Re:ゼロから学ぶ! 集約関数と Window 関数 (3/3) ~ 構文編 ~
はじめに
こんにち Wizardry ! 株式会社 Belong で Project Manager をしている七色メガネです。
ここでは集約関数と Window 関数について図解を交えてゼロから学ぶことを目的に、種々の解説を行なっていきます。
この記事は前回記事からの続きとなりますので、よければそちらもご覧ください。
対象読者
- 集約関数と Window 関数の概念についてこれから学ぼうと考えている人
- 集約関数と Window 関数を知ってはいるけれども理解が朧な人
- 集約関数と Window 関数をいつも使っているけれども改めて学び直したい人
Agenda
今回記事の範囲
- 構文解説: 集約関数
- 使用例解説: 集約関数
- 構文解説: Window 関数 ~ Window 句編 ~
- 使用例解説: Window 関数 ~ Window 句編 ~
- 構文解説: Window 関数 ~ フレーム句編 ~
- 使用例解説: Window 関数 ~ フレーム句編 ~
- まとめ
前回まで記事の範囲
Re:ゼロから学ぶ! 集約関数と Window 関数 (1/3) ~ 集約関数の概念編 ~
- 集約の概念について
- グループから直接取得できる値について.1(標準 SQL)
- 集約関数について
- [応用] グループから直接取得できる値について.2(MySQL)
Re:ゼロから学ぶ! 集約関数と Window 関数 (2/3) ~ Window 関数の概念編 ~
- Window 関数とは何か
- AVG() は集約関数か、Window 関数か?
- SQL と繰り返し
- フレームとは何か
- まとめ: 集約関数と Window 関数
(10) 構文解説: 集約関数
さてさて、ここまでの記事で集約関数と Window 関数の概念について学んできました。うろ覚えな方は前回までの記事を確認いただければと思います。
ここからはガリガリと、構文について学んでいきましょう。まずは集約関数からです。
一旦ここでは、集約関数使用時の基本構文を一通り押さえます。
集約関数が成立するための最低条件はズバリ、集約関数が存在することです。当たり前ですね。
当たり前ではありますが、グループに関する条件の存在は最低条件ではない というのは押さえておきましょう。つまり以下の構文説明の中で、集約関数処理が成立するために本当に必須なのは ④ だけです。
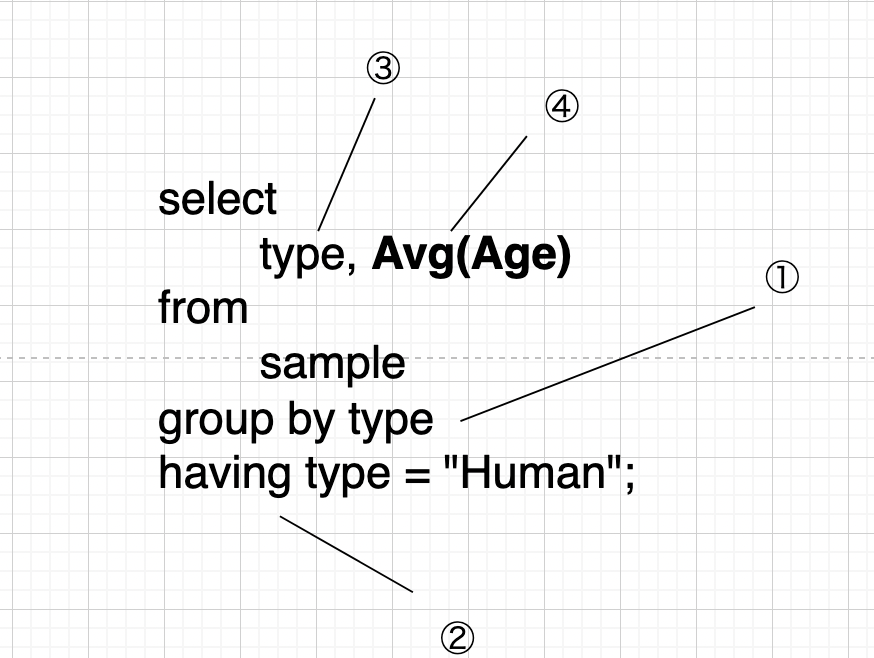
- 構文詳細は公式説明も参照してください。
① Group By 句
指定した列属性でグループ化を行います。複数列が指定された場合、その組み合わせでグループ化を行います。
② Having 句
グループ化されたデータに対して絞り込み条件を適用します。 絞り込みに使用できるのは基本的に Group By 句で指定した属性か、集約関数の結果列です。 Where よりも後に実行されます。
③ 通常の Select 部
通常の Select です。 グループが行われているときに集約関数以外で Select できるのは、基本的にグループ化に使用された列のみです。
④ 集約関数
指定されたグループに対して集約処理を行います。Group By 句が指定されていない状態で集約関数が用いられた場合、テーブル全体を 1 つのグループとみなします。
(11) 使用例解説: 集約関数
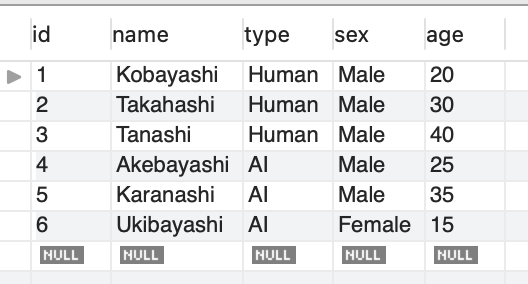
知識の定着がてら、いくつか集約関数の使い方をイメージとともに見てみましょう。 テストデータは以下を使用します。
CREATE TABLE IF NOT EXISTS `sample` (
`id` BIGINT UNSIGNED NOT NULL,
`name` VARCHAR(10) NOT NULL,
`type` VARCHAR(10) NOT NULL,
`sex` VARCHAR(10) NOT NULL,
`age` int NOT NULL,
PRIMARY KEY(`id`),
index idx_type(`type`));
insert into sample values
(1,"Kobayashi", "Human", "Male", 20),
(2,"Takahashi", "Human", "Male", 30),
(3,"Tanashi", "Human", "Male", 40),
(4,"Akebayashi", "AI", "Male", 25),
(5,"Karanashi", "AI", "Male", 35),
(6,"Ukibayashi", "AI", "Female", 15)
;
(a) 条件を満たすグループに対してのみ集約処理を行う ( Group By + Having )
構文説明で使用した例ですね。グループ化を行った後に、Having 句でグループの選別をしています。
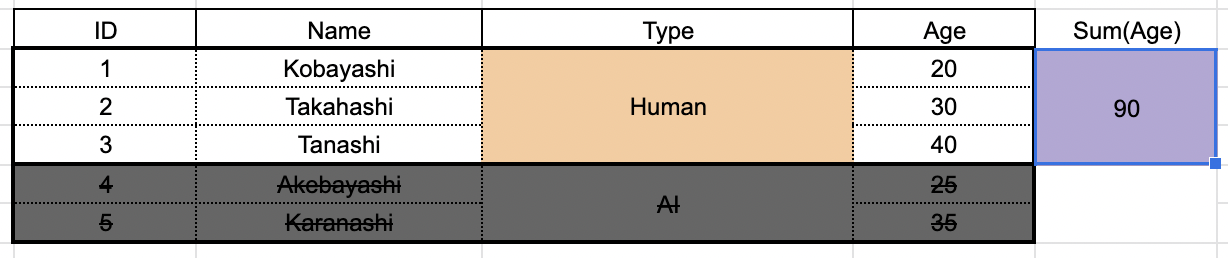
select type, sum(age)
from sample
group by type
having type = "Human";
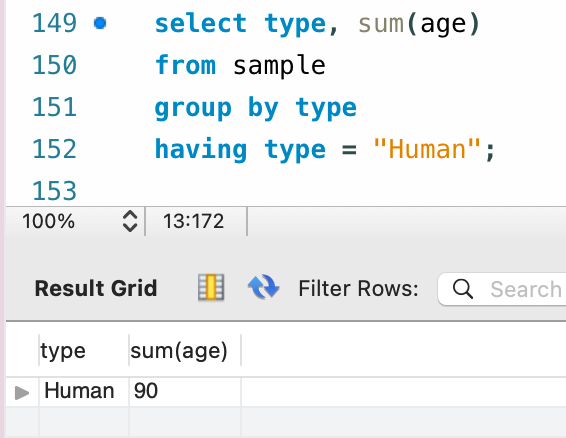
イメージとしては次の感じです。
まず通常通りのグループ化が行われ、
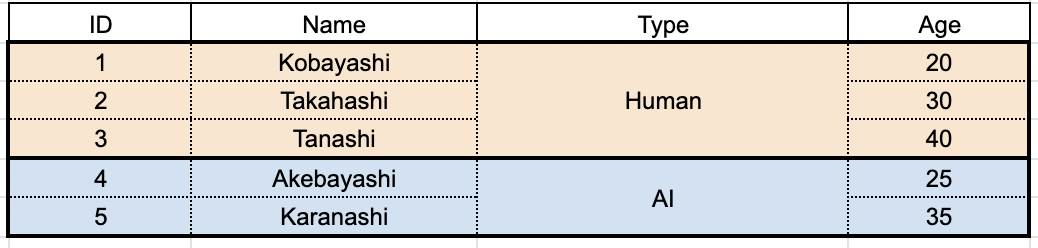
集約処理が行われる前に、グループの選別が行われます。今回は type = "Human" で絞り込みがかかっているの、type = "AI" グループが切り捨てられますね。
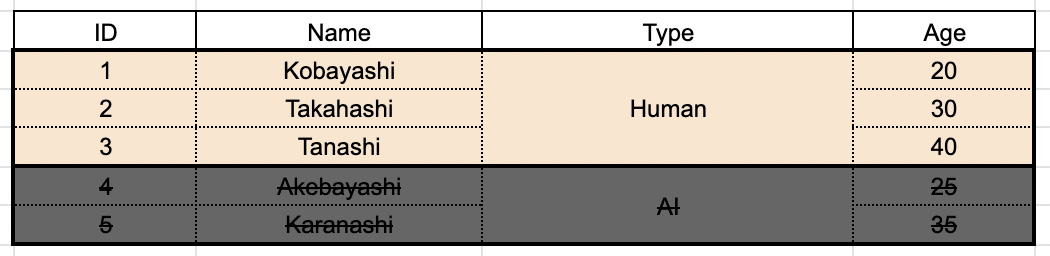
そして選別を生き残った type = "Human" グループに対して、集約処理が行われます。
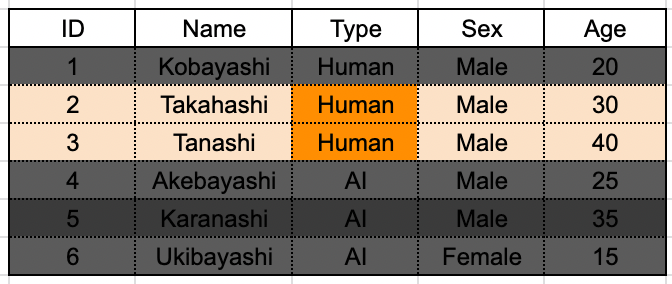
(b) 条件を満たすレコードをグループ化し、その中で条件を満たすグループに対してのみ集約処理を行う ( Group By + Having + Where )
Having と Where を併用した場合、先に処理が実行されるのは Where です。
select type, sum(age)
from sample
where age > 25
group by type
having type = "Human";
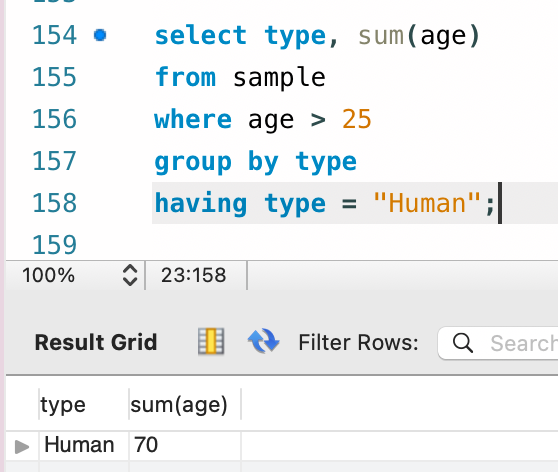
まずはグループ化が行われる前に Where が実行され、Age が 25 以下のものが取り除かれます。
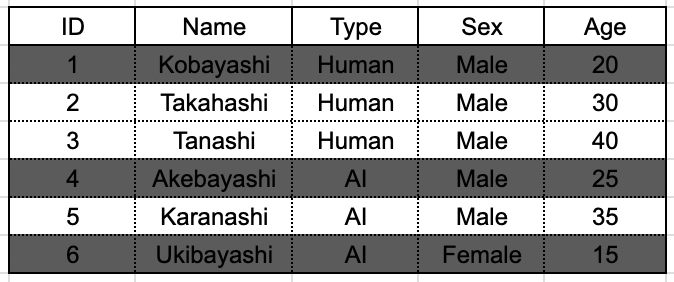
その後、残ったデータで type を軸にしたグループ化が行われます。
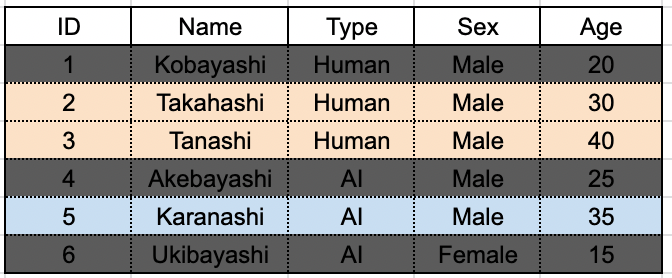
最後にグループに対して Having 句で指定された条件、type = "Human" が適用され、グループが選別されます。
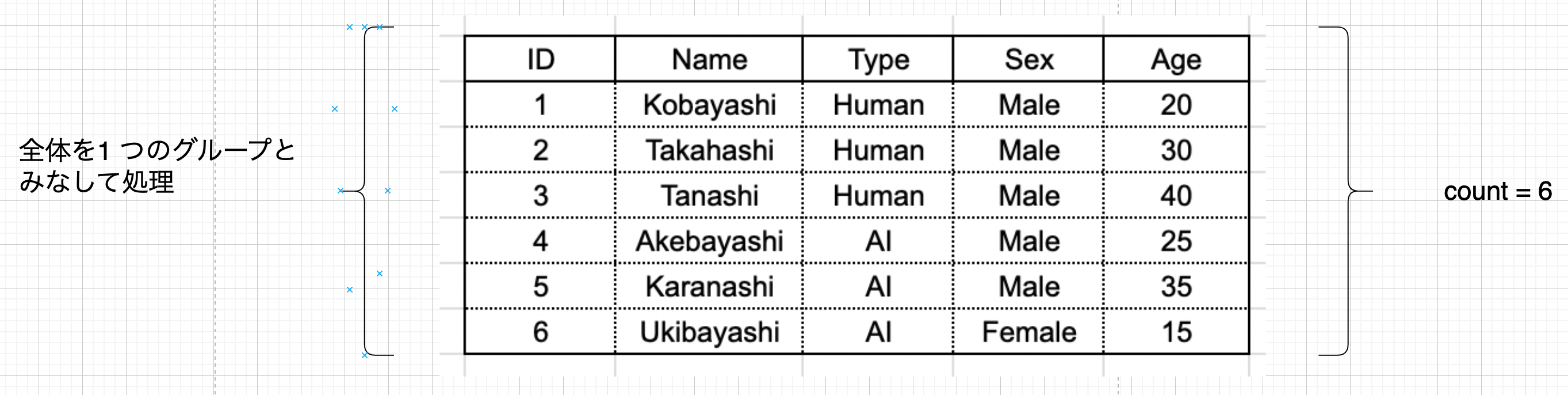
(c) テーブル全体のレコード数を数える ( Group By 句不使用 )
この例では Group By 句を使用せずに集約関数を使用しています。この場合、テーブル全体が 1 つのテーブルとみなされて処理が行われます。
select count(1) from sample;
(d) [応用] 転置して列と行の情報を入れ替える ( Group By )
すごく使いやすいわけではないですが、集約関数を使用して転置を表現することができます。
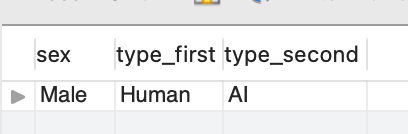
select
sex,
max(case when type = "Human" then type else null end) as type_first,
max(case when type = "AI" then type else null end) as type_second
from sample
group by sex
having sex = "Male";
データの中の Sex (Male)と Type に注目します。このときに「Sex: Male についての Type 情報を 1 行で表現したいなあ」と思ったとします。 つまり縦に並んでいるデータを集約して横に並べ直したい ≒ 転置したい というモチベーションですね。
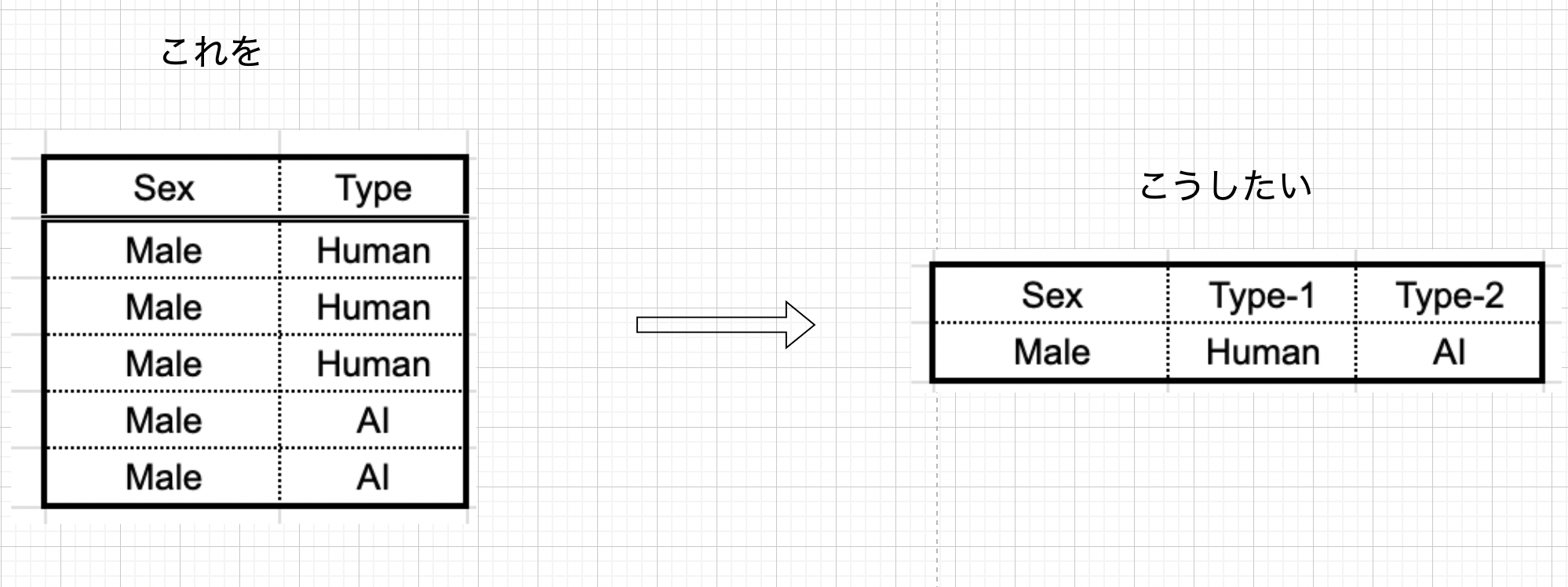
この場合も集約関数で対応することができます。 集約関数は 1 グループに対して 1 つの結果を返すという性質を利用して、各 Type を明示的に指定しながら Case 文を組むと、複数の集約結果を 1 行にまとめられます。

ただしこの使い方では Type のとり得る値全てに Case 文を組む必要があるので、発生する値のバリエーションが把握できていて、かつ数が少ない場合にのみ使える方法と言えます。
(e) [応用] 発生し得る全てのグループに対して集約処理を行う ( Rollup )
それぞれのグループに対しての集約結果を知りたいけれども、そのついでに全体の集約結果も知りたいなあ、なんてことはありませんかね。
そんなときには、Rollup 句を使用した「超集約」という概念が使えます。
select type, sum(age)
from sample
group by type
with rollup;
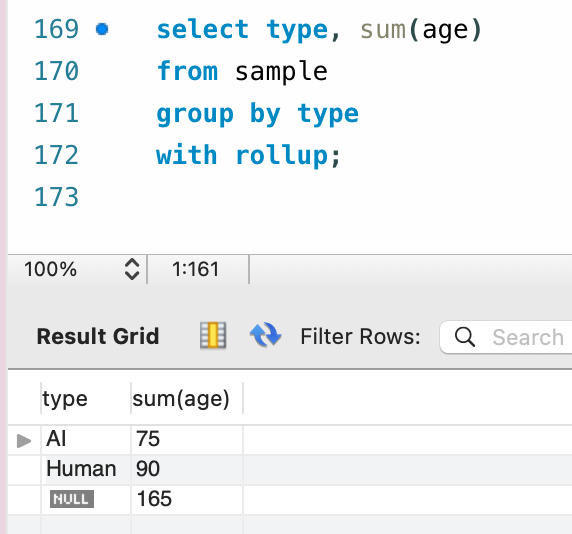
超集約を用いた場合には、各レイヤーにおけるグループ全体に対しても集約処理を行なってくれます。
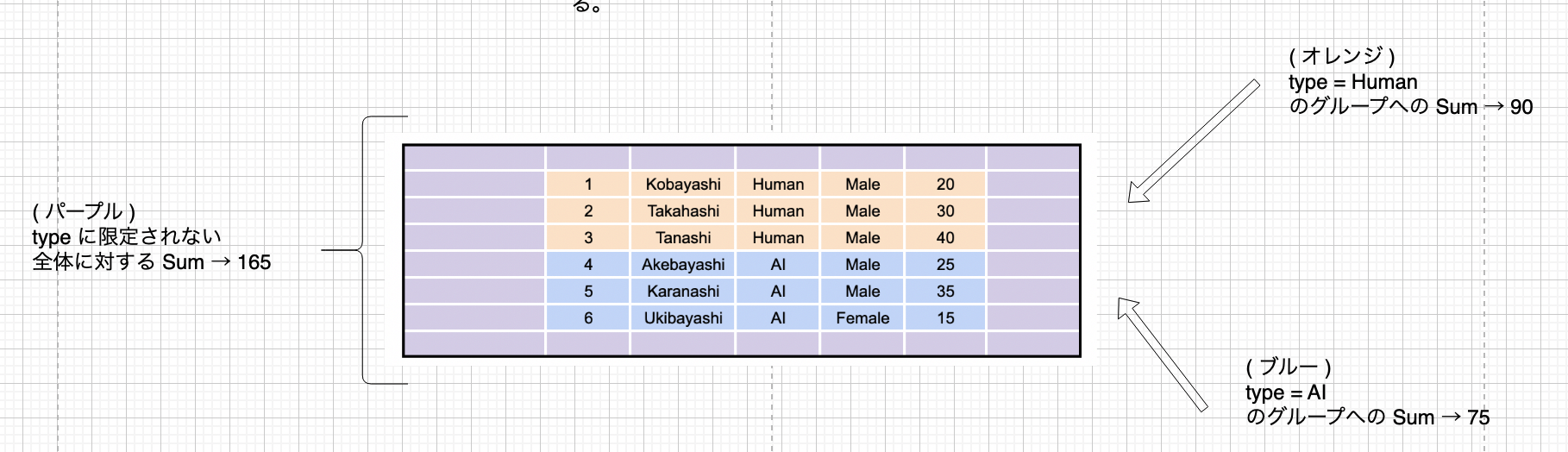
あえて全体ではなくレイヤーと言ったのは、Group By でのグループ条件として複数列を指定した場合には全体だけではなく、個々の指定列に対しても同様に超集約を行なってくれるからです。
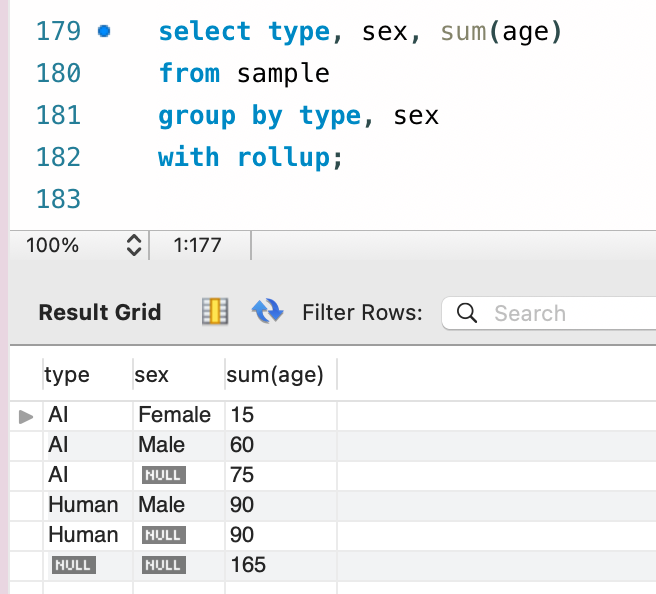
図にするとこんな感じですかね。
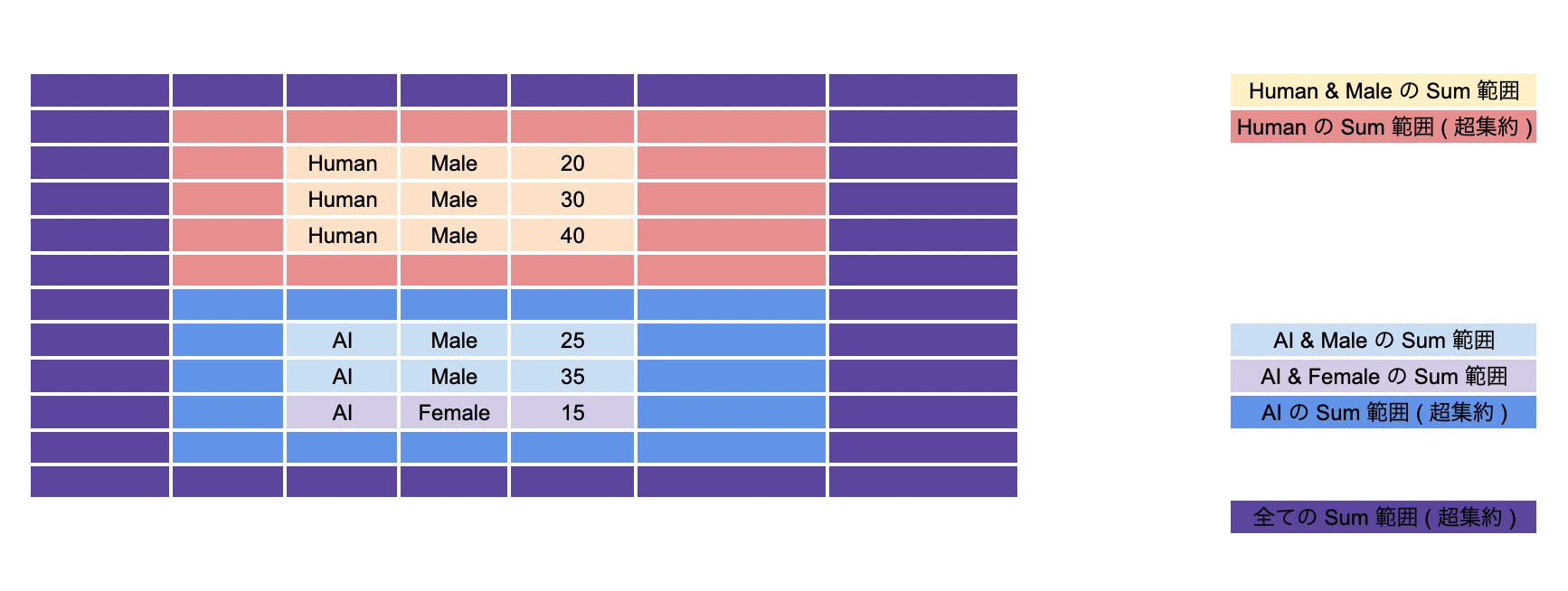
ただ超集約の結果表示が null になっちゃうところ (一応回避策はあります) とか、考え方がちょい難しかったりするので、あまり普段使いはしない気がしますね。
(12) 構文解説: Window 関数 ~ Window 句編 ~
さてラスト、Window 関数の構文解説いきましょう! ややややこしいので、基本の Window 構文とフレーム構文の 2 つに分割して扱います。
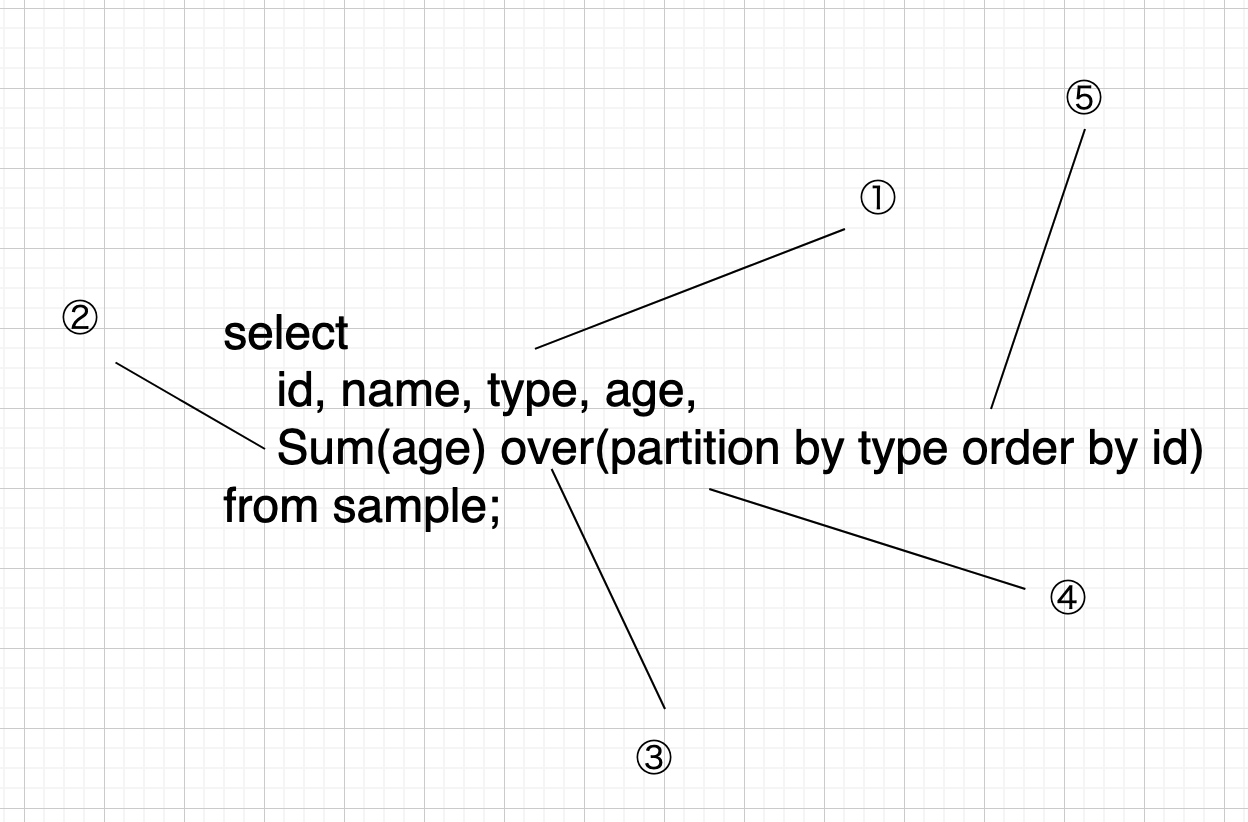
こちらも公式説明を併読してください。
① 通常の Select 部
通常の Select です。Window 関数を使用するときには返却される行数に制限がないので、グループ化された単位を気にせず好きな列を Select できます。
② Window 関数
Window 関数自体です。前回の記事でお話しした通り、一部の関数は集約関数としても Window 関数としても使えます。 どちらとして使われているのかは、次の Over 句があるかないかでわかります。
③ Over 句
Window 関数の使用を宣言するための句です。これ自体は処理に関わる意味を持ちません。
④ Partition By 句
グループ化に用いる列情報の指定を行う句です。Window 関数の場合、Group By 句を用いずにこの句でグループ化に用いる列を決定します。
⑤ Order By 句
グループ化した範囲内での並び替えの指定です。
(13) 使用例解説: Window 関数 ~ Window 句編 ~
さて Window 関数についても使用例とイメージで内容理解を深めていきましょう。使用するサンプルデータは先ほど同じものを使用するので説明を割愛します。
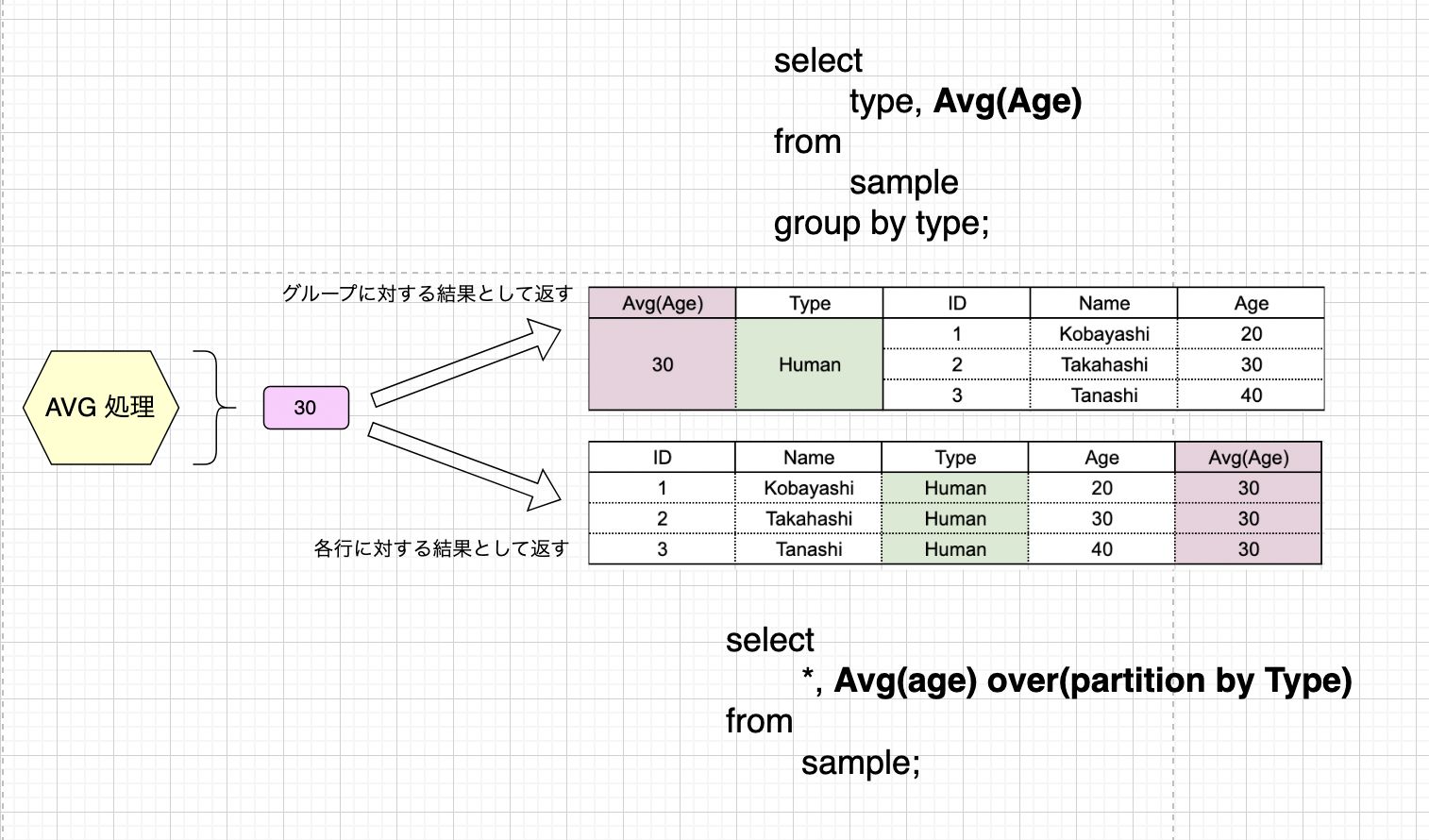
(a) 各レコードに全体あるいはグループ内平均情報を付与する ( over 句のみ / over + partition by )
まずは最もシンプルな書き方からです。over() を単独で使用した場合、テーブル全体を 1 つのグループとして集約処理を行い、結果を各レコードに返します。
select
id, name, type, age,
avg(age) over()
from sample;
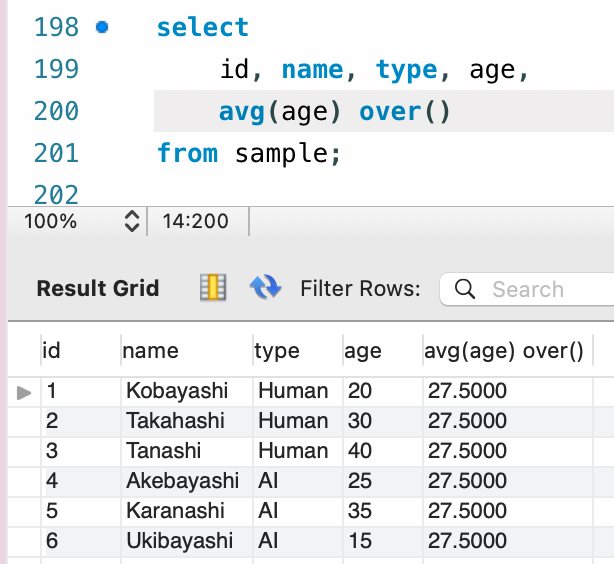
また over() 句の中で partition by 句でグループ化に用いる列情報を指定することで、その単位でのグループ化を行うことができます。
select
id, name, type, age,
sum(age) over(partition by type)
from sample;
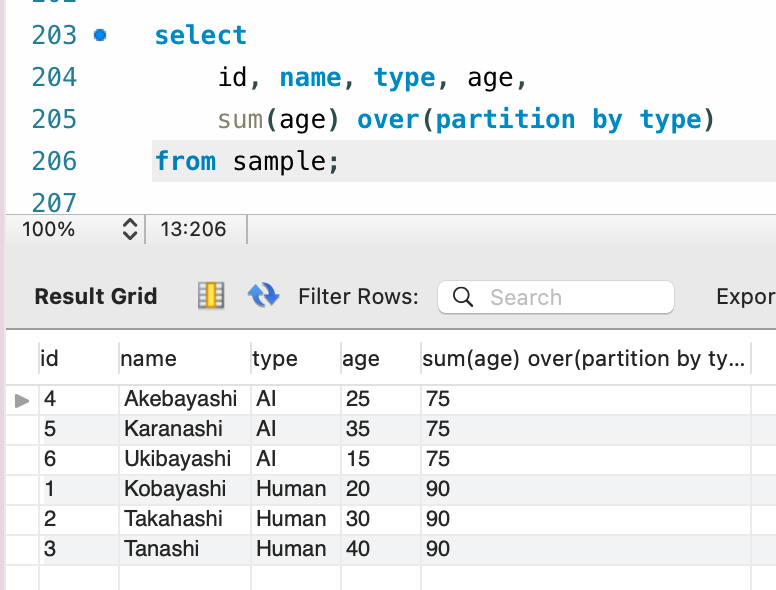
ここは本当に普通の集約処理と考え方が一緒ですね。前者は Group By 句を用いずに集約関数を用いた時の動きに等しく、後者は Group By 句を用いた時のそれと同様です。 再掲ですが集約処理と Window 関数の違いのイメージを載せます。結果が 1 つだけ帰るか複数返るのか、それが 2 つの処理の大きな違いなのでした。
(b) 現在レコードの前レコードの情報を取得する ( over + partition by + order by )
Over() によって作成されたグループ空間では、ストアドプロシージャにおけるカーソルの概念のように「現在参照している行」と言う考え方を持ち込むことができます。 それを使用すると、「現在参照している行の」「1 つ前」とか「1 つ後ろ」とかを参照することができます。
今回は Lag() 関数をみてみます。これは、「現在レコードの 1 つ前のレコードにおける指定行を参照する」と言う機能を持っています。
select
id, name, type, age,
lag(age) over(partition by type order by id)
from sample
order by id;
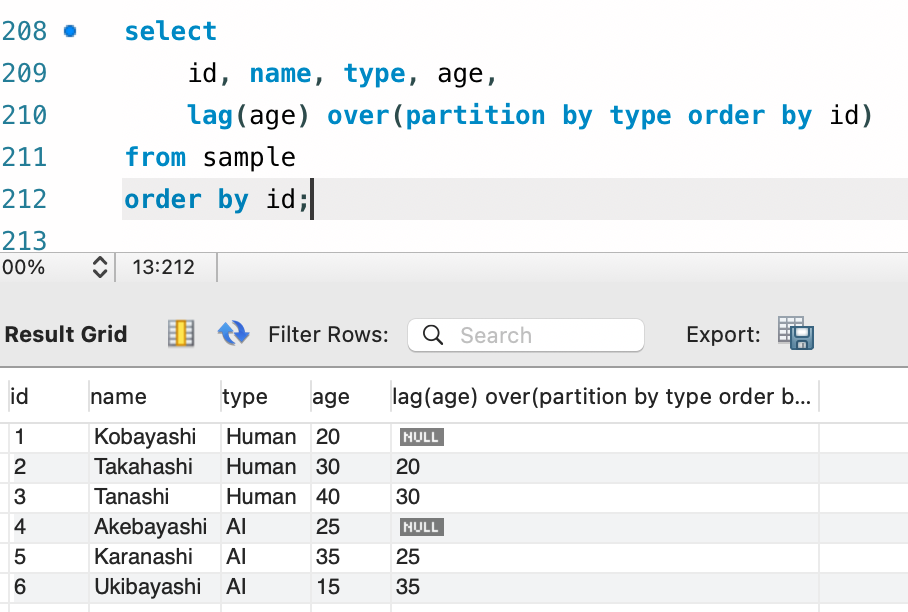
参照すること単体では多分あまり使い道はないと思うのですが、例えば「前レコードとの数値差分を求める」とか「次レコードにおけるタイムスタンプとの時間差を求める」とか、工夫次第でかなり夢の広がる機能ですね。
ちなみに Lag() 関数自体はフレーム空間を形成しているわけではないので、フレームとは呼びません。後述するフレーム句との併用は無効です。
- MySQL: 12.21.3 ウィンドウ機能フレーム仕様
標準 SQL は、パーティション全体で動作するウィンドウ関数に frame 句を含めないことを指定します。 MySQL では、このような関数の frame 句は許可されますが、無視されます。
これらの関数は、フレームが指定されている場合でもパーティション全体を使用します:
CUME_DIST()
DENSE_RANK()
LAG()
LEAD()
NTILE()
PERCENT_RANK()
RANK()
ROW_NUMBER()
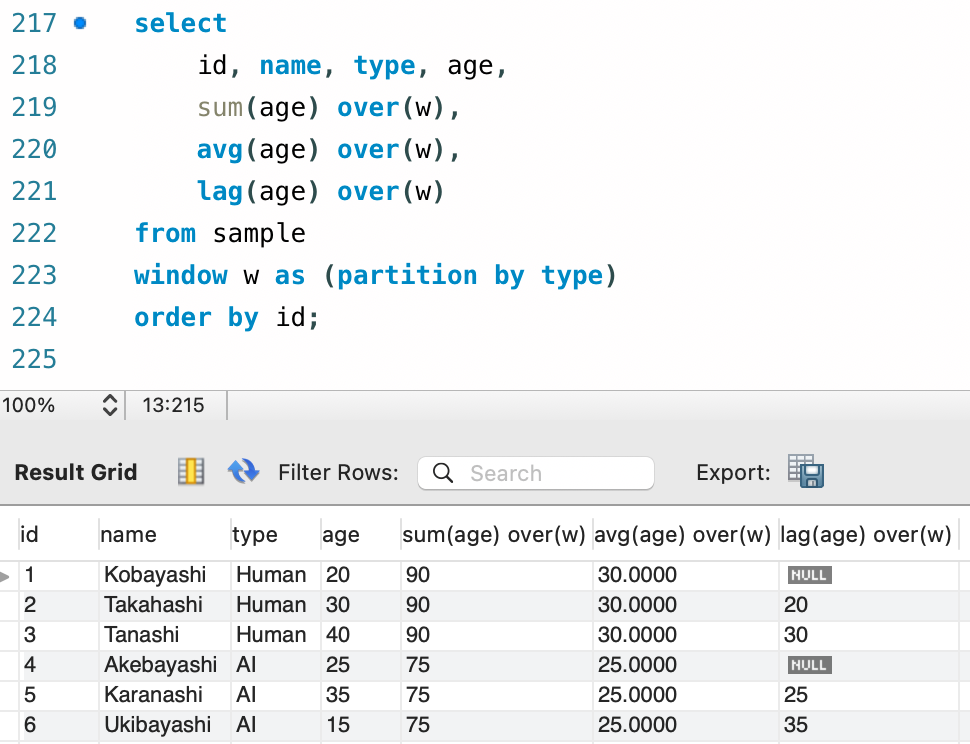
(c) 定義した Window を使い回す ( window 句の明示 )
複数の Window 関数を使用したいとき、毎回 Over(XXX) 句を使うのは面倒です。その場合には、Window 空間を一度だけ定義して毎回それを呼び出すような指定をすることができます。
select
id, name, type, age,
sum(age) over(w),
avg(age) over(w),
lag(age) over(w)
from sample
window w as (partition by type)
order by id;
(14) 構文解説: Window 関数 ~ フレーム句編 ~
さてここまで基本的な Window 関数をみて来ました。 集約関数との大きな違いは結果の返却数でしたが、それ以外にも Lag() など Window 内での自由な動きを表現するための機能がありました。 この記事の最終章として、Window 関数におけるフレーム句を解説しようと思います。フレーム句は Over() 句のオプションの 1 つです。

① フレーム単位の指定
フレームを形成するときの単位を指定します。 Rows を指定するとき行が基準となり、Range を指定した場合は値が基準になります。
② フレーム範囲の指定
フレーム範囲を指定します。前述の単位を元に、「現在行から 3 行先まで」とか、「2 行前の値から 3 行後の値までの範囲」などを表現します。
(15) 使用例解説: Window 関数 ~ フレーム句編 ~
(a) 現在行までの数値の合計を求める
Window 内で「Window 内の最初から現在行まで」と言うフレームを作ることで、現在行までの数値の合計計算などを行えます。
ちなみに今回は partition by を使っていません。テーブル全体をグループとして扱い、その中でフレーム空間を作っているイメージで読んでください。
select
id, name, type, age,
sum(age) over(order by id rows UNBOUNDED PRECEDING)
from sample ;
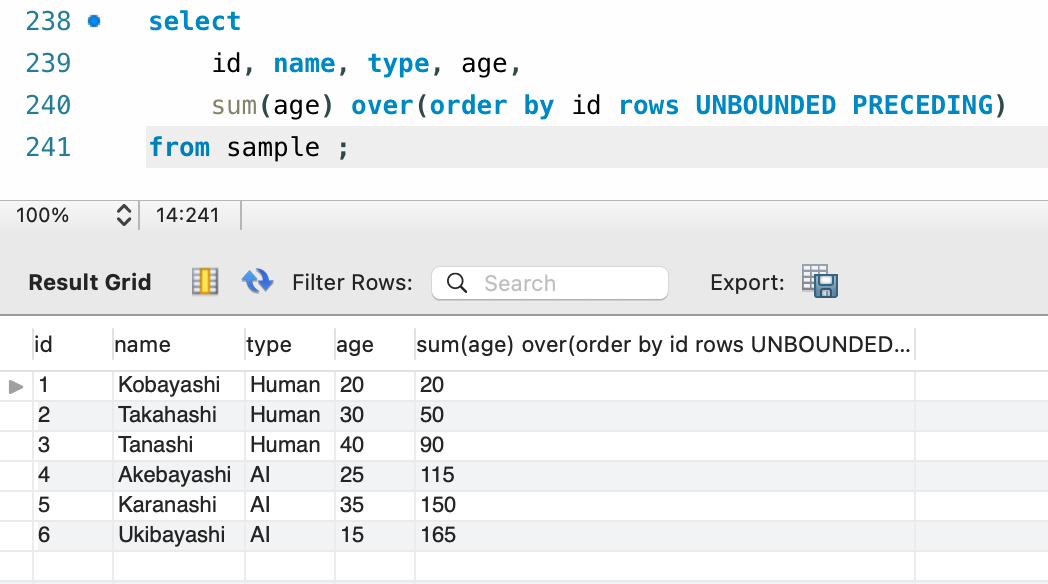
rows の指定で、単位が行であることが明示されました。
また Unbounded Preceding と言う設定で、「パーティション内の最初の行」が指定されています。
これにより暗黙的に「パーティション内の最初の行から現在行まで」と言うフレームが作成され、計算処理が行われています。
前回記事で出したものと被るのですが、ここで処理が進みながら形成されるフレームのイメージはこんな感じですね。

(b) 現在行と 1 行前の行の数値の合計を求める
最初からの合計ではなく、現在行を起点とした隣接行との計算を行うこともできます。
select
id, name, type, age,
sum(age) over(order by id rows between current row and 1 following)
from sample;
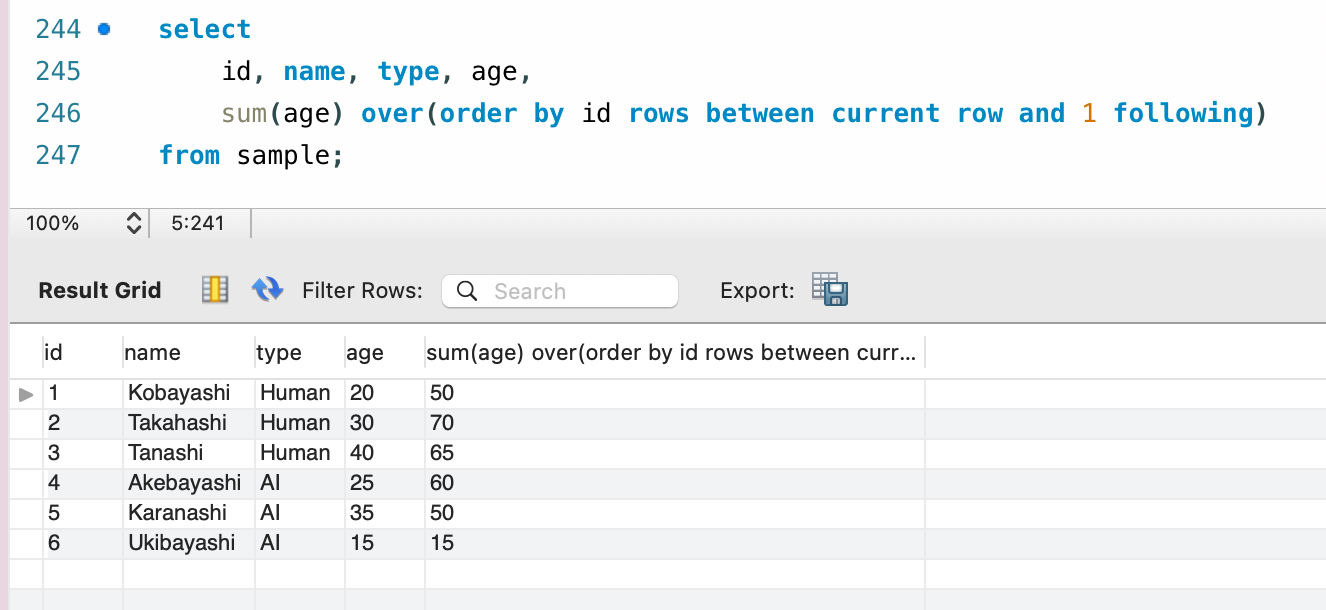
今回は between 句でフレームの範囲を明示的に指定しています。 current row は「現在の行」を、1 following は「起点の 1 つ次の行」を示します。 従って、「現在行から数えて 1 つ先の行までの age 列の合計値を求める」と言う指定になっています。

ちなみに「次の行」や「前の行」が存在しない場合は、スルーされます。
(c) 現在行の 1 行前から現在行の 1 行後までの合計を求める
最後は現在値をフレームの始点や終点にしない方法です。
select
id, name, type, age,
sum(age) over(order by id range between 1 preceding and 1 following)
from sample;
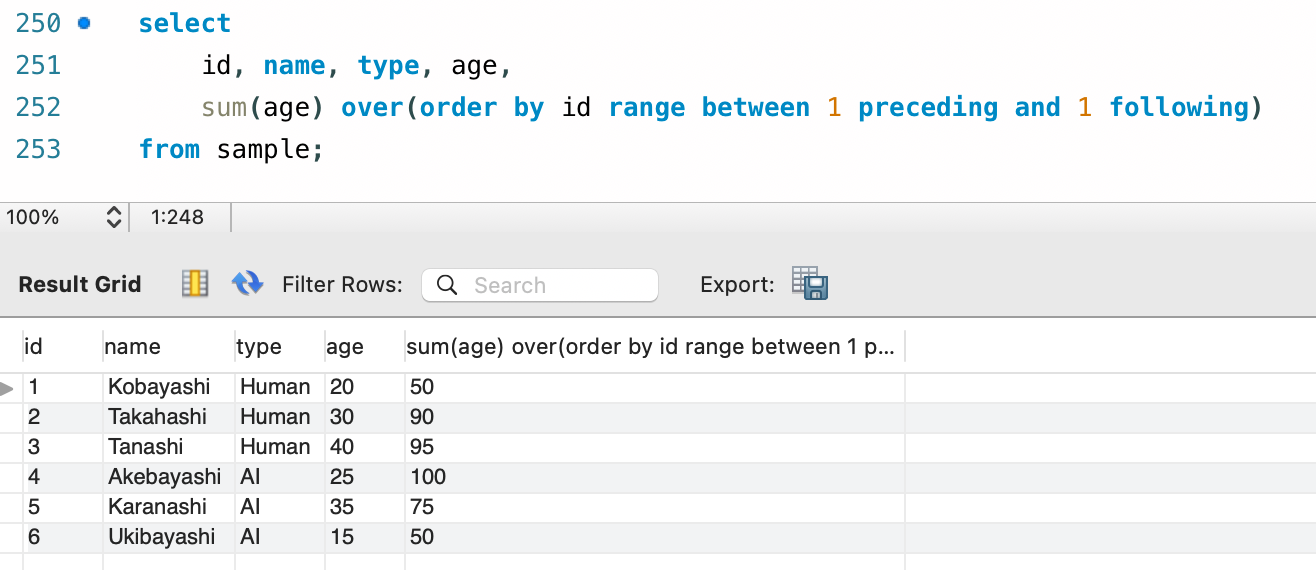 現在値が起点になっているのは変わりないですが、スコープの始点として 1 preceding 、つまり「現在値から 1 つ前の値」、終点として 1 following 、つまり「現在値を含めた前後 1 つずつ、計 3 値」を指定しています。
現在値が起点になっているのは変わりないですが、スコープの始点として 1 preceding 、つまり「現在値から 1 つ前の値」、終点として 1 following 、つまり「現在値を含めた前後 1 つずつ、計 3 値」を指定しています。

(d) [応用] Rows と Range の違い
フレームの形成単位について、先ほどは次のように説明していました。
フレームを形成するときの単位を指定します。 Rows を指定するとき行が基準となり、Range を指定した場合は値が基準になります。
基本的に Rows で事足りるかなと思うのですが、この違いを把握しておかないのは気持ち悪いので学んでおきましょう。
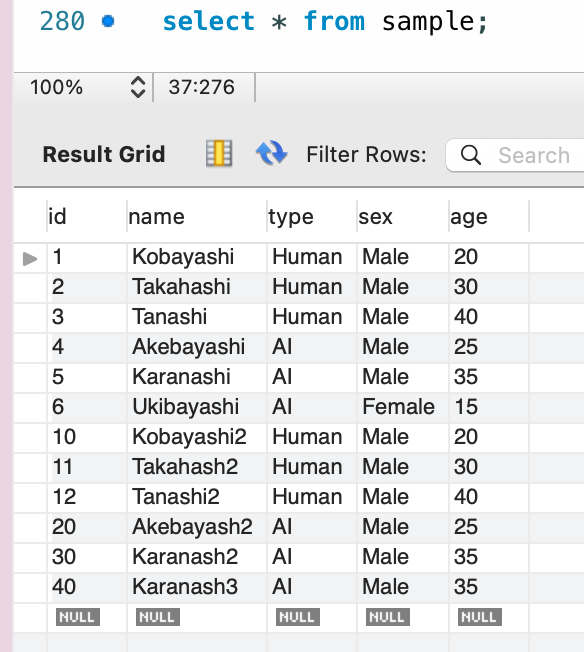
サンプルデータを追加します。
insert into sample values
(10,"Kobayashi2", "Human", "Male", 20),
(11,"Takahash2", "Human", "Male", 30),
(12,"Tanashi2", "Human", "Male", 40),
(20,"Akebayash2", "AI", "Male", 25),
(30,"Karanash2", "AI", "Male", 35),
(40,"Karanash3", "AI", "Male", 35)
;
Rows の場合は「Order by で並んだ順番で、レコード が隣接する場合に処理を行う」という動きになります。
例えば 1 行前と 1 行後の合計を取る処理を Rows で行った場合、以下のようになります。
select
id, name, type, age,
sum(age) over(order by id rows between 1 preceding and 1 following)
from sample
where id >= 10;
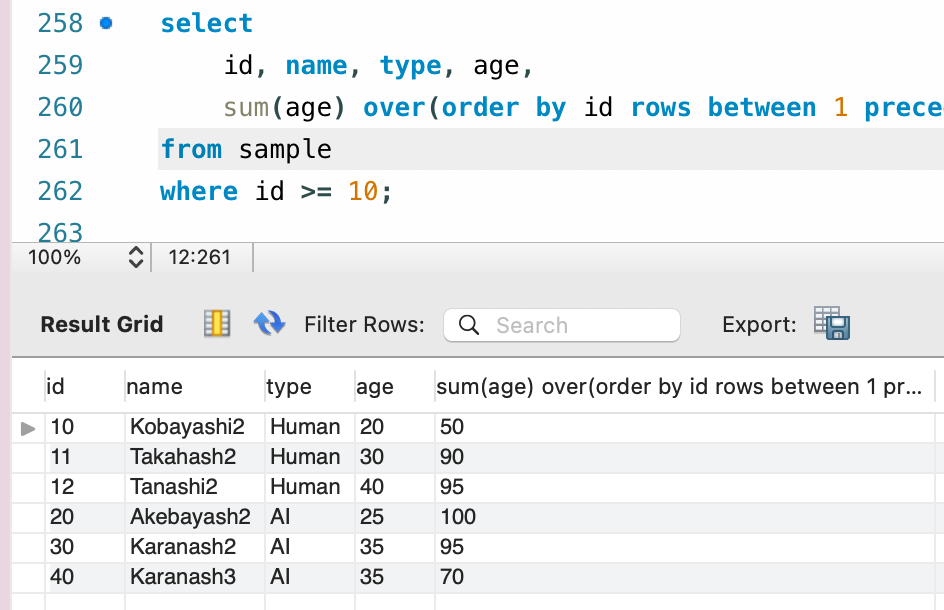
全てのレコードは隣接していると判断されるので、隣接レコードの存在しない先頭と終端以外は、前後を含めた 3 レコードの合計が計算されています。イメージは次の通りです。
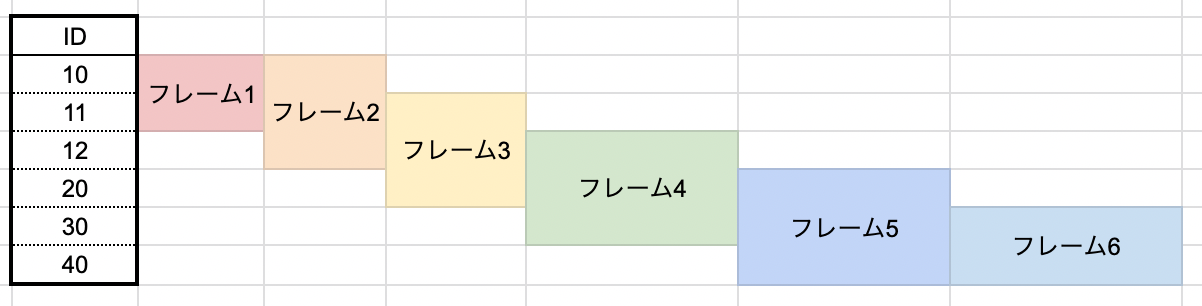
対して Range の場合は「Order by で並んだ順番で、値 が隣接する場合に処理を行う」という動きになります。 先ほどと同じ 1 行前と 1 行後の合計を取る処理を Range で行った場合、以下のようになります。
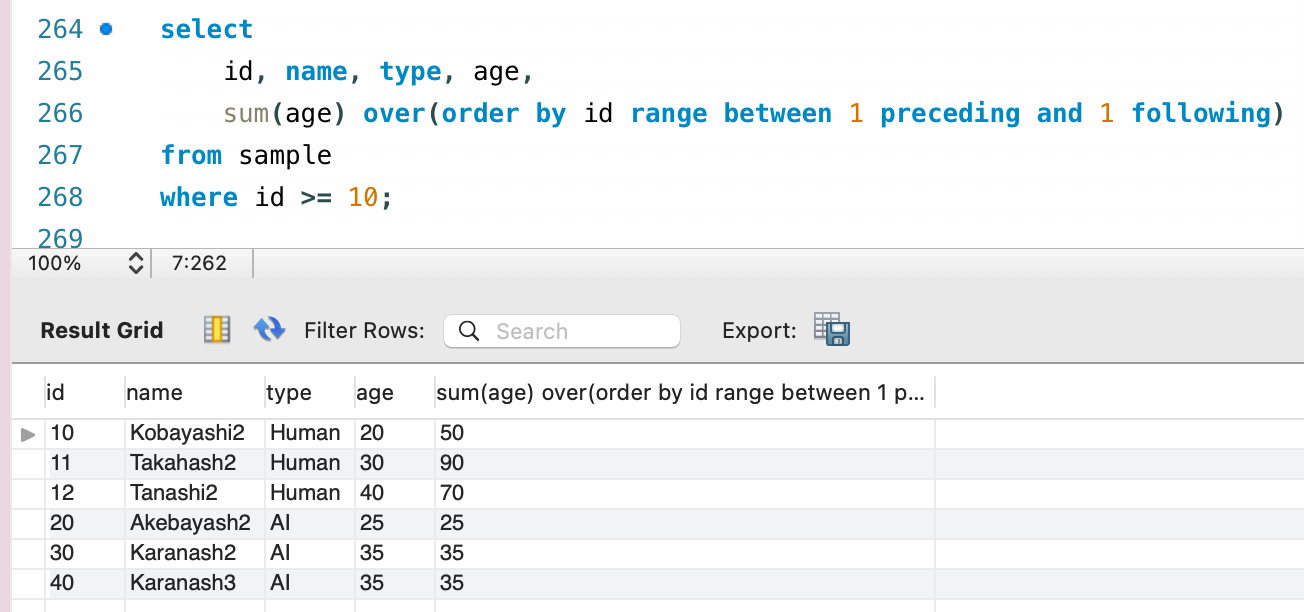
先ほどと結果が変わりましたね。先ほどはレコード同士の比較だったので、先頭と終端以外は隣接レコードが存在すると判定されていました。
しかし Range の場合は値での比較です。今回は基準が ID で数字なので、「隣接する値があれば計算する」という動きになります。
つまり、ID 12 は後ろの値が存在しない、ID 20/30/40 は前後の値が存在しない、と判定されます。

Rows の方が直感的で汎用的な気がしますが、知っておいて損はないですね。
(16) まとめ
長い旅路、お疲れ様でした! 集約関数と Window 関数のイメージ、捉えられたでしょうか?
最後に全体の総復習を行い、今回の冒険を終わりにすることとしましょう。
- グループとは...
- データ中の指定属性で以てまとめられたデータのこと。テーブル全体を 1 つのグループとすることもできる。
- 集約関数は...
- グループ化されたデータに対して処理を行う関数。
- 結果を 1 行で返す。
- Window 関数は...
- グループ化されたデータに対して処理を行う関数。
- 結果を N 行で返す。
- グループ化されたデータについて、さらにその中でフレーム空間を作成して細かい処理を行える。

-
集約関数の構文は...
- AVG() や SUM() などの関数が使用されることで、集約関数が成立する。
- Group By 句でグループ条件が指定されるが、あってもなくても良い。なければテーブル全体が 1 つのグループになる。
- HAVING 句でグループに対する条件絞り込みを行うことができる。
- Where は HAVING よりも先に実行されるので、グループに対する絞り込みにはならない。
-
Window 関数の構文は...
- AVG() や SUM() などの関数 に Over() 句が追記されることで、 Window 関数が成立する。
- Partition By 句でグループ条件が指定されるが、あってもなくても良い。なければテーブル全体が 1 つのグループになる。
- Order By 句で、グループ内の並び替え順序を指定できる。
- rows や range などの構文でフレーム空間を指定することができる。
終わりに
全 3 記事にわたりお付き合い頂き、ありがとうございました !
個人的な印象としては、集約関数はだいぶ基本的な技術ですが Window 関数までを使いこなしている人にはあまり出会ったことがありません。
ゆえにどちらも使いこなせれば、チームから一目置かれること間違いないです。 ぜひこの記事を通して理解を深めて見てください!
弊社 Belong では一緒にサービスを育てる仲間を募集しています。 もし弊社に興味を持っていただけたら エンジニアリングチーム紹介ページ をご覧いただけたら幸いです。
ではサヨウナラ!