dbt Materializations はレイヤーによって何を選ぶべきか決まっていることを知っているか
はじめに
Data Platform チーム所属の dach です。
データエンジニアやデータ分析者にとって、dbt を効果的に活用するためには、適切なディレクトリ構造と適切な Materializations の選択が欠かせません。dbt のベストプラクティスでは、staging、intermediate、marts の 3 つのレイヤーを用いてデータ処理を行うことが推奨されています 1。それぞれのレイヤーの役割に沿った適切な Materializations を選択することが重要です。
本記事では、ベストプラクティスに基づくディレクトリ構造に対応する Materializations の選択を、実際の開発を通して得た解釈を添えて解説します。
dbt Materializations はレイヤーによって何を選ぶべきか決まっていることを知っているか
Materializations とはモデルをどのように永続化するかの選択肢
Materializations(マテリアライゼーション)とは、dbt においてモデルを永続化する方法の選択肢です。Materializations は全部で 4 種あり、異なる Materializations の種類を選択することで、データ処理の方法や結果の管理における特定のニーズに対応できます。
以下に、現時点(dbt v1.5)における標準搭載されている2各 Materializations の簡潔な説明とそれぞれの特徴、メリット、デメリットを示します。 ※ dbt v1.6 で Materializations にアップデート3が入るようです。詳細については別途記事にしたいと思います。
| Materializations | 特徴 | メリット | デメリット |
|---|---|---|---|
| view | 実行ごとに View として再構築する | - 常に最新データが参照可能 - 高い柔軟性でモデルの定義を修正可能 | - 参照がある度クエリコストが発生する - データ量の多いテーブルへの処理や複雑な変換処理などの View はクエリに時間がかかる |
| table | 実行ごとに物理テーブルとして再構築する | - クエリの実行パフォーマンスが向上 - 結果を直接参照できるため、分析ツールや macro からの利用が容易 | - 複雑な変換がある場合、テーブルの再構築に時間がかかることがある - 更新が必要な場合には手動で再実行する必要がある |
| incremental | 物理テーブルにレコードを挿入または更新できる | - データ処理の効率化 - 増分蓄積の最適なクエリが自動で生成される | - モデルの定義に依存する変更がある場合には注意が必要 - 追加の構成や戦略の理解が必要 |
| ephemeral | 実行時に一時テーブルとして依存モデルに組み込まれる | - ロジックを再利用可能 - クエリの複雑性を分離できる | - モデルから直接データを参照することができない - デバッグが困難になる可能性がある |
view や table は MySQL などの RDBMS を利用されている方は馴染み深いものだと思いますので、詳細な説明は省きます。 incremental や ephemeral については初めて聞くものかと思いますので、次のセクションでもう少し詳しく解説をしていきます。
次のセクションへと行く前に、Materializations の設定方法を説明します。 Materializations をモデルに適用するには、2 通りのやり方が存在します。
-
yml 上で定義する方法
# dbt_project.yml models: jaffle_shop: staging: +materialized: view -
モデル上で定義する方法
-- models/staging/stg_payments.sql {{ config(materialized='view') }} select * from ...
layer 全体へ適用する場合は yml に記載し、個別に設定する場合はモデルに記載すると記載漏れが防げると思います。
癖のある Materializations たちを使いこなす
Materialization の中でも incremental と ephemeral は特に癖のある Materialization だと言えます。 それぞれの Materializations について、理解してもらうために jaffle_shop をベースに解説していきます。
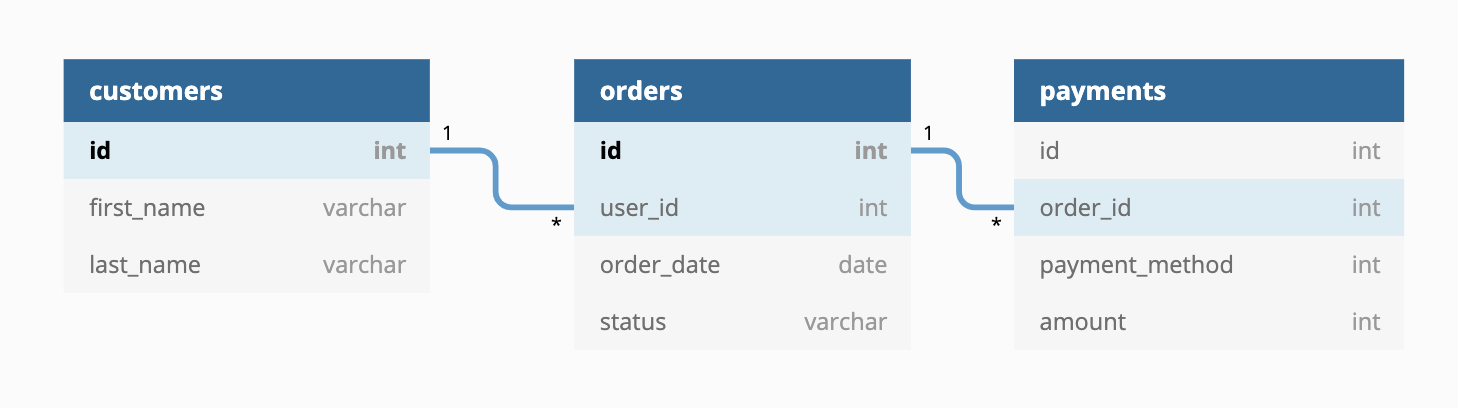 画像引用元: https://github.com/dbt-labs/jaffle_shop
画像引用元: https://github.com/dbt-labs/jaffle_shop
ephemeral はビジネスロジックを抽出するときに使う
まずは ephemeral について解説していきます。
特徴にも記載しましたが、 ephemeral で定義したモデルはテーブルとして記録されません。ephemeral として定義したモデルを別のモデルが呼び出すときに一時テーブルとして組み込まれます。具体的にどういう動きをするか見ていきましょう。
例として、customers と orders を結合して、下記の様に顧客別の注文情報を取得したいとします。
-- customer_orders.sql
{{ config( materialized='ephemeral' ) }}
with customers as (
select * from {{ ref('stg_customers') }}
),
orders as (
select * from {{ ref('stg_orders') }}
),
customer_orders as (
select
customers.id as customer_id,
customers.first_name as customer_first_name,
customers.last_name as customer_last_name,
min(orders.order_date) as first_order,
max(orders.order_date) as most_recent_order,
count(orders.order_id) as number_of_orders
from customers
inner join orders
on orders.use_id = customers.id
group by
customers.id,
customers.first_name,
customers.last_name
)
select * from customer_orders
このクエリを dbt run しても、特に何かを実行したとの記載は出てきません。
(venv) jaffle_shop % dbt run --select customer_orders --profiles-dir .
05:14:56 Running with dbt=1.5.0
05:14:57 Found 6 models, 20 tests, 0 snapshots, 0 analyses, 356 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metrics, 0 groups
05:14:57
05:14:58 Concurrency: 1 threads (target='dev')
05:14:58
05:14:58
05:14:58 Finished running in 0 hours 0 minutes and 1.16 seconds (1.16s).
上記のモデルを参照したモデルの場合、どのようなクエリが発行されるのでしょうか? 先程用意した customer_orders を参照するモデルを準備して、dbt run してみたいと思います。
-
用意する customer_orders を参照するモデル
-- customer.sql {{ config(materialized='view') }} with customer_orders as ( select * from {{ ref('customer_orders') }} ) select * from customer_orders -
実際に流れたクエリを整形したもの (BQ に向けて実行)
/* {"app": "dbt", "dbt_version": "1.5.0", "profile_name": "jaffle_shop", "target_name": "dev", "node_id": "model.jaffle_shop.customers"} */ create or replace view `project_id`.`dataset_id`.`customers` OPTIONS() as with __dbt__cte__customer_orders as ( with customers as ( select * from `project_id`.`dataset_id`.`stg_customers` ), orders as ( select * from `project_id`.`dataset_id`.`stg_orders` ), customer_orders as ( select customers.id as customer_id, customers.first_name as customer_first_name, customers.last_name as customer_last_name, min(orders.order_date) as first_order, max(orders.order_date) as most_recent_order, count(orders.order_id) as number_of_orders from customers inner join orders on orders.use_id = customers.id group by customers.id, customers.first_name, customers.last_name ) select * from customer_orders ), customer_orders as ( select * from __dbt__cte__customer_orders ) select * from customer_orders;
__dbt__cte__customer_orders という名称の一時テーブルとなって登場しました。
view や table, incremental によって生成されたテーブルを参照する場合、select * from stg_orders の様に単にテーブル名が入ります。しかし、ephemeral を指定したモデルの場合は実体化されず、クエリとして存在するのみとなっています。
そのため、複雑な結合や集約をするモデルを作成する場合のロジック分割に役立ちます。例では簡単なクエリでしたが、1 つのモデルを生成するために複数の集計や集約などの処理があることを考えます。それらを 1 モデルのファイルに記載した場合、とても長いファイルが誕生することとなり、運用保守性が著しく下がります。 ephemeral を用いずに view や table を指定した場合はどうでしょうか?こちらは単純に運用保守性が下がるとは断定出来ませんが、多くの分割がされた場合はトレースがしづらくなる可能性があります。下記にモデルを生成するために複数のファイルに分割した場合の例を提示します。モデルを生成するためにどのロジックが関連しているのか、ロジックが多ければ多いほどトレースが辛くなることになると思います。 ただし、ephemeral は実体化されないため、デバッグがし辛いという欠点もあります。そのため、利用する場合はトレードオフを理解した上で、多用しないようにする必要があります。
# モデルのために複数の実体化をした例
# どのモデルにどのロジックが関連しているのか、コードやリネージを見ないと追いきれない
- dataset: marts
- モデル A
- モデル B
- dataset: intermediate
- ロジック A
- ロジック B
- ロジック C
- ロジック D
- ロジック E
- ロジック F
- ロジック G
- ロジック H
- ロジック I
incremental は定期的に更新があるデータ量の多いテーブルを保持するときに使う
次に incremental について解説していきます。
incremental はデータの増分管理をいい感じにしてくれるため、イベントテーブルなど定期的に更新があるデータ量の多いテーブルを保持するときに使うと効果を発揮する Materialization です。
incremental を選択したモデルは初回実行時には「テーブル作成 & データ挿入」が行われ、次回以降では所定の設定に合わせた「データ更新 or DELETE & INSERT」が実行されます。どの様に増分データを既存テーブルに処理するか、ということを制御する重要な概念として、incremental_strategy というものがあります。Adapter によっても選択できる戦略が異なる4ため、注意が必要です。詳細について説明するととても長くなるため、ここでは設定方法の概要だけ紹介します。(詳細については別途記事にしたいと思います)
-
incremental を指定する場合は
materialized='incremental'を指定する{{ config( materialized='incremental' ) }} select * from ... -
incremental_strategy の選択は config 内で行い、strategy によって必要な設定を追加する
-- 例: DELETE & INSERT を行う戦略を選択した時の例 {% set partitions_to_replace = [ 'timestamp(current_date)', 'timestamp(date_sub(current_date, interval 1 day))' ] %} {{ config( materialized='incremental', unique_key = 'customer_orders_sk', incremental_strategy='insert_overwrite', partition_by ={ "field": "most_recent_order", "data_type": "DATE", "granularity": "day" }, partitions = partitions_to_replace, on_schema_change = 'append_new_columns' ) }} -
一意なキーを定義する (重複したデータを作らないため)
-- (前略) {% set surrogate_key_fields = [ 'customer_id', 'number_of_orders', 'most_recent_order', ] %} _customer_orders as ( select {{ dbt_utils.generate_surrogate_key(surrogate_key_fields) }} as customer_orders_sk, * from {{ ref('customer_orders') }} ) select * from _customer_orders -
選択した incremental_strategy に合わせて dbt が最適なクエリを compile してくれる(参考: Bigquery Adapter の場合)
Materializations とレイヤーの関係
最後に各レイヤーでどの Materializations を選択すべきかを解説します。 dbt のベストプラクティスでは、各レイヤーに適した Materializations を選択することが推奨されています。
- staging: view
- intermediate: ephemeral / view
- marts: view / table / incremental
ベストプラクティスにおけるディレクトリ構造について知りたい方は、過去に「ディレクトリ構造から学ぶ dbt ベストプラクティスのすゝめ」という記事で紹介していますので、是非そちらもご参照頂ければと思います。
以下に、解釈を交えながらそれぞれのレイヤーで何故対象の Materializations を選択すべきかを解説していきます。
Staging レイヤー
staging レイヤーでは、DataSource からデータ抽出・整形することが目的です。ここでは可能な限り最新のデータを参照する必要があるため、view を選択することが最適です。table を選択することも可能ですが、dbt run が実行されるまでデータの更新がされない状態となります。また、クエリコストやクエリの負荷に関しては、基本的にはデータソースへの参照を適切に制限することで制御できますので、特別な理由がなければ view を選択すると良いと思います。
intermediate レイヤー
intermediate レイヤーでは、公式でも言われているように基本的には ephemeral がおすすめです。ただし、dbt-utils パッケージを使用する際には、実体を持たないと参照できないマクロが存在する5ため、必要に応じて view を選択することもあります。適切な使い分けを行いましょう。
marts レイヤー
marts レイヤーでは、原則として view で書くことが推奨されています。特に強い制約がなければ、 view を選択して開発を行うことが良いと思います(例として、開発の初期段階でリネージが変更される可能性がある場合や、DataSource 自体のデータ量が少なくかつ必要無データを全期間保持している場合、クエリのコストや負荷・実行時間を考慮する必要がない場合など)。ただし、これらの要件に課題がある場合は、table を検討し、table でも実現できないことを考慮した上で、必要な場合は incremental を考慮するようにします。 仮に、初期段階で incremental を選択した場合、モデルの変更が発生する度にデータの洗い替えや関連するモデルの変更、及びテストの変更などで大きく開発コストがかかることがあります。view や table でも関連するモデルの変更及びテストの変更はありますが、incremental モデルの設計は他のモデルに比べて大変であるため、変更があった場合の影響は他の Materializations よりも大きくなります。そのため、可能であるならば、view や table で実現することをまずは検討することを推奨します。
まとめ
本記事では、dbt における Materializations と、公式のベストプラクティスにおける各レイヤーで何を選択するかについて紹介しました。incremental の詳細については今回説明を割愛しております。別途記事を公開予定ですが、詳細が気になった方は是非公式サイトをご参照頂ければと思います。
Data Platform チームでは、よりスピーディーにより高品質なデータを提供できるようにするメンバーを更に募集中です。興味を持ってい頂けた方は是非以下もご覧頂ければ幸いです
Footnotes
-
独自の Materializations を作ることも可能(参照:Creating new materializations) ↩
-
Materialized Views が対応される予定とのことです。 ↩
-
https://docs.getdbt.com/docs/build/incremental-models#supported-incremental-strategies-by-adapter ↩