Belong のデータプラットフォームチーム立ち上げ
はじめに
Belong は 2022 年にデータプラットフォームチームを立ち上げ、データ分析基盤の構築に着手しました。 本記事では Belong におけるデータプラットフォームの需要に触れたあと、チームを立ち上げてからの紆余曲折、具体的には当初は BigQuery Dataproc Serverless for Spark を試したりしつつも現在の dbt を用いたアーキテクチャに至った過程などについて触れます。
データ分析基盤を作るモチベーション
データを利用して効率的に事業を進めたい、リソースを適切なタイミングで適切な場所に投入したいとどの事業責任者も考えている課題だと思います。
Belong は 2019 年にビジネスを開始し、私が 2020 年から入社したあとにエンジニアリングの力を使ってサービスを開始・改善してきましたが、エンジニアリングとしてデータ活用の領域には手を出し切れていませんでした。
特に 2022 はにこスマがヘッドレスの Shopify として稼働し始め、にこスマ買取は多くのパートナー様と連携を始め規模を拡大した事に加え、
法人向けビジネスも順調に拡大し、「取引を始め継続する」という状態から「調達・販売の最適化を行い上手く取引を行う」という状態を目指す規模への成長を見込んでいました。
これまでも日々の在庫状況や売上・費用などの数字を活用してサービス戦略を練ってはいたのですが、IT リテラシーがかなり高く s/s や BI ツールなどの色々な道具を高度に使いこなす経営陣や事業責任者の人手に頼っており、
属人化やデータを連携するまでの手間が課題でした。
そこで、エンジニアリングでは自動でデータの収集・加工・集計などを行い、日々使うデータの生成を行う基盤を構築することを目的としたデータプラットフォームチームを立ち上げました。
データ基盤で扱いたいデータ
Belong のデータのユースケースは以下が大きなテーマです。
- 端末価格データ
- ユーザーデータ
Belong は中古端末を扱っているため、端末価格データに対する取り組みは新品のみを扱うより複雑になります。
調達・販売価格共に市場の動向に左右され、扱う端末の種類も年を経るごとに増えていきます。
どの端末をいつ頃に誰から調達し、国内・国外を含めた個人向け・法人向けのどこのチャネルに販売すると利益を最大化出来るかを考える必要があります。
これらの事を考慮すると、端末価格データに関しては以下のようなユースケースに分けられます。
- モデル毎の価格データ
- 販売チャネル毎の価格データ
- 調達チャネルごとの価格データ
- 価格データの時系列推移
ユーザーデータに関しては、サービスにおけるユーザーの行動をアナリティクス情報から解析し、サービス内の導線の見直しやユーザーが知りたい情報を適切に配置するなど、 サービス品質の向上に繋げるためのものです。
データの利活用を行うには以下の図のピラミッドに表現される様な要素が必要だと言われています。 Belong ではこれまでに各サービスでデータの収集は出来ていたので、それらを統合し集計などをしての可視化までをまずは目指しました。
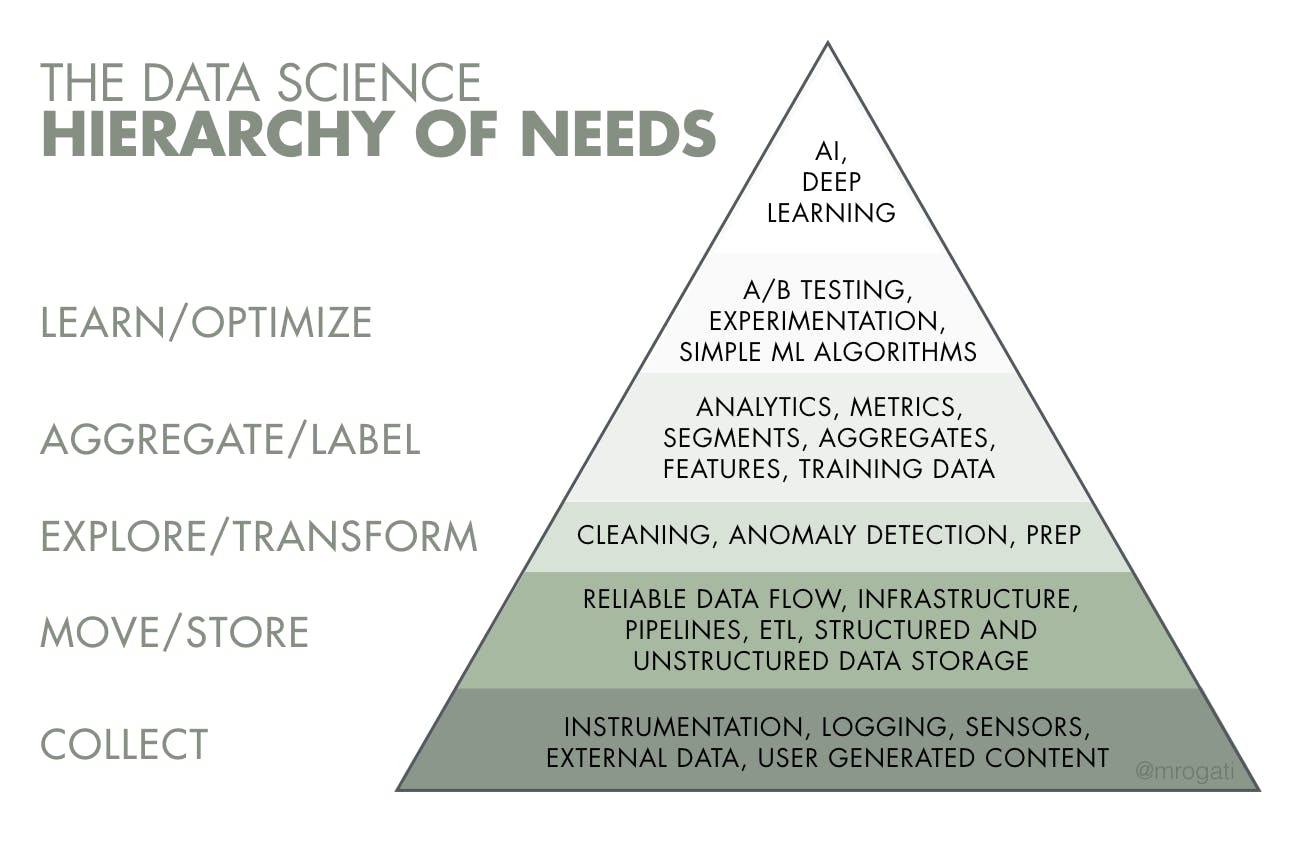
引用: https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007
チームの立ち上げとデータ分析基盤の構築
データプラットフォームチームを立ち上げて順調に良いものが作れたらよかったのですが、そうはいきませんでした。
チーム立ち上げ当初は社内のメンバーでフルで担当に付けられたのは 1 人だけでした。
以前からやり取りのあった協力会社のメンバーと共に動いていましたが DWH を作ったことのある専門家は不在で、経験者がチームに入ったのはプロジェクトが立ち上がり暫く経ってからでした。
私自身、データ基盤の利用や巨大オンプレ Hadoop 系サービスの一部の構築経験はありましたが、「データ基盤は データレイク、データウェアハウス、データマートの概念が有りデータのフェーズごとにデータの持ち方を変える」
のような教科書的な知識がベースで自分でゼロから構築して運用した経験はありませんでした。
(チーム立ち上げに伴う情報整理のメモが残っています Link1, Link2)
そこで、メンバーと DMBOK を読んだり、The Modern Data Stack に関わる記事を色々読み知見を蓄え、まずは PoC 的にデータ分析基盤を構築することにしました。
初期構想の失敗
結論から言うと初期構想は失敗しました。 当初の考えとして、少ないメンバーで開発を行う必要もあるためシステムは運用の手間の少ないサーバーレスのプロダクトをベースに考えていましたが、 同時に、これから多くのデータを扱う可能性があるため大規模データの処理にも耐えられる様な形にしたいと考えていました。
開発、運用、データの性質を考えつつ、柔軟なデータ加工の需要にも対応したいという思いから、早すぎる最適化というのは頭にありつつも初期構想では当時 GA 1 になったばかりであった Dataproc Serverless for Spark をベースとした基盤を考えました。
初期構想を考えていた頃の図
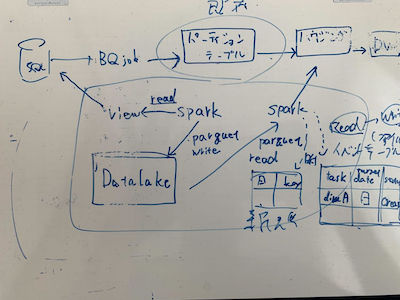
しかし作り始めると課題が見え始め、詳細は省きますが期待していなかった部分でデータの変換が繰り返し必要になるなど、データメンテナンスなどの運用コストも大変そうであることが見えてきました。
端的に表現するとオーバーエンジニアリングを行っており、要望されているものは実現可能であり、扱えるデータの規模や柔軟性という面で構成も悪くないものの、チーム規模からすると運用負荷が高かったのです。
このまま運用の苦しさを抱えたまま本番化するか、構成を考え直すか悩んだ結果、構成をシンプルにし、ユーザの望むユースケースを素早く出し、ビジネスインパクトを早く出しやすい構成を考えることにしました。
野望込みで当時目指したかった姿
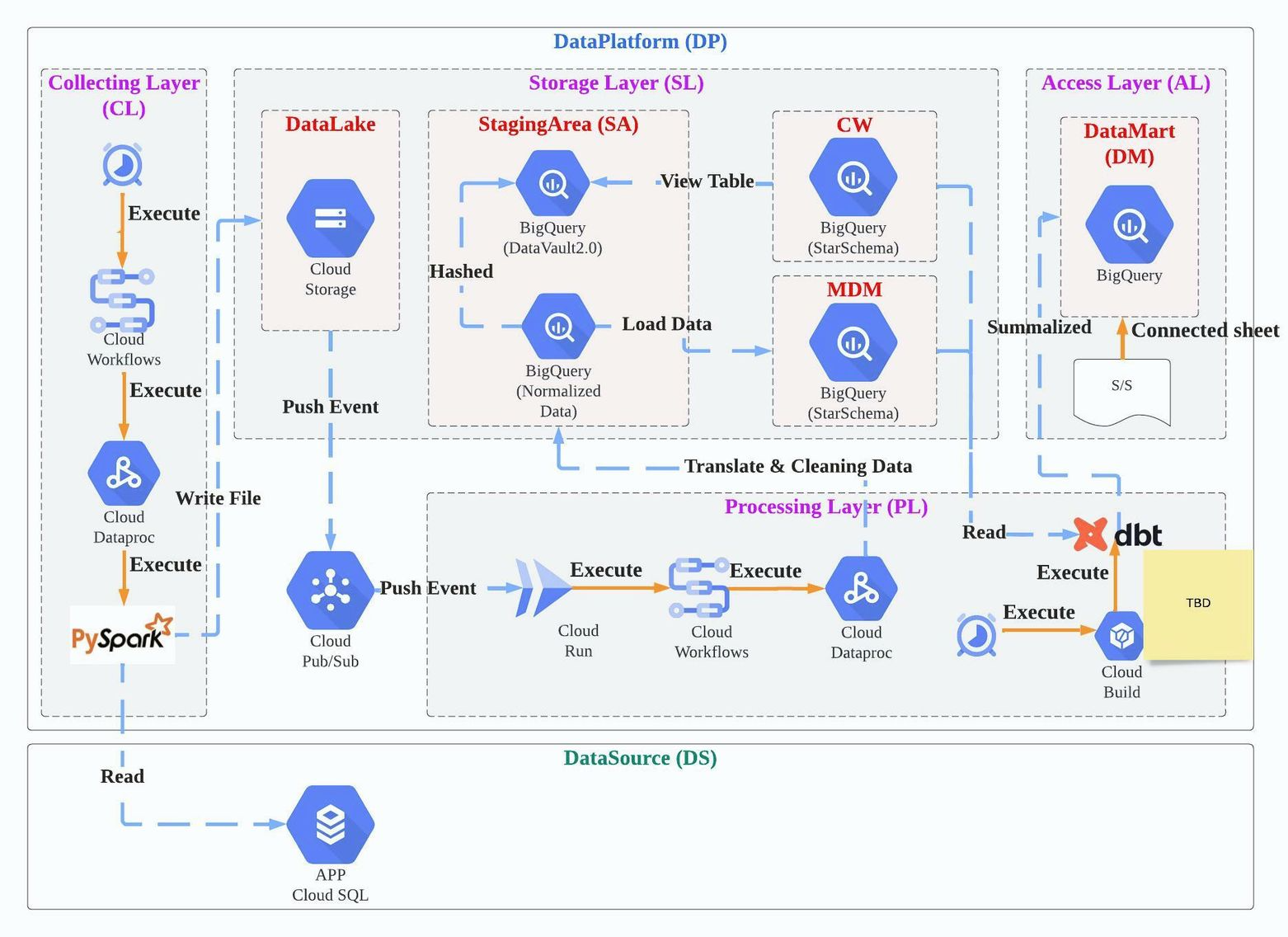
シンプルにした構成
構成を改善するために意識したことは後で必要なことは後で考えるということです。 私自身、課題を先回りして解決したい傾向があるのですが、これからのデータのユースケースの広がりを考えると考えるべきことが多すぎてキリがないと思い、目の前の課題を解決するためのユースケースの実現を優先するようにしました。
運用負荷を下げた構成としては以下の図にある形なのですが、大きな変更ポイントとしてはデータを BigQuery に入れ、それに対して dbt で ELT 処理をするようにしたことです。 以前の Spark を用いてデータを処理するメリットとして、1. 水平分散スケーリングしやすいこと、 2. プログラムでのデータの加工が行いやすいことがありました。 BigQuery 上でデータの加工を行う場合、(少なくとも現在の私達の規模では)スケーラビリティが懸念になることは有りません。 また、データの加工についても、殆どは SQL で対応すれば済むものが多く、それ以外はデータソース提供側と連携したり、前処理として加工することで対応が可能になるように調整しました。
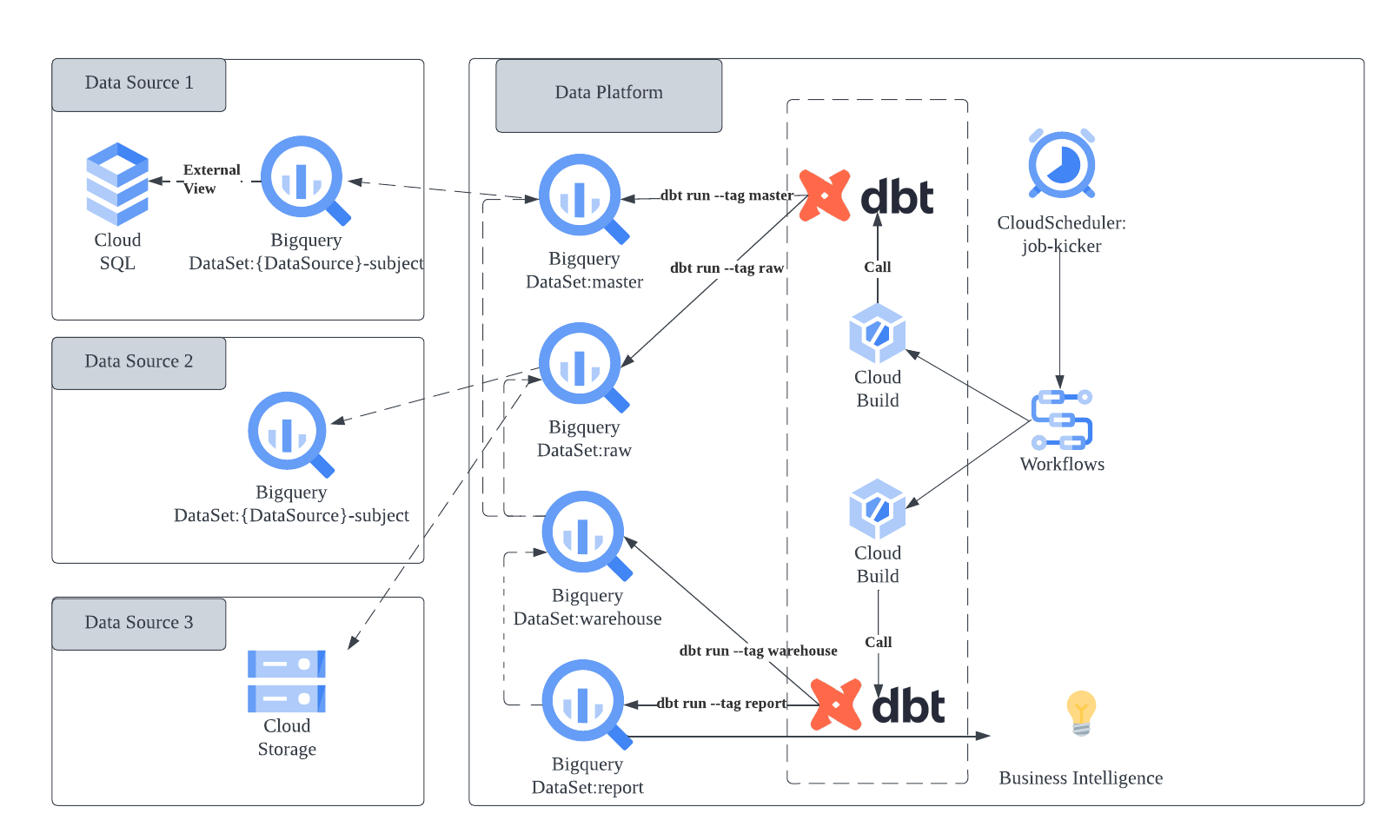
dbt は以前の記事でも少し触れましたが、データウェアハウスを作るために必要な機能が色々揃っています。 今後弊社でも知見が溜まってきたら色々と発信できたらと考えています。
おわりに
本記事ではデータプラットフォームチームの立ち上げの経緯、初期の取り組みに関して紹介しました。 1 人のメンバーで始まったこのチームも、マスタデータ管理のチームと統合され現在は 3 人の社員で構成されておりメンバーを更に募集中です。
これから立ち上げる複数の追加ユースケースの構築を控えており、各種データの可視化・処理の自動化が出来るようになったら ML などを用いての価格予測や時系列分析等にも着手したいと考えています。
一緒にデータ分析基盤を作りたいと思っていただけた方はもちろん、上のアーキテクチャをみて気になった方、 Cloud Composer などはなぜ使わなかったのかなど話してみたいといった方のカジュアル面談などもお待ちしています...!