Re:ゼロから学ぶ! 集約関数と Window 関数 (1/3) ~ 集約関数の概念編 ~
はじめに
こんにち WarCraft ! 株式会社 Belong で Project Manager をしている七色メガネです。
この記事では SQL における集約関数と Window 関数について。ゼロから学ぶことを目的に図解を交えながら種々の解説を行なっていきます。
全 3 回とちょっと長めの構成になってしまっていますが、よろしければお付き合いいだければと思います!
対象読者
- 集約関数と Window 関数の概念についてこれから学ぼうと考えている人
- 集約関数と Window 関数を知ってはいるけれども理解が朧な人
- 集約関数と Window 関数をいつも使っているけれども改めて学び直したい人
Agenda
この記事の範囲
- 集約の概念について
- グループから直接取得できる値について.1(標準 SQL)
- 集約関数について
- [応用] グループから直接取得できる値について.2(MySQL)
次回以降の範囲
Re:ゼロから学ぶ! 集約関数と Window 関数 (2/3) ~ Window 関数の概念編 ~
- Window 関数とは何か
- AVG() は集約関数か、Window 関数か?
- SQL と繰り返し
- フレームとは何か
- まとめ: 集約関数と Window 関数
Re:ゼロから学ぶ! 集約関数と Window 関数 (3/3) ~ 構文編 ~
- 構文解説: 集約関数
- 使用例解説: 集約関数
- 構文解説: Window 関数 ~ Window 句編 ~
- 使用例解説: Window 関数 ~ Window 句編 ~
- 構文解説: Window 関数 ~ フレーム 句編
- 使用例解説: Window 関数 ~ フレーム句編 ~
- まとめ
(1) 集約の概念について
早速ですがまずは、集約の概念について学んでいきましょう。
MySQL の公式ページでの現義をあたると、AVG() や MAX() などの集約関数処理についての説明ページは「Aggregate Function」と表記されています。
のでこれらの処理を呼ぶときは「集約関数」ないしは「集計関数」と言っていいですね。この記事では一貫して「集約関数」の方で読み替えていきます。
まずは「関数」の概念を横に置き、「集約」とは何なのかを理解しましょう。 集約とは何かを説明している MySQL の公式ページはなかったのでここは私なりの理解で失礼します。
「集約」とは、「ある特定の単位でデータをグループ化すること、ないしグループ化されたデータ自体」のことを指します。 そこに関数の意味を加えた「集約関数」とは、「ある特定の単位でグループ化されたデータに対して処理を行い 1 つの結果を返す関数」と言えます。
はて、ではここで急に出てきた「グループ」とはどんな概念なのでしょうか? それを理解するため、まずはグループ化されていないデータというものを考えてみましょう。
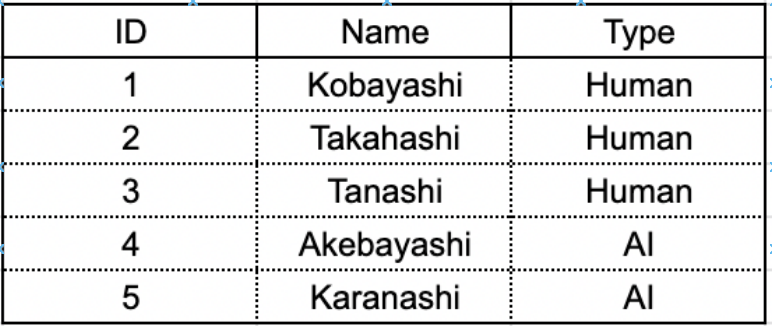
上記は ID, Name, Type という 3 属性で構成されたテーブル内データのイメージ画像です。テーブル名称は仮に sample としておきます。
ここにおける ID 1 から 5 までの 5 つのデータはそれぞれ独立した存在です。 例えば select * from sample でデータを取得したら、全ての ID がヒットし、5 件のデータが取得されますね。
しかしこれらのデータはそれぞれ独立しているものの、お互いが全く無関係というわけではありません。 Type 属性に注目すると、これらのデータは大別して Type: Human と Type: AI に分割することができることが伺えます。 この発想を実現するのが「グループ」の概念です。 上記発想を言語化すると、「Type という属性に注目して、共通の値を持つデータ同士をまとめ上げる」と言えます。図にすると下記のイメージです。
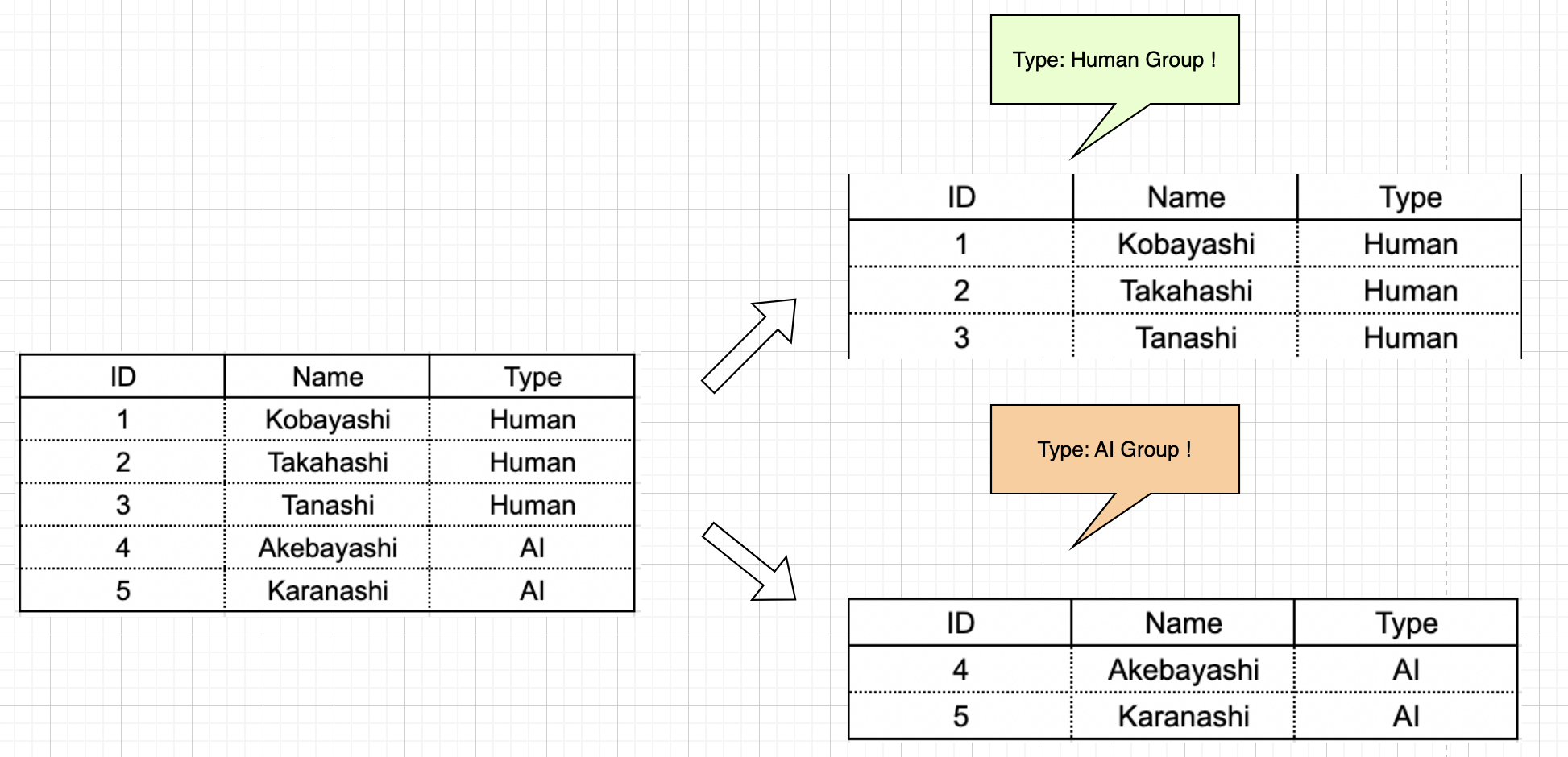
テーブルの中のデータを特定属性で分割した、と捉えてもいいかもしれませんね。 今回は Type が 2 つなのでグループも 2 つになっていますが、Type の種類が増えたら増えた分、グループも増えていきます。
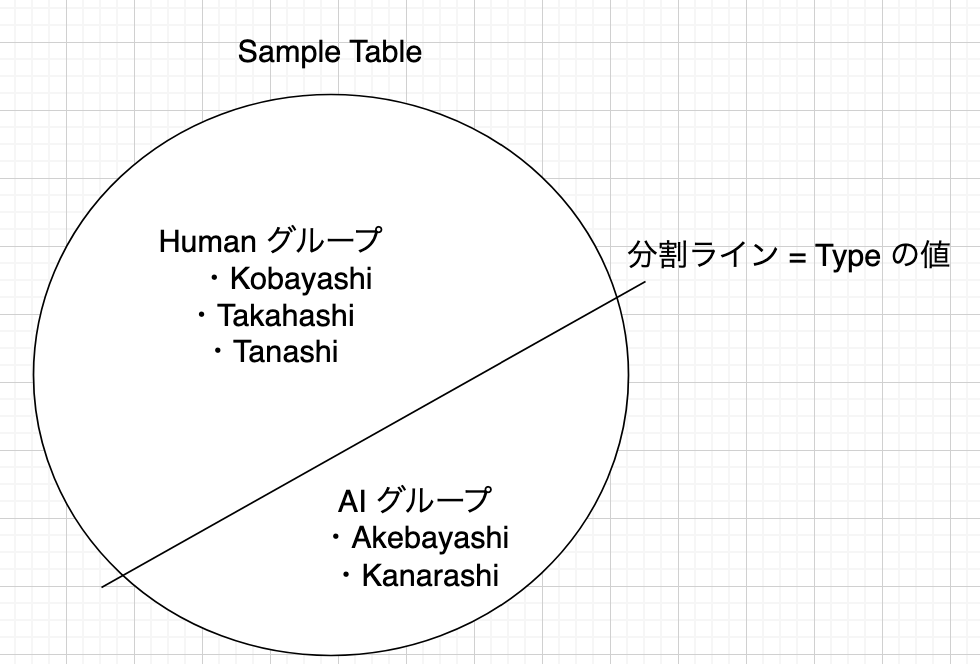
このようにデータ中の共通属性で以てまとめられたデータのことを、「グループ」と呼びます。 これを SQL で実現するための構文が、「Group By」です。上記画像と同じことを実現するのが、以下のクエリです。
select
...
from
sample
group by type
グループに関する基礎イメージはこれで完成です。 ただこの先に進む前に、もう少しグループに関するイメージを固めておきましょう。
先述の画像では、データをそのまま 2 つに分割していました。これをもう少し丁寧に表現すると、次のようになります。
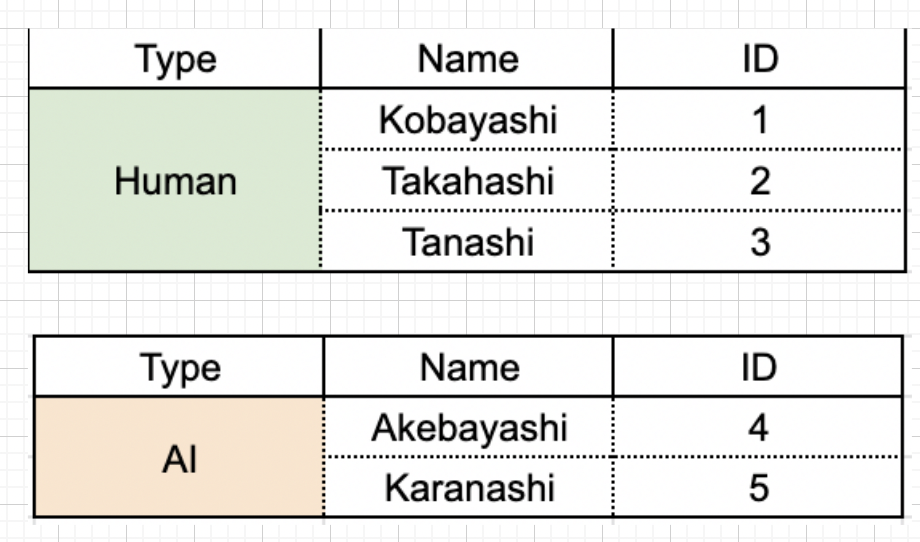
グループ化されたデータから、私たちはどんなデータを取得することができるのでしょうか。それを次の節で見ていきましょう。
(2) グループから直接取得できる値について.1(標準 SQL)
さて、ではこのグループからはどんな値を直接取得 (select) できるでしょうか? グループ化に用いた Type の値が取得できることは推測に難くないですが、他の値はどうでしょうか。
結論から述べると、標準 SQL ではグループ化に用いた値、つまり今回で言えば type 以外の値を直接取得することはできません。 これはなぜでしょうか?
データがグループ化されているということはいわば、個々のグループを 1 つの独立データレコードとして扱っているようなものです。 のでグループ化されたデータを参照する時には、 1 グループにつき 1 行の結果レコードが返ってこなければいけません。 グループ化されていない 1 つのデータレコードに対して 1 列を対象とした select を発行したとき、結果が 2 行も 3 行も返ってきたら困っちゃいますよね? グループ化されたデータは 1 行のデータレコードと同じような存在なので、同じことが言えるわけです。
分かりづらいところですのでもう少し言葉を重ねます。 グループ化されたデータとは、例えるならデータが雑多に入った箱にラベルを 1 つだけ貼っているようなものです。 1 つの箱に 1 つのラベルだけがあることは約束されているので、1 つの箱から結果を取り出そうとしたときに、ラベルそのものを参照することはできます。 しかし箱の中身に目を向けると、そこには無制約で雑多なデータが入っています。 ラベルではないこれら雑多なデータ値のどれかを参照しようとした瞬間、前述の「1 グループにつき 1 行の結果レコードが返ってこなければいけない」という制約に反することになるので、これはルール違反だ、ということになります。
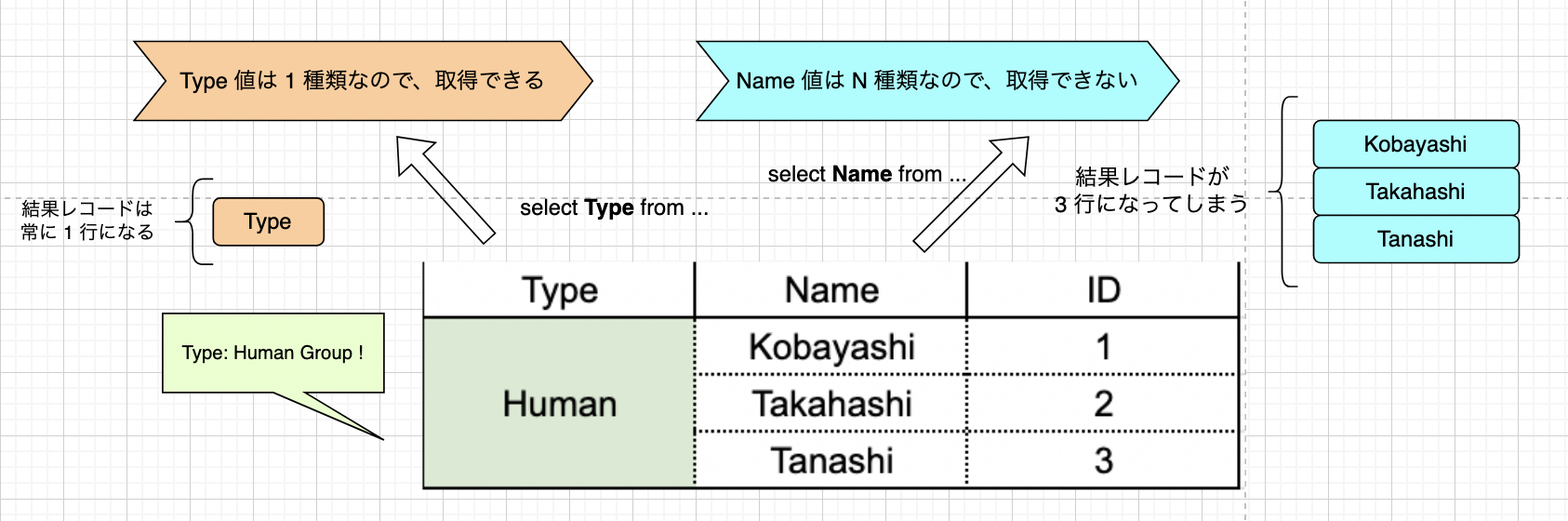
つまり繰り返しになりますが、グループ化されたデータから値を直接取得するときのルールとしては次のようなものがあると言えます。
- グループ化されたデータの値を直接参照 (Select) する時には、グループ化に用いた属性以外を直接選ぶことはできない。
ちなみに MySQL ではこの基本ルールを逸脱した用法があるのですが、それは応用編として後ほど別途解説します。
(3) 集約関数について
ここまでで以下のことがわかりました。
- グループの概念について
- グループ化されたデータから直接取得 (Select) するときのルールについて
1 つのグループ化されたデータから値を直接参照するときは、グループ化に用いた値以外を使用することはできないのでした。 なぜならばその他の値を直接参照してしまうと、結果レコードが N 行になってしまうためです。
では、値を「間接的に参照」して「結果レコードが 1 行になるように」取得できたとしたら、それは成立するでしょうか? 答えは「成立する」です。そしてそれこそが、「集約関数」と呼ばれるものです。
冒頭、集約関数の定義を以下のように整理していました。
- 「ある特定の単位でグループ化されたデータに対して処理を行い 1 つの結果を返す関数」
これを換言すると、「グループ内の N 個のデータに対して処理を行い、結果レコードを 1 行にして返す」ことに等しいと言えます。 このような性質を持つ関数を「集約関数」と呼びます。
集約関数には多くの関数が含まれています。グループ内のレコード数を数え上げる COUNT や、数値の平均を取得する AVG などです。 ここではグループ内のレコード数を数え上げる機能を持つ、 COUNT 処理を例にイメージを見てみましょう。
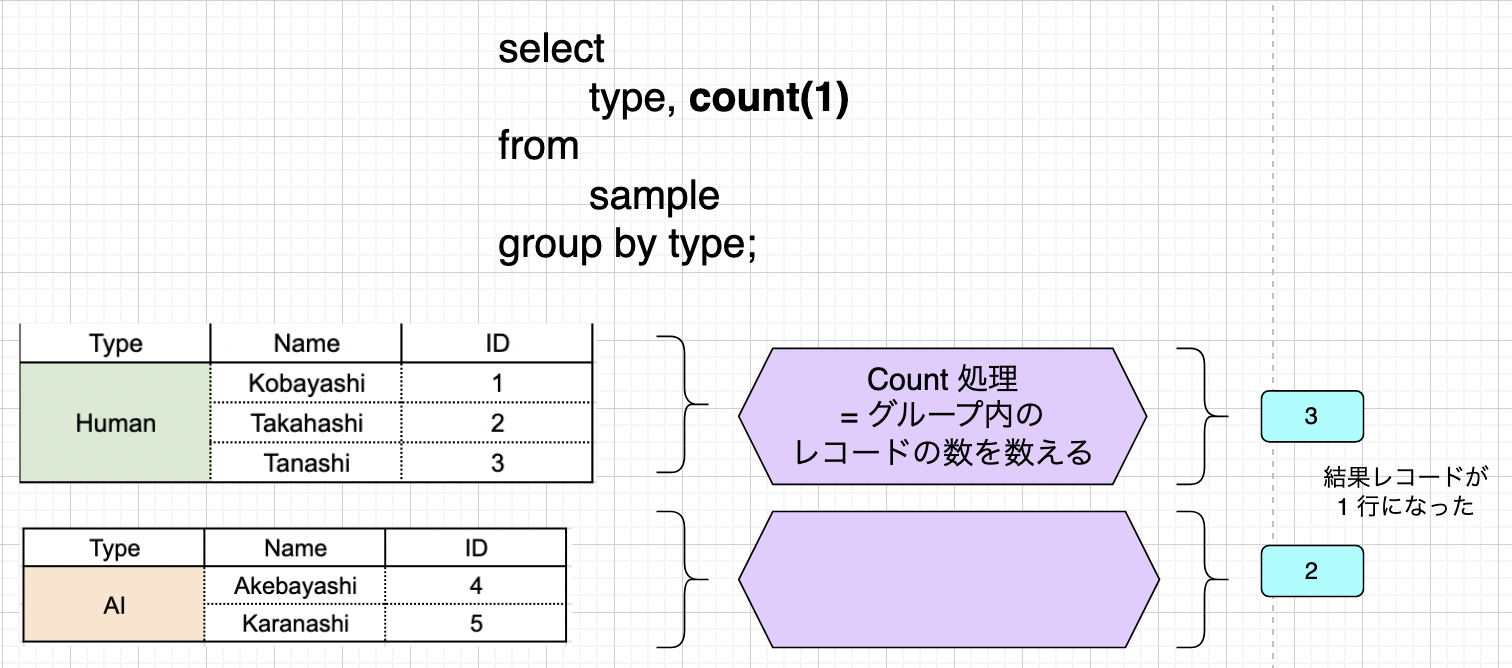
この処理では結果レコードが 1 つになることが約束されている Type に注目していません。「グループ内のレコード数」に着目しています。 この結果が 1 行に収まらないのであればルール違反となりグループに対する処理としては成立しませんが、「レコード数」が返るだけなので結果は 1 行となり、処理が成立します。
「結果レコードが 1 行になる」という性質は集約関数の中で常に共通です。 もう一つ、グループ内の指定された数値属性の平均値を求める AVG() 関数についても見てみましょう。ここでは Age 列をテーブルに追加しています。
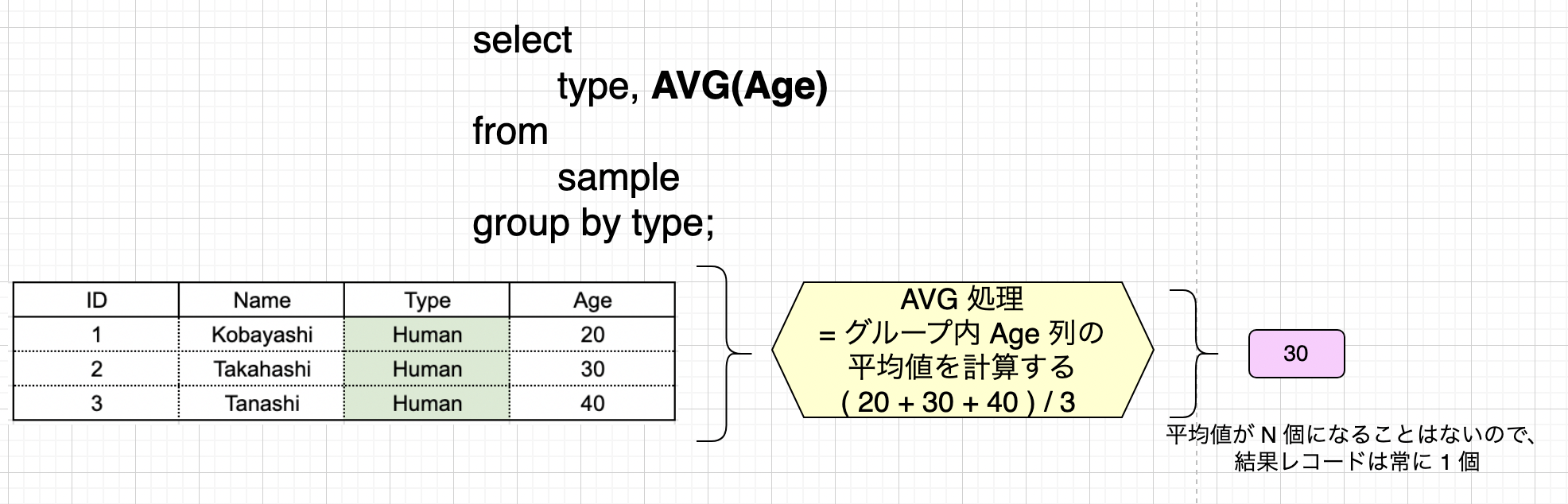
特定の観点 ( レコード数のカウント、平均値計算、など ) に立って各グループから 1 行の答えを導き出す、これが集約関数のイメージと言えます。
(4) [発展編] グループから直接取得できる値について.2(MySQL)
応用編です。初学者の方はここは読み飛ばしてもらって構いません。
第 2 章ではグループ化されたデータから値を直接参照するときの条件を以下のように規定しました。
「グループ化されたデータの値を直接参照する時には、グループ化に用いた属性以外を直接選ぶことはできない」
これは標準 SQL における基本ルールです。ただし MySQL の場合例外的にそのルールを逸脱することができます。
なぜ「グループ化に用いた属性以外を直接選ぶことはできない」かと言えば、「その他の値を直接参照してしまうと、結果レコードが N 行になってしまうためです。」ためでした。 では結果レコードが 1 つになることが約束されている場合はどうでしょうか。結論から言えば、MySQL であればこの場合はその値を直接参照することができます。
このルールは、「グループ化に用いた属性ではなくても、グループ内で値が 1 種類に集約されることが間違いなく約束される値であれば、直接参照を行なって良い」と言い換えられるでしょう。 これについてはまず DDL で見ていきましょう。
以下は今回の検証に用いる sample テーブルの定義です。
CREATE TABLE IF NOT EXISTS `sample` (
`id` BIGINT UNSIGNED NOT NULL,
`name` VARCHAR(10) NOT NULL,
`type` VARCHAR(10) NOT NULL,
`sex` VARCHAR(10) NOT NULL,
PRIMARY KEY(`id`),
index idx_type(`type`));
この中のデータ状況が次の通りだとします。
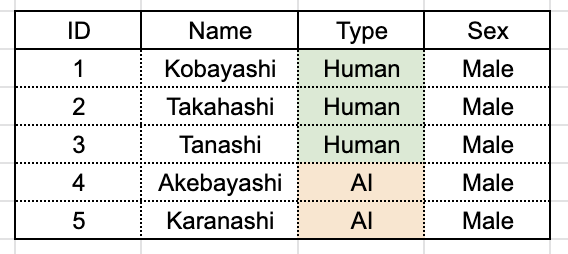
ここでまず成立するのは、グループ化に使用した属性を直接参照する方法です。これは説明不要ですね。
-- 成立1
select type
from sample
group by type;
逆に成立しないのは、グループ化に使用していない属性を直接参照することです。 これも上の方でサンプルを挙げているので繰り返しませんが、name 列について結果レコードが 3 件返ってくることになってしまうのが失敗の原因です。
-- 不成立1
select
type,
name -- 各グループにおいて値が一意にならない
from sample
group by type;
では、「結果的にグループ内での値が一意」の列を直接参照するのはどうでしょうか? 今回のサンプルデータでは、Sex の値が全て等しくなっています。従って、「1 グループにつき 1 行の結果レコードが返ってくる」という条件が結果的に満たされています。 結論を述べると、これもまたエラーになります。
-- 不成立2
select
type,
sex -- 各グループにおいて結果的に値は一意になるが、その一意性が保証されていない。
from sample group by type;
現時点でユニークであっても、次にデータが挿入されたらどうなるか分かりませんからね。 つまり「結果的に値がユニークになる」程度の整合性ではグループの縛りからは逃れられないと言うことです。 ではどうしたらこのルールから外れることができるのでしょうか。
答えは、「グループ化に使用した属性によって一意に値が定まることが決定されている値であれば、グループ中であっても直接参照できる」です。分かりづらいですね。 この性質には名前があります。「関数従属性」です。この定義は
「関係(リレーション)の中で、X の値が決まると Y の値が決まること」
です。 つまり今回の場合で言えば、グループ化に使用された type の値によって一意に決まる値があれば、それはグループに対しても直接参照できる値となるわけです。
そのような条件を満たす値を持つテーブルを追加してみましょう。
CREATE TABLE IF NOT EXISTS `type_description` (
`type` VARCHAR(10) NOT NULL,
`description` VARCHAR(255) NOT NULL,
PRIMARY KEY (`type`),
CONSTRAINT `fk_sample`
FOREIGN KEY (`type`)
REFERENCES `sample` (`type`)
ON DELETE NO ACTION
ON UPDATE NO ACTION);
これは先程の sample テーブルにあった type の description を保存することを意図したテーブルです。 このテーブルでは type 値が PK になっています。PK であるということは、このテーブルの中の type 値はユニークであるということです。 また sample テーブルの type 値に対して外部キーを貼っています。
これらのことをつなぎ合わせると、「sample.type を参照するとき、その type に紐づけることのできる type_description のデータはユニークである」と分かります。
ここには次のようにデータを格納しておきます。

繰り返しですが、新しいテーブル type_description 内の type 値は PK であるので一意であり、またこの値は sample テーブルの type に外部参照を貼って居ます。 つまり sample テーブルの type は 1 つ (あるいは 0 個の) の description を持つことが論理的に保証されます。 この状態で以下のクエリを実行してみましょう。td.description はグループ化に使用された値ではありませんが、直接参照することに成功します。
-- 成立2
select
s.type,
td.description -- グループ化に使った列ではないが、結果が 1 つになることが保証されているので参照できる。
from sample s
inner join type_description td on s.type = td.type
group by s.type;
ということで、MySQL では Group By で指定していない列であっても、特定状況下では Select できるぞという解説でした。 とはいえ、「できる」ことと「分かりやすい」ことは同義ではないので、不必要に多用するのは避けたいですね。
終わりに
今回はグループと、集約関数の概念について説明を行いました。
次回記事では Window 関数の概念を理解し、そしてそこから構文の解説に入っていきたいと思います。そちらも是非ご覧ください。
また弊社 Belong では一緒にサービスを育てる仲間を募集しています。 もし弊社に興味を持っていただけたら エンジニアリングチーム紹介ページ をご覧いただけたら幸いです。
ここまで読んでいただきありがとうございました!
今回はここまで。サヨウナラ!