Re:ゼロから学ぶ! 集約関数と Window 関数 (2/3) ~ Window 関数の概念編 ~
はじめに
こんにち Witcher ! 株式会社 Belong で Project Manager をしている七色メガネです。
ここでは集約関数と Window 関数について図解を交えてゼロから学ぶことを目的に、種々の解説を行なっていきます。
この記事は前回記事からの続きとなりますので、よければそちらもご覧ください。
https://belonginc.dev/members/nanairomegane/posts/aggregate-and-window1
対象読者
- 集約関数と Window 関数の概念についてこれから学ぼうと考えている人
- 集約関数と Window 関数を知ってはいるけれども理解が朧な人
- 集約関数と Window 関数をいつも使っているけれども改めて学び直したい人
Agenda
今回記事の範囲
- Window 関数とは何か
- AVG() は集約関数か、Window 関数か?
- SQL と繰り返し
- フレームとは何か
- まとめ: 集約関数と Window 関数
前回記事の範囲
Re:ゼロから学ぶ! 集約関数と Window 関数 (1/3) ~ 集約関数の概念編 ~
- 集約の概念について
- グループから直接取得できる値について.1(標準 SQL)
- 集約関数について
- [応用] グループから直接取得できる値について.2(MySQL)
次回記事の範囲
Re:ゼロから学ぶ! 集約関数と Window 関数 (3/3) ~ 構文編 ~
- 構文解説: 集約関数
- 使用例解説: 集約関数
- 構文解説: Window 関数 ~ Window 句編 ~
- 使用例解説: Window 関数 ~ Window 句編 ~
- 構文解説: Window 関数 ~ フレーム句編 ~
- 使用例解説: Window 関数 ~ フレーム句編 ~
- まとめ
(5) Window 関数とは何か
さて前回の記事で、グループの概念と集約関数の処理イメージについて学びました。ここからはいよいよ Window 関数について理解していきましょう。
MySQL では 8.0 からこの機能が解放されたことなどからわかるように、集約関数に比べると比較的新しめの技術になります。
Window 関数は集約関数と非常に近い概念であり、兄弟のような存在と言えます。のでまずは、集約関数の性質をおさらいしておきましょう。
前回の記事では、集約関数を
- 「ある特定の単位でグループ化されたデータに対して処理を行う関数」であり、
- 「1 グループにつき 1 つの結果レコードを返却する」機能を持った関数である
というふうに解説しました。
対して Window 関数はどうかというと、
- 「ある特定の単位でグループ化されたデータに対して処理を行う関数」であり、
- 「1 行につき 1 行の結果レコードを返却する」機能を持った関数である
- また、「グループ内データに対して任意の単位で処理を行うことができる」機能を持った関数である。
と言うものです。1 つ目は完全に同じですね。後者は違いますが、似ているところが多いように見えます。
ではこちらもイメージで見ていきましょう。
今回は、前回グループの概念を説明したときのデータ構造に Age と言う列を追加しています。 テーブル内データのイメージは次の通りです。
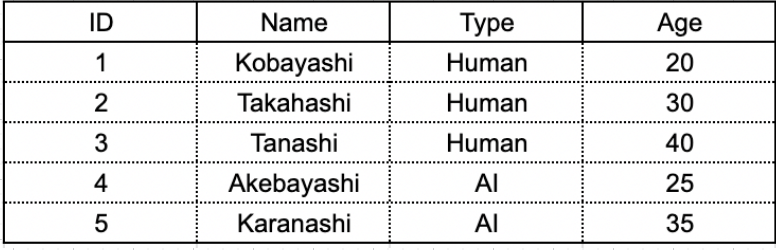
前述の通り、集約関数でも Window 関数であって、グループに対して処理するという点は同じなのでした。
ので、まずは先ほど同じように Type 属性でグループ化してみましょう。
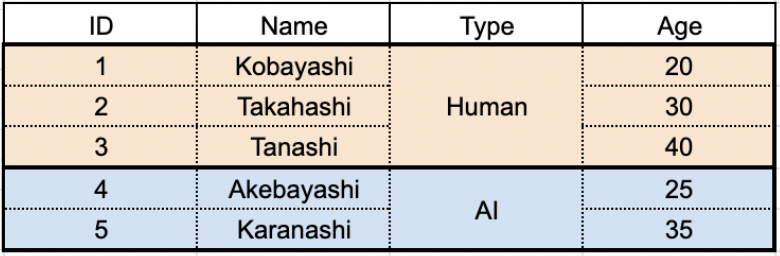
今回は集約関数の時にも使用した AVG() 関数を用いて話を進めます。グループの Age 列に対して、平均値を求めます。 ここでは Human グループにのみ注目してみます。
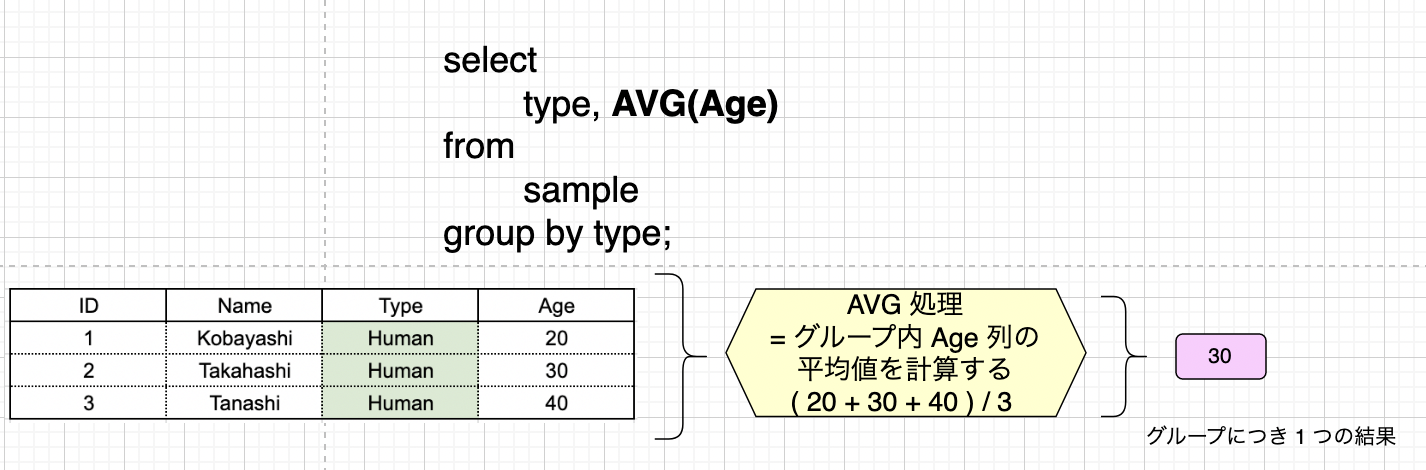
AVG() 処理の結果、Human グループにおける Age の平均値が 30 であることが分かりました。
さていきなりですが、ここで核心に入ります。 このまま 1 グループに対する 1 つの結果として返すのが集約関数、この結果を各行に付与して全ての行を返却するのが Window 関数、です。 先にイメージを確認しましょう。
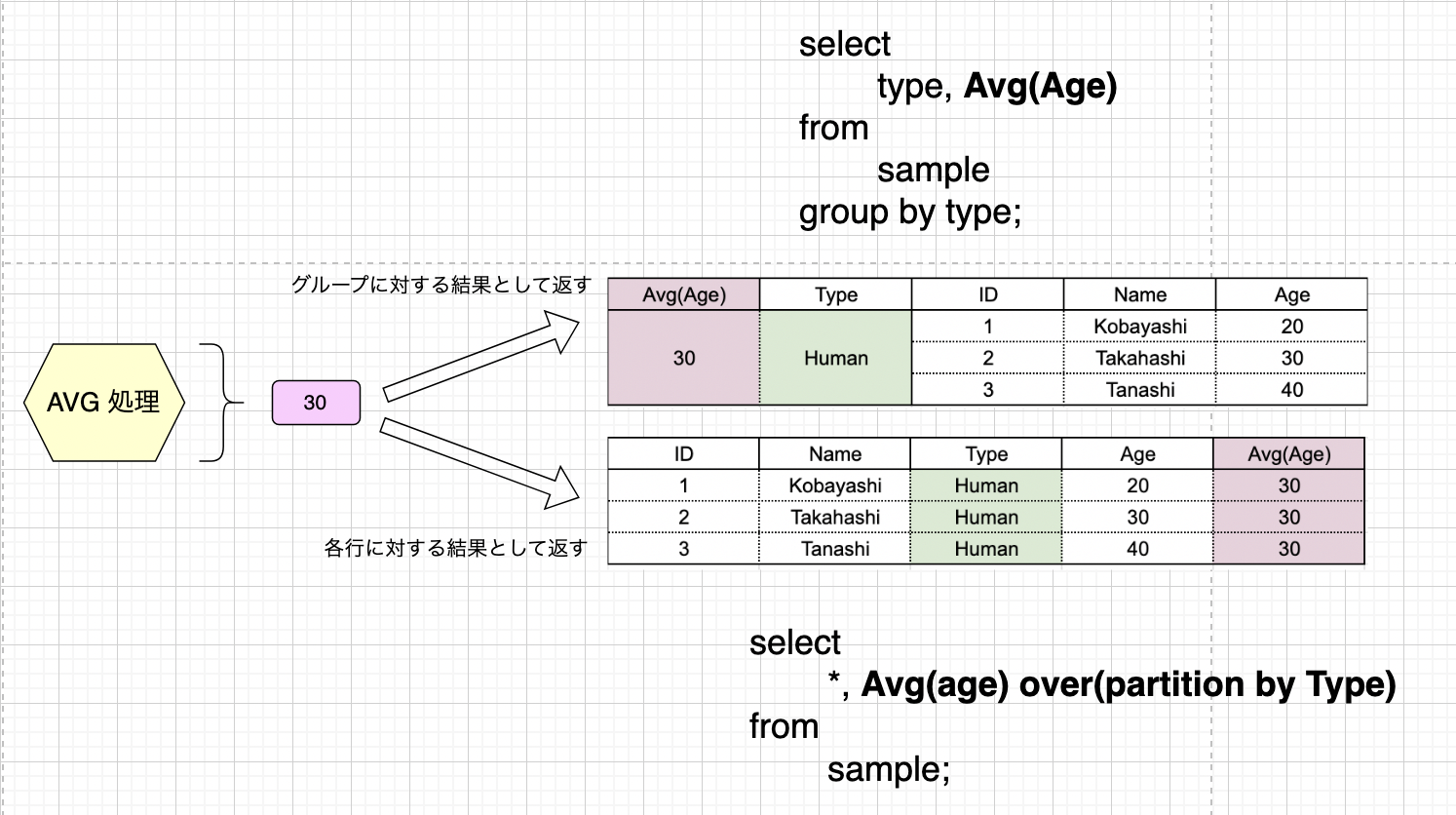
前述していた集約関数と Window 関数の違いをもう一度引きます。
- 「1 グループにつき 1 つの結果レコードを返却する」機能を持った関数 → 集約関数
- 「1 行につき 1 行の結果レコードを返却する」機能を持った関数 → Window 関数
集約関数ではグループに対して処理した結果をグループに対して返却していたので、整合性が崩れないように「1 グループに対する結果レコードは 1 つまで」という風に制約していました。 対して Window 関数では、グループの概念は計算の途中で使うだけであり、最終的に返却する結果はグループに対するものではありません。従って整合性を気にする必要がなく、「1 行につき 1 行の結果レコードを返却する」ということになります。 集約関数によって処理された結果を各行に改めて振り分けている、ような動きだとも言えますね。
結果に少し違いこそあるものの、「ある特定の単位でグループ化されたデータに対して処理を行う」という点においては、集約関数も Window 関数も違いがないということを理解いただけたでしょうか? この 2 つは全く異なる概念ではなく、かなり近似した概念であるということがわかりますね。
(6) AVG() は集約関数か? Window 関数か?
さて、次の解説に入る前にちょっと疑問を解消しておきましょう。 それは AVG() 関数は集約関数なのか、それとも Window 関数なのか、という点です。
この関数は前述の解説にあった通り、集約関数としても Window 関数としても使われていました。この 2 つの用途における AVG() は全く異なる関数なのでしょうか、それとも同一の関数なのでしょうか?
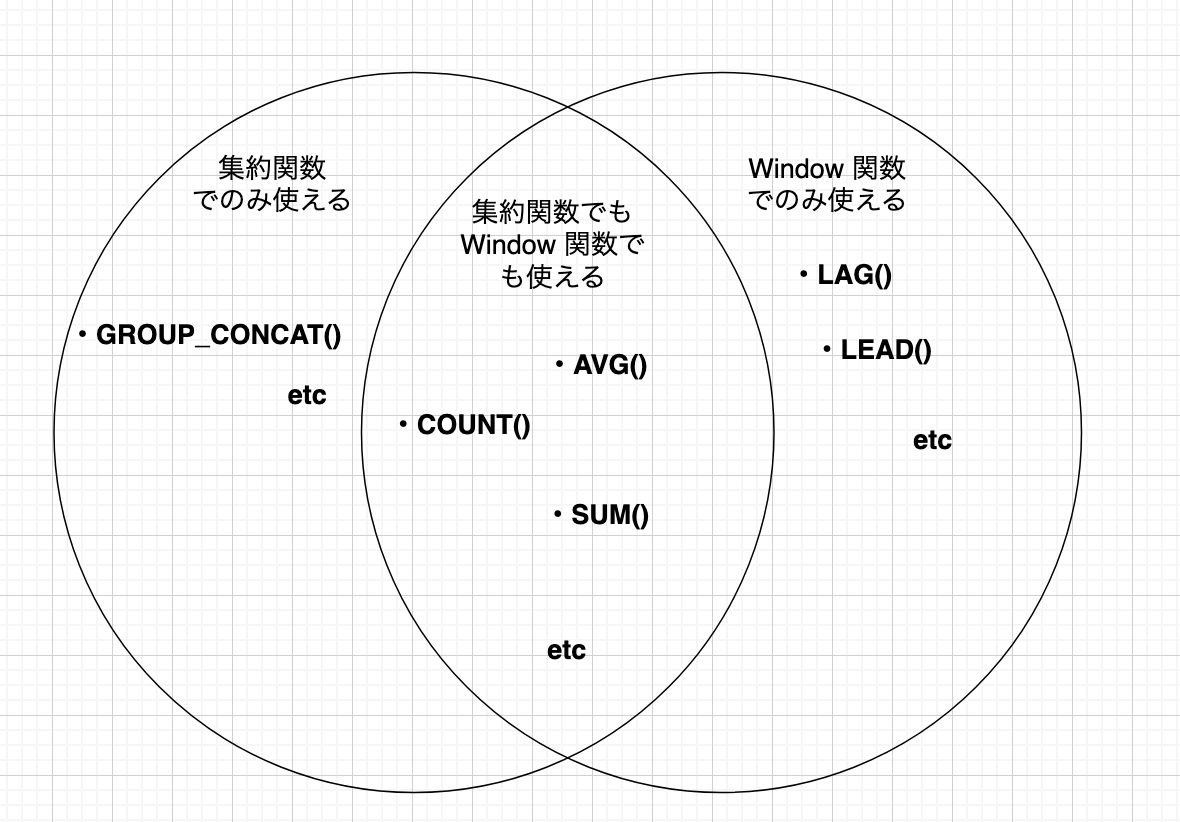
結論としては、同一の関数です。 これは、AVG() が集約関数、Window 関数のいずれにも使用できる関数であるためです。
AVG() だけではなく、基本的にほとんどの集約関数は Window 関数として使用することができます。
ただし、一部は集約関数としてのみ、あるいは Window 関数としてしか使用できない関数も存在するので注意してください。
(7) SQL と繰り返し
結果レコードをグループに対して 1 つだけ返すか、それとも各行に対して 1 つずつ返すか。それが集約関数と Window 関数におけるグループに対する向き合い方の大きな違いでした。 さて次は、Window 関数特有であるフレームの概念について理解していきましょう。 Window 関数特有のこの機能について、以下のように説明して居ました。
また、「グループ内データに対して任意の単位で処理を行うことができる」機能を持った関数である。
ここで核心に入る前に、ちょっと寄り道しましょう。繰り返し処理についてのお話です。
プログラミング言語には色々な種類と書き方がありますが、どの言語にも共通して存在していて、かつプログラミングの本質である機能は何かと言うと、「条件分岐」と「繰り返し」だと私は考えています。
では SQL はどうでしょう。SQL はプログラミング言語ではないですが、「条件分岐」と「繰り返し」は出来るんでしょうか?
条件分岐については、標準の構文として CASE がありますね。値が A の時には X を、そうではなければ Y を出力する、みたいなことを制御できる構文です。 ( 厳密に言えば条件分岐としてはちょっと機能不足ですが )
では繰り返しはどうでしょう? 類似機能はあるのでしょうか?
一応 MySQL ではストアドプロシージャを使うことができます。これは複雑な条件分岐やループ処理を行いながら SQL を使用することができる機能であり、プログラムにおけるそれと極めて近似です。 とはいえストアドプロシージャはコンパイルが必要であったりサーバー側に保存する必要があったりと、単体の SQL の実行容易性に比べるとどうしても腰が重い印象があります。また構文もやや複雑です。
例として、「月別の売上データ群を使用して、各月の売上額と当月までの売上合計額を算出する」と言う例をプログラムとストアドプロシージャで考えてみましょう。
プログラム側は Go を使用して考えてみます。コード書くのはあまり得意ではないので質についてはご容赦。
package main
import "fmt"
type rawSalesData struct {
month string
sales int
}
type salesDataResult struct {
month string
sales int
salesSum int
}
func main() {
var results []salesDataResult
rawData := []rawSalesData{
{"1月", 10000},
{"2月", 15000},
{"3月", 16000},
{"4月", 20000},
{"5月", 18000},
{"6月", 10000},
}
sum := 0
for _, v := range rawData {
sum += v.sales
results = append(results, salesDataResult{v.month, v.sales, sum})
}
fmt.Println(results)
}
[{1月 10000 10000} {2月 15000 25000} {3月 16000 41000} {4月 20000 61000} {5月 18000 79000} {6月 10000 89000}]
データに対して for で繰り返し処理を行い、隣接データとの計算を行なって結果を吐いていますね。
ではストアドプロシージャではどうでしょうか。
以下のようにあらかじめテーブルとデータを用意しておきます。
CREATE TABLE IF NOT EXISTS `monthly_sales` (
`month` varchar(10) NOT NULL,
`sales` decimal NOT NULL,
PRIMARY KEY(`month`)
);
CREATE TABLE IF NOT EXISTS `monthly_sales_result` (
`month` varchar(10) NOT NULL,
`sales` decimal NOT NULL,
`sales_sum` decimal NOT NULL,
PRIMARY KEY(`month`)
);
insert into monthly_sales values
("1月", 10000),
("2月", 15000),
("3月", 16000),
("4月", 20000),
("5月", 18000),
("6月", 10000);
ここからプロシージャです。
CREATE PROCEDURE sample1()
BEGIN
declare month varchar(10);
declare sales decimal;
declare sales_sum decimal;
declare raw_data cursor for select * from monthly_sales;
set @idx = 0;
set sales_sum = 0;
select count(1) into @count from monthly_sales;
open raw_data;
while @count > @idx do
fetch from raw_data into month, sales;
set sales_sum = sales + sales_sum;
set @idx = @idx + 1;
insert into monthly_sales_result values (month, sales, sales_sum);
end while;
close raw_data;
select * from monthly_sales_result;
END
'1月','10000','10000'
'2月','15000','25000'
'3月','16000','41000'
'4月','20000','61000'
'5月','18000','79000'
'6月','10000','89000'
どちらの場合でもデータを取得して for ループを回すことで隣接比較を実現しています。 処理自体は複雑ではないものの、簡単なことを実現するためにそこそこの紙幅をとってしまっています。
プログラム側はもっとうまくやる方法はきっとあるのでしょうが、ここで問題にしたいのは SQL の側です。 こんな単に for を回すだけの処理、SQL クエリ単体ではできないのでしょうか?
結論は、「できる」です。上記プロシージャと同等の働きをするのが以下のクエリです。
select
month,
sales,
sum(sales) over(order by month rows unbounded preceding)
from monthly_sales;
'1月','10000','10000'
'2月','15000','25000'
'3月','16000','41000'
'4月','20000','61000'
'5月','18000','79000'
'6月','10000','89000'
ストアドプロシージャと比べたら、明らかに簡潔ですね。
ここで使用している機能こそが Window 関数のフレームであり、そして今まではストアドプロシージャを使わなければ実現できなかった繰り返し処理を実現する機能なのです。
このフレーム機能について、次章で詳しくみていきましょう。
(8) フレームとは何か
最初に説明した例では、集約関数と Window 関数の違いとして「グループに対して処理を行い、その結果をグループに対して返却するか、各行に返却するか」と言う点を挙げていました。 ともに「グループに対して処理を行う」と言う点で共通しています。これはつまり、グループ全体に対して AVG() や SUM() の処理を行う機能が同一であると言うことを意味しています。
Window 関数におけるフレームの概念は集約関数のそれとは違います。これは、「グループの中のデータに対して指定した範囲について処理を行う」と言う特性を持っています。図でみていきましょう。
まずはテーブルの中身について確認していきます。これは先程の例と同じです。今回は全てのデータが 1 グループを形成していると考えます。
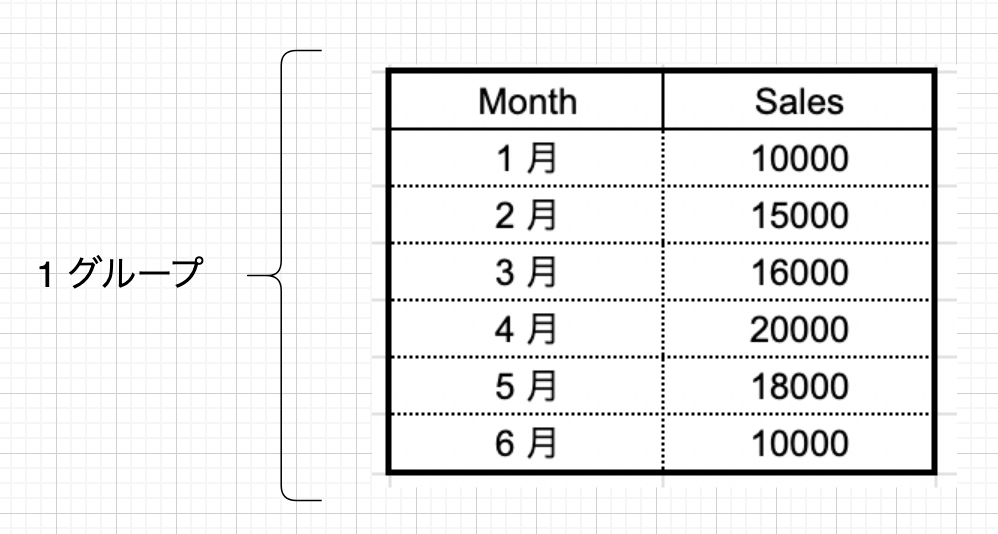
フレームとは、「グループの中での任意の処理単位」のことを指します。グループ内のサブセットとも言えます。
集約関数は「グループ全体に対して処理を行う」ものでしたが、このフレーム処理ではグループ全体ではなく「グループ内の任意の処理単位に対して処理を行う」ことができます。
ここでいう「グループ内の任意の処理単位」とは、例えば先程の例で見た「最初から現在行まで」などのことです。

各レコードにフォーカス当たるたびに新たなフレームを作成し、そのフレーム内で集計処理を行なっているイメージです。For とほぼ等価の処理だと思って良いと考えています。
このフレームはかなり自由に設計することができます。次の記事でも紹介しますが、先にイメージ画像だけ貼っておきます。
次の 2 つはそれぞれ、「現在行と次の行を対象とするフレーム」「現在行を含めた前後 1 行ずつを対象とするフレーム」です。


ということでフレームを使用すると、グループ全体に対する集計ではなくグループ内でさらに自由度の高い処理を行うことができるというわけでした。 うまく使いこなせれば、ストアドプロシージャやプログラムを利用するまでもなく、繰り返し計算など自由度の高い処理を SQL だけで実装できちゃいますね。
(9) まとめ: 集約関数と Window 関数の違い
さて最後に、ここまでに学んだ集約関数と Window 関数の違いをまとめましょう。
まず両者に共通しているのは、ともに「データをグループという単位にして処理を行う」という点でした。
そして集約関数は処理の結果を単一の行として返却し、Window 関数は複数の行として返却することができるのでした。
さらに Window 関数の場合は、グループ全体に対して処理を行うこともできるし、或いはグループの中に更にフレームという概念を持ち込むことでより柔軟な処理を行うこともできるのでした。
関数の棲み分けも加えて図にするとこんな感じでしょうか。

知識なんて使わなければ身にはつきませんが、それでも何もわからずに使ってみるのとイメージを持って使ってみるのとでは天地の差が生まれると思っています。
ぜひ 2 つの機能の違いのイメージを理解して、普段の業務や趣味で使ってみてください。
終わりに
今回は Window 関数の概念について説明を行いました。 もう概念について学ぶことはないので、次回記事でそれぞれの関数についての構文を学び、集約関数と Window 関数に関するお勉強は卒業としましょう。
今回も長文にお付き合いいただきましてありがとうございました。
弊社 Belong では一緒にサービスを育てる仲間を募集しています。
もし弊社に興味を持っていただけたら エンジニアリングチーム紹介ページ をご覧いただけたら幸いです。
それではまた次回 ! サヨウナラ !