ディレクトリ構造から学ぶ dbt ベストプラクティスのすゝめ
Overview
データエンジニアやデータ分析者にとって、dbt はとても便利なツールであることは言うまでもありません。しかし、dbt は使い方を誤るとデータ品質の低下や開発プロセスの遅延を引き起こす可能性があります。Belong では 2022 年にデータプラットフォームチームを立ち上げ 1 、同じ年の後半から dbt を使い始めました。 本記事では、ディレクトリ構造を題材に、開発を通して実感した dbt のベストプラクティスを遵守することの重要性をお伝えします。
ベストプラクティスのすゝめ
ベストプラクティスとは最良の方法である
dbt の開発だけに限った話ではないですが、守破離の「守」をマスターすることはとても大事なことだと言えます。そのことを今回は、ディレクトリ構造を題材に考えてみます。 dbt に限らず開発において、ディレクトリ構造は非常に重要な要素です。何故ならばディレクトリ構造はプロジェクトの可読性、保守性、拡張性に直結するからです。守破離を守らないと具体的にどういう問題に直面するか、私達の例を元に解説していきたいと思います。
まずは私達のデータ基盤の構成図について紹介します。どのような試行錯誤の元このような構成になったかは、以前、弊社 CTO が公開した記事「Belong のデータプラットフォームチーム立ち上げ」を御覧ください。
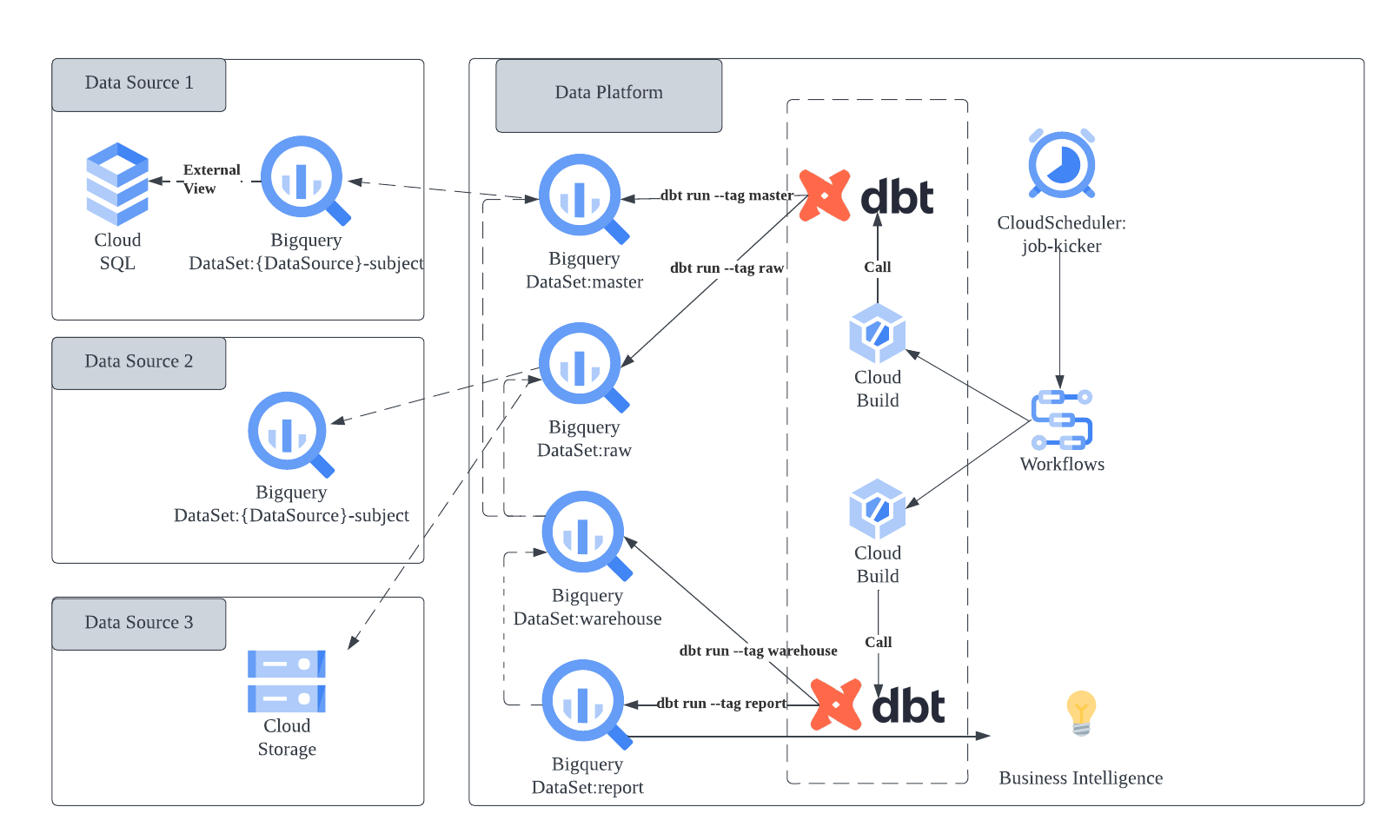
jaffle shop をお借りして、ディレクトリ構造がどのようになるのか今回は /models に限定して見ていきます。
上記構成を実現するために、私達が取ったディレクトリ構成は下記の形となります。ポイントとしては、/models 直下のサブディレクトリ( dbt におけるレイヤー)と Dataset を一致させるように構成してるところです。レイヤーはそれぞれ、DataSource からの抽出先を raw もしくは master、加工済み時系列データの蓄積を warehouse、ユーザーに提供するデータを report に置くこととしています。
この構成で起こった問題として、プロジェクト内のファイルやディレクトリの役割が分かりにくくなり、理解するために時間がかかったりメンバー間で認識がずれる要因にもなりました。結果として、データの関連性が複雑になるため保守性が低下し、拡張性も制限されました。
jaffle_shop
(省略)
├── models
│ ├── master
│ │ ├── [テーブル].sql
│ │ ├── schema.yml
│ │ └── sources.yml
│ ├── raw
│ │ ├── [テーブル].sql
│ │ ├── schema.yml
│ │ └── sources.yml
│ ├── report
│ │ ├── [テーブル].sql
│ │ └── schema.yml
│ └── warehouse
│ ├── [テーブル].sql
│ └── schema.yml
(省略)
上記構成に対し、ベストプラクティスでは大きく staging, intermediate, marts の 3 つのレイヤーに分けています。( utilities というフォルダもありますが、今回は割愛します)
以下は dbt のベストプラクティスから拝借した /models 配下の一例です。
jaffle_shop
(省略)
├── models
│ ├── intermediate
│ │ └── [エンティティ]
│ │ ├── _int_[エンティティ]__models.yml
│ │ └── [テーブル].sql
│ ├── marts
│ │ └── <エンティティ名>
│ │ ├── _<エンティティ名>__models.yml
│ │ └── <テーブル名>.sql
│ ├── staging
│ │ └── [ソース]
│ │ ├── _[ソース]__models.yml
│ │ ├── _[ソース]__sources.yml
│ │ ├── base
│ │ │ └── base_[ソース]__[コンセプト].sql
│ │ └── stg_[ソース]__[エンティティ]s.sql
│ └── utilities
│ └── all_dates.sql
(省略)
パット見ただけでも使われている名称や規則が違うことがわかります。ベストプラクティスではどういう意図があるのでしょうか? 次に、各フォルダにおける役割やルールを簡単に説明します。
変換プロセスの先陣を担う staging
staging は、DataSource からデータを取り込むために使用されます。通常、各 DataSource ごとにサブディレクトリが切られ、データのクレンジング、変換、整形が行われます。注意するポイントは、2 つあります。1 つ目は、staging では DataSource からデータを「抽出するだけではない」ということ。2 つ目は「View Table として定義すること」です。DRY 原則を意識することが staging では特に重要となります。
コードを DRY に保つために、同じ変換を複数回しているようなケースは staging に記載します。オーソドックスな変換として、リネーム、キャスト、計算、分類(集約はしません)があります。例えば、公式に記載されている下記のようなコードを書きます。
-- stg_stripe__payments.sql
with
source as (
select * from {{ source('stripe','payment') }}
),
renamed as (
select
-- ids
id as payment_id,
orderid as order_id,
-- strings
paymentmethod as payment_method,
case
when payment_method in ('stripe', 'paypal', 'credit_card', 'gift_card') then 'credit'
else 'cash'
end as payment_type,
status,
-- numerics
amount as amount_cents,
amount / 100.0 as amount,
-- booleans
case
when status = 'successful' then true
else false
end as is_completed_payment,
-- dates
date_trunc('day', created) as created_date,
-- timestamps
created::timestamp_ltz as created_at
from source
)
select * from renamed
コード引用元: https://docs.getdbt.com/guides/best-practices/how-we-structure/2-staging#staging-models
DataSource 上に存在する複数のテーブルを結合することで、必要なデータが取れるようなケースの場合はどうするのでしょうか。その答えは、base モデルを構築することで解消されます。解説やサンプルコードが長くなるので今回は説明しませんが、気になった方は公式ドキュメントを参照していただければと思います。
これにより、staging 上でデータの最小構成のモジュールが作成されます。私たちが適用していたモデルと比較すると、raw (+ subject という、DataSource 上に作成した特定のコンテキストでデータをまとめたもの) が近いように思えます。しかし、どこで変換を行うのか責務が明確であること、コードが DRY に保たれること、そして開発が全てデータプラットフォームに集約することから、ベストプラクティスを採用すると保守性と拡張性が高いことがわかります。
ビジネスドメインごとの明確な目的を実現する intermediate
ビジネスドメインごとの明確な目的を実現するために intermediate は存在します。intermediate の目的は、marts から複雑さを解消することです。intermediate にモデルを作成する場合は、ビジネス上の関心領域ごとにサブディレクトリを切ります。staging とは異なり、モデルを DataSource ではなくビジネス上の関心領域に適合するように構築することに注意してください。また、intermediate は少数のモデルを扱う場合は不要です。公式では、marts のモデルが 10 個未満でそれらの開発と使用に問題がない場合は、intermediate は不要であると記述されています。
intermediate モデルを構築する場合、公式に記載されているコード例は下記となります。 構築する利点は複雑あるいは理解が難しいロジック部分を marts から分離することで、保守性が上がることです。私たちが適用していたモデルと比較する構成が存在しないため説明は省略します。詳しく気になる方は公式ドキュメントを見ていただければと思います。
-- int_payments_pivoted_to_orders.sql
{%- set payment_methods = ['bank_transfer','credit_card','coupon','gift_card'] -%}
with
payments as (
select * from {{ ref('stg_stripe__payments') }}
),
pivot_and_aggregate_payments_to_order_grain as (
select
order_id,
{% for payment_method in payment_methods -%}
sum(
case
when payment_method = '{{ payment_method }}' and
status = 'success'
then amount
else 0
end
) as {{ payment_method }}_amount,
{%- endfor %}
sum(case when status = 'success' then amount end) as total_amount
from payments
group by 1
)
select * from pivot_and_aggregate_payments_to_order_grain
コード引用元: https://docs.getdbt.com/guides/best-practices/how-we-structure/3-intermediate#intermediate-models
特定のエンティティを表現する marts
marts は、ユーザーから唯一参照可能なレイヤーで、特定のエンティティ(コンセプトとも呼ばれます)概念を独自の粒度で表現します。エンティティレイヤーやコンセプトレイヤーとも呼ばれます。marts のモデルは、wide-table 2 によって非正規化されたモデルで設計され、誰かが必要とするすべての情報を提供できるようにします。
公式に記載されているコード例は下記となります。
-- customers.sql
with
customers as (
select * from {{ ref('stg_jaffle_shop__customers')}}
),
orders as (
select * from {{ ref('orders')}}
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders,
sum(amount) as lifetime_value
from orders
group by 1
),
customers_and_customer_orders_joined as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders,
customer_orders.lifetime_value
from customers
left join customer_orders on customers.customer_id = customer_orders.customer_id
)
select * from customers_and_customer_orders_joined
コード引用元: https://docs.getdbt.com/guides/best-practices/how-we-structure/4-marts#marts-models
また、マテリアライゼーションに関する一般的な経験則として、View Table から始め、次第に実テーブルまたは増分モデルへシフトするのが良いとされています。具体的な目安としては、クエリを実行するのに時間がかかりすぎたら実テーブルとして構築し、その後、テーブルの構築に時間がかかりすぎて実行が遅くなる場合は、増分モデルとして構成する、といった流れになります。
私たちが適用していたモデルと比較すると、warehouse と report を組み合わせた形が近いように思えます。しかし、ユーザーが参照できる範囲が明確であることやマテリアライゼーションが明示的であること、またどのような変換をどこに入れるのかが明確なところから、ベストプラクティスを採用するほうが保守性が高いことがわかります。
私たちが適用していたモデルが全て悪いということではないですが、ベストプラクティスを採用することで明確な基準や先人たちの知見を活かすことができるため、守破離の「守」を明確に破る必要が出るフェーズに入るまでは、ベストプラクティスに準拠することが多くのメリットを享受できるということがわかりました。
Conclusion
本記事では、dbt を利用してデータパイプラインを構築する際には、公式のベストプラクティスを理解しておくことの重要性について紹介しました。各フォルダにはそれぞれ守るべきルールが他にもありますが、今回詳細は割愛しております。詳細が気になった方は是非、ベストプラクティスを見ていただければと思います。
データプラットフォームチームでは、よりスピーディーにより高品質なデータを提供できるようにするメンバーを更に募集中です。一緒にデータ分析基盤を作りたいと思っていただけた方はもちろん、上のアーキテクチャをみて気になった方、など話してみたいといった方のカジュアル面談などもお待ちしています...!