択を行う
- クイックリファレンス集
Grounding
Grounding (グラウンディング) とは、特定の知識や情報源を用いて LLM にコンテキストを与え、回答や生成内容を裏付けるプロセスを指します。
情報に接地 (ground) していることからそう呼ばれるようです。
ChatGPT や Gemini 等のチャットで用いる、質問内容から追加の情報を検索した結果も含めて言語モデルに情報を与え回答を得る RAG は Grounding の手法の 1 つです。
Grounding のモチベーション
グラウンディングは言語モデルに対して、特定の情報源を用いてコンテキストを与えることで、モデルの回答や生成内容を裏付け、回答の精度を高めたり、範囲を絞り、ハルシネーションが起こりにくくできます。
企業で独自に集めている情報を組み合わせることで、公開情報で学習したモデルだけでは知り得ない情報を踏まえたうえで、特定のドメイン知識に詳しい回答を生成することが可能です。
Grounding のユースケース
Grounding のユースケースでわかりやすいのは発展的な検索と質問応答 (Q&A) です。 Belong でも以下のようなユースケースが想定されます。
- 企業のナレッジブックを用いた社内向けの Q&A チャット
- カスタマーサービスやセールスのアシスタント
- にこスマのおすすめ機種の提案
Grounding の手法
ここでは RAG による Grounding の手法を説明します。
RAG ではその名の通り、言語生成のために情報の取得 (Retrieval) を行います。
具体的には、ユーザーの問い合わせ内容からセマンティック検索を行い情報を取得し、その文書を用いて言語モデルにコンテキストを与える、Embedding により回答を生成します。
セマンティック検索にはベクトルインデックスとベクトルデータベースが用いられることが多いです。
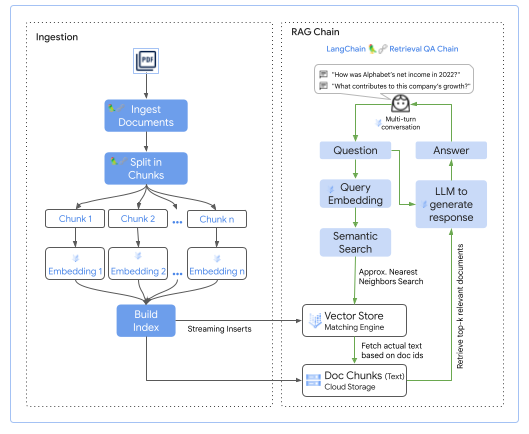
引用: Building Generative AI applications made easy with Vertex AI PaLM API and LangChain
この図は Google Cloud の Vertex AI Vector Search を用いた RAG の Grounding のフローを示しています。
RAG の実現は以下のステップで行います。
- ドキュメントのベクトル化を行いインデックスを構築
- ユーザーの問い合わせ時に内容をベクトル検索し、取得出来た内容を言語モデルに質問と同時に与える
Grounding References
Vector
ここでは Google Cloud で Vector を扱う方法について調査した内容をまとめます。
Vertex AI Vector Search
Vertex AI Vector Search は、Google が開発したベクトル検索技術をベースにしたセマンティック検索ができるプロダクトです。
このプロダクトは発表された当初は Matchig Engine と呼ばれていたため、以前の Google のドキュメントやライブラリを参照する場合には気をつける必要があります。
Google Cloud developers can take the full advantage of Google's vector search technology with Vertex AI Vector Search (previously called Matching Engine)
引用: intro-textemb-vectorsearch.ipynb
このプロダクトを利用するためには次の 3 つのステップが必要です。
- ベクトルの作成
- インデックスの構築
- ベクトル検索
Vector を作成する
ベクトルの作成は文章などからなる文字列を、検索しやすいようにベクトル化することです。
Vertex AI Vector Search を用いてベクトルを作成するのには intro-textemb-vectorsearch のサンプルコードが参考になります。
このサンプルでは textembedding-gecko というベクトル化のために事前学習されたモデルを用いつつ、
vertexai.language_models.TextEmbeddingModel のライブラリを用いて、事前に用意された Stack Overflow の文章をベクトル化します。
langchain 等のフレームワークを用いるとベクトル作成は簡単に出来るのですが、このサンプルではそういったフレームワークの裏側で具体的に何を行う必要があるのかの理解もできます。
実行後は次のような出力が得られます。
入力テキストが次の形だとすると
1. Hello World!
2. Hello Belong
次の JSON のような形で表現されます。embedding がベクトル化された結果です。
{"id": "1", "embedding": [1,1,1,...`]}
{"id": "2", "embedding": [2,2,2,...]}
Vector のインデックスを構築する
文章をベクトル化したら、インデックスを作成し検索可能にします。
Vertex AI Vector Search においてインデックスを利用可能にするためには次の 3 つの手順を踏みます。
- Vector Index の構築
- Index Endpoint の作成
- Index と Index Endpoint を紐づけてデプロイ

引用: Announcing ScaNN: Efficient Vector Similarity Search
ここは先程のサンプル intro-textemb-vectorsearch の後半部分 が参考になります。
ここで気をつける点として、サンプルにある MatchingEngine は deprecated になっているため、少し試すだけなら問題ないですが、
プロダクト利用も踏まえて開発の実装を進める場合には最新の VectorSearchVectorStore を利用する必要があります。
サンプルコードにあるもの
from langchain_community.vectorstores import MatchingEngine
me = MatchingEngine.from_components(
project_id=PROJECT_ID,
region=ME_REGION,
gcs_bucket_name=f'gs://{ME_BUCKET_NAME}',
embedding=embedding,
index_id=ME_INDEX_ID,
endpoint_id=ME_INDEX_ENDPOINT_ID
)
MatchingEngine の実装を見てみると以下のように既に deprecated です。
@deprecated(
since="0.0.12",
removal="0.2.0",
alternative_import="langchain_google_vertexai.VectorSearchVectorStore",
)
class MatchingEngine(VectorStore):
次のステップを踏むと最新の VectorSearchVectorStore が利用できます。 インスタンス生成のためのインターフェイスはほぼ同じですが、GCS のバケットの指定方法が変わっていました。
- import を
from langchain_google_vertexaiに変更 gcs_bucket_nameに与える値からgs://を取り除く
from langchain_google_vertexai import VectorSearchVectorStore
vs = VectorSearchVectorStore.from_components(
gcs_bucket_name=f'{BUCKET_NAME}',
...
)
手順に従い Index をデプロイすると検索可能になります。
この時、Vector の Embedding と元の文章を紐づけるには、id から元の文章を取得出来るようにする必要があります。
langchain はそのような作りになっており便利ですが、詳細は別の機会に紹介します。
Vector を検索する
Vector の検索は次のような形で行います。
- クエリのベクトル化
- ベクトル化されたクエリをエンドポイントに渡し、インデックスから検索
Vertex Vector Search ではベクトルの検索に Google が 2020 年に発表した ANN (Approximate Nearest Neighbor) の新しいアルゴリズム である ScaNN というアルゴリズムを用いており、高速な検索が可能です。
Vertex AI Search
Vertex AI Search(旧称 Gen App Builder の Enterprise Search)は、ウェブサイト、構造化データ、非構造化データを対象とした Google 品質の検索体験を構築できる、デベロッパー向けのフルマネージドプラットフォームです。 Vertex Vector Search はセマンティック検索のみを提供する一方で、AI Search の方はセマンティック検索、キーワード検索、再ランキング、フィルタリングなどを組み合わせた統合検索ソリューションを提供します。
このプロダクトは Web ページや GCS 上の構造化・非構造化データ(e.g. PDF)、CloudSQL や BigQuery 上のデータに加え、3rd Party の Jira や Confluence などのデータをデータストアとして登録できます。
マネージドなプロダクト側で検索インデックスを構築してくれるため、Vector Search の部分で説明した文書のベクトル化と保存・検索などを自身で行いたくない場合には有効なプロダクトです。また、対象ページ全体のインデックスと RAG を前提としたチャンク (ドキュメントを部分事に分けたもの) のインデックスを作成することが可能です。
この記事を書いている時点では Preview の機能も多いですが、フルマネージドで検索から RAG を行う会話機能までをコンソールから構築出来ることを想定されており、今後の発展が楽しみなプロダクトです。
Vertex AI Search の References
Google Cloud のデータベースで Vector を管理する
Google Cloud Next'24 の時点で、次に挙げる Google の主要なデータベースプロダクトの全てにおいて Vector Search が サポートされています(含 Preview)。
Google Cloud データベース、新しい機能で生成 AI アプリの強化に備える
の記事からもわかりますが、Google は Grounding のデータソースを Google のデータストアプロダクトにするために力を入れています。
- CloudSQL
- PostgreSQL
- MySQL
- Alloy DB
- Spanner
- Firestore
- Memorystore for Redis
- BigQuery
- BigTable
ここでは全てのプロダクトの詳細には触れず、以下でエンタープライズの OLTP 系でも使われやすいデータベースである 特に CloudSQL と Alloy DB における Vector Search について触れます。
CloudSQL
CloudSQL for PostgreSQL においては、pgvector というプラグインを用いて Vector Search を行うことができます。 pgvector は、PostgreSQL における Vector Search を行うためのプラグインです。
- Google Cloud データベース、新しい機能で生成 AI アプリの強化に備える
- pgvector、LLM、LangChain を使用して Google Cloud データベースで AI 搭載アプリを構築する
CloudSQL for MySQL も最近になり Vector Search がサポートされました。 こちらにおける Vector Search は、ScaNN ライブラリに基づいて構築されており、複数の ANN インデックス タイプ(Tree-AH、Tree-SQ、自動チューニング付きブルート フォース)をサポートしています
Alloy DB AI
Alloy DB は PostgreSQL であるため pgvector の利用が可能でしたが、Vertex AI との連携をより強めた Alloy DB AI が登場しました。
Alloy DB AI は次のような特徴を持ちます。 Alloy DB は Vector Search においても CloudSQL for PostgreSQL の上位互換であると言えるでしょう。
- pgvector 互換のインデックス
- 最新の ANN アルゴリズム
- 標準の PostgreSQL にある人気のある
HNSW (Hierarchical Navigable Small Worlds)インデックスよりも 4 倍高速なベクトルクエリ - 最大 8 倍高速なインデックス作成
- 標準の PostgreSQL にある HNSW インデックスよりも 3-4 倍少ないメモリを使用
- 標準の PostgreSQL にある人気のある
Google Cloud 上での Grounding におけるデータストアの選択
本記事では 1. Vertex AI Vector Search 2. Vertex AI Search 3. データベース系プロダクト と、大きく分けて 3 つのデータストアを紹介しました。 これらの選択肢は社内外などのユーザーのペルソナであったり、実施したいユースケースにより適しているものが異なります。
簡単にセマンティック検索や検索インデックスの構築を行いたい場合は Vertex AI Vector Search を利用すると良いと思います。
検索用の UI も用意されているため、例えば社内ドキュメントが Google Drive、Confluence、その他サービスなどに散っている場合、それらを Vertex AI Vector Search に登録し、検索を行うようなユースケースに使いやすいです。
一方で、データストアへ自動連携される部分は情報の範囲や取り扱うドキュメントの管理が現状は難しいという特徴もあります。
そのため、管理が簡単さを必要としていたり、検索の品質が十分である場合は Vertex AI Search の利用が良いですが、インデックス化するデータのより高度な管理が必要であったり、Vector Index と他のサービスのメタデータと密に連携したい場合は他のプロダクトの利用が良いのではないでしょうか。
Vertex AI Vector Search はデータを自身で管理する必要がありますが、検索が高速かつ、扱うデータの管理が行いやすいです。 例えばデータベースを運用せず、 Embedding による検索結果と、それと紐づく情報を GCS 上で完結して管理したかったり、Embedding ドキュメントの ID を Key として Key-Value で メタデータ管理を行える場合は Vertex AI Vector Search が適していると思います。
データベース系プロダクトの中でベクトルを扱う場合、データベースを運用する必要がありますが、既存のプロダクト・サービスを管理しているデータベースがある場合、有力な選択肢になります。 なにより、Embedding のレコードとサービスのデータを紐づけることにより、「在庫のある商品の検索・レコメンデーション」や、「特定のメタ情報を持ったレコードの検索」など、既存サービスを拡張するための強力なツールとなります。
おわりに
本記事では Google Cloud における Grounding とプロダクトの選択肢について説明し、リファレンス集を作りました。 Belong でも Grounding を用いたプロダクティビティの向上やプロダクト改善の需要が高まっており、現状 PoC の構築に着手しています。 Python、Langchain、Google Cloud を用いて Grounding を行うサービスを構築したい方はぜひ エンジニアリングチーム紹介ページ をご覧いただき、ご応募いただけたら幸いです。
References
Google Cloud の Generative AI について
- Google Cloud Generative AI Samples - Google Cloud の generative-ai のサンプルが多くある GitHub repo
- Embeddings & Vector Search Samples - 上記 repo の Embedding 周りのサンプル
Grounding の説明
- Vertex AI Embeddings for Text で実現する LLM のグラウンディング - Google Cloud を用いて Grounding を行うための一般論
- Grounding LLMs - Microsoft による Grounding (RAG) の説明
Embedding の説明
- Meet AI’s multitool: Vector embeddings - Vector embeddings 自体の説明
- Scaling deep retrieval with TensorFlow Recommenders and Vertex AI Matching Engine
- Announcing ScaNN: Efficient Vector Similarity Search - ScaNN の論文
Vertex AI Search
Google Cloud のデータストアプロダクトにおける Vector Search
-
Google Cloud データベース、新しい機能で生成 AI アプリの強化に備える - Google Cloud のデータベースプロダクトのベクトル検索の概要
-
Alloy DB
- Alloy DB AI - Alloy DB AI の説明
- Integrate with Vertex AI - Alloy DB と Vertex AI との連携
- ScaNN for AlloyDB Whitepaper - Alloy DB における ScaNN の Whitepaper
-
Spanner
-
Firestore
-
Memorystore for Redis
-
BigQuery
-
BigTable