Cloud Next '25 にて紹介されていた Cloud Run における可用性の高いマルチリージョンサービスについて
はじめに
こんにちは。株式会社 Belong で SWE をしている nemo です。
前回の記事でも触れた通り、カンファレンス渡航補助プログラムを利用してラスベガスで開催された Cloud Next'25 に現地参加してきた中で気になったセッションを本記事にて紹介いたします。 カンファレンス渡航補助プログラムにつきましては、こちらの記事をご参照ください。
弊社では Cloud Run をサービスインフラの基盤として採用しており、私個人としてもその安定運用には高い関心があります。今回、Cloud Run においてマルチリージョン環境下でも安定的な運用をさらに強化できるというセッション内容に強い興味を持ちました。そのため、Run high-availability multi-region services with Cloud Runというセッションに参加し、どのような新機能が紹介されるのかを確認してきました。
本記事では、当該セッションについてセッション内容と所感をまとめました。
Fault tolerant design について
セッションは、まず Cloud Run の簡潔な説明から始まりました。 Cloud Run とは Google 社が提供する、スケーラブルなインフラストラクチャ上で関数やコンテナを実行するためのフルマネージドプラットフォームです。

高い可用性を持ち、開発者がインフラ管理に費やす時間を削減できるため、広く利用されているサービスです。
Google Cloud チームの Vice President である Ben Treynor 氏の「100% is the wrong reliability target for basically everything」(100%という信頼性は、基本的にあらゆるものにとって誤った目標である)という言葉が引用されていました。これは、100%の信頼性を目指すのではなく、障害発生時にいかに迅速に検知し復旧させるかが重要であるという意味です。

そのため、Cloud Run はフォールトトレランスを重視したデザインになっています。
Commerzbank 社の事例について
ここで Google Cloud を用いた可用性の高いインフラ構築についての事例紹介がありました。 Commerzbank 社は欧州の大手銀行であり、社内で MPS Falcon という検索エンジンサービスを利用しています。 1 日に 70 万以上の検索リクエストがある中で、どのように高可用性を維持しているかについて説明がありました。
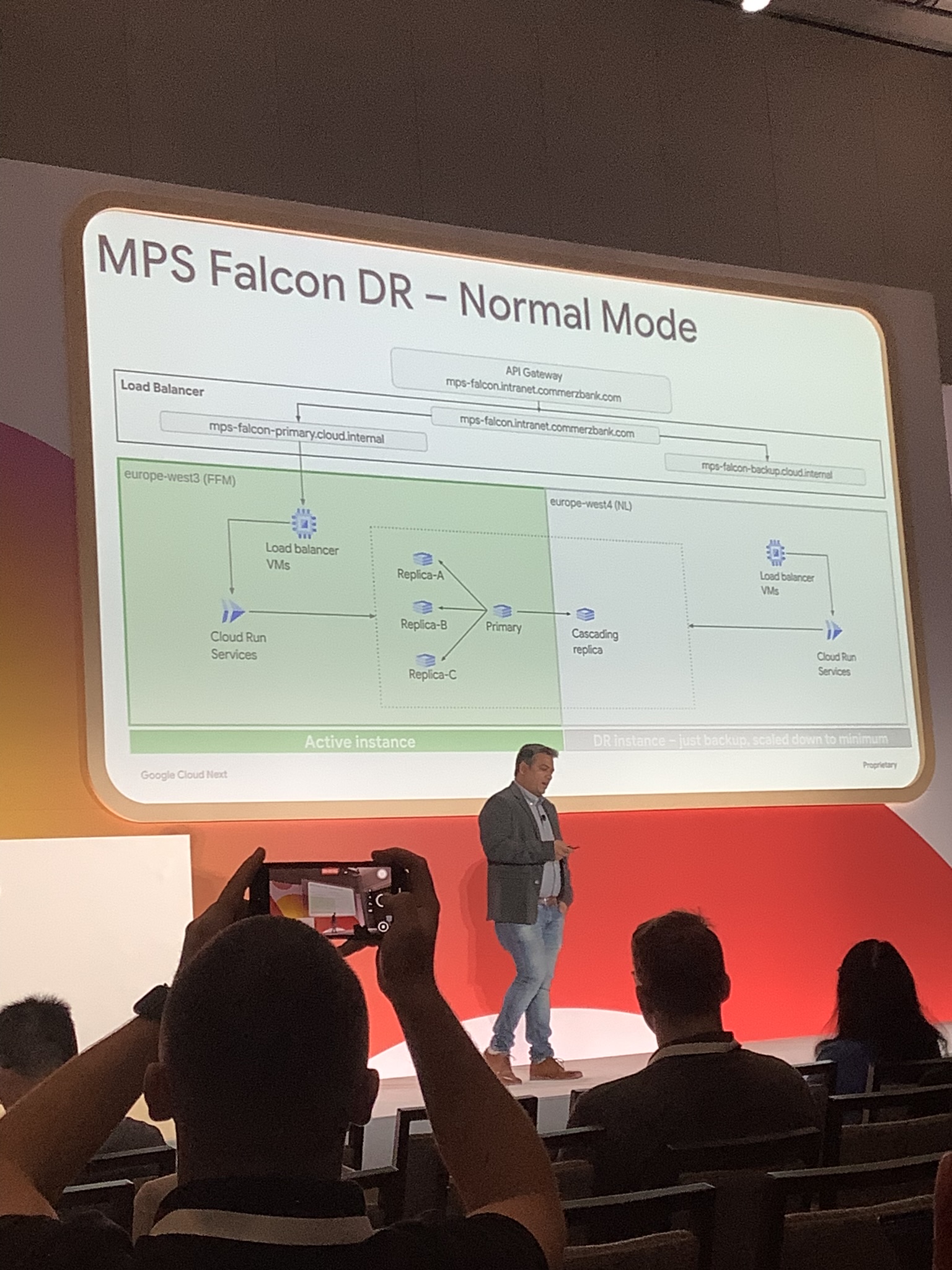 通常運用時では、europe-west3 がアクティブリージョンとして通常のサービスを提供しており、リージョン内においてもロードバランサーや Cloud Run のサービスが稼働しています。
もう一方のリージョン(スタンバイリージョン)では、Cloud Run が DR(Disaster Recover)インスタンスとして待機しており、このリージョンの Cloud Run サービスは最小限にスケールダウンされ、通常時はトラフィックを処理しません。
また、アクティブリージョン内のプライマリデータベースからスタンバイリージョンへ 「Cascading replica」という形でデータが複製されています。
「Cascading replica」とは、DB のデータがプライマリから直接ではなく、間にある別の中継レプリカを経由して多段階に複製される方式です。このリージョン間構成では、アクティブリージョンのプライマリから中継レプリカを経て、スタンバイリージョンの DR 用レプリカにデータが送られ、プライマリの負荷を軽減しています。
通常運用時では、europe-west3 がアクティブリージョンとして通常のサービスを提供しており、リージョン内においてもロードバランサーや Cloud Run のサービスが稼働しています。
もう一方のリージョン(スタンバイリージョン)では、Cloud Run が DR(Disaster Recover)インスタンスとして待機しており、このリージョンの Cloud Run サービスは最小限にスケールダウンされ、通常時はトラフィックを処理しません。
また、アクティブリージョン内のプライマリデータベースからスタンバイリージョンへ 「Cascading replica」という形でデータが複製されています。
「Cascading replica」とは、DB のデータがプライマリから直接ではなく、間にある別の中継レプリカを経由して多段階に複製される方式です。このリージョン間構成では、アクティブリージョンのプライマリから中継レプリカを経て、スタンバイリージョンの DR 用レプリカにデータが送られ、プライマリの負荷を軽減しています。
 障害が起こり、europe-west3 が正常に動作しなくなると、ロードバランサーがアクティブリージョンの障害を検知し、スタンバイリージョンの DR インスタンスが
アクティブリージョンとして機能するようになります。
スケールダウンされていた Cloud Run サービスや関連コンポーネントがスケールアップし、トラフィックの処理を開始します。
障害が起こり、europe-west3 が正常に動作しなくなると、ロードバランサーがアクティブリージョンの障害を検知し、スタンバイリージョンの DR インスタンスが
アクティブリージョンとして機能するようになります。
スケールダウンされていた Cloud Run サービスや関連コンポーネントがスケールアップし、トラフィックの処理を開始します。
上記のような構成により、大規模な障害が発生した場合でも、もう一方のリージョンでサービス提供を継続し、ダウンタイムを最小限に抑えることができると説明がありました このアーキテクチャで興味深い点は、ロードバランサーから Cloud Run、データベースに至るまでの一連のサービス群を、一つの大きな「インスタンス」のように捉え、リージョン単位で冗長化することで可用性を向上させている点です。 一般的なアーキテクチャでは、アクセスが集中した際に API サーバーのインスタンス数を増やすといった対応が主ですが、Commerzbank 社の事例のようにリージョン全体を一つの単位として冗長化する構成は、より堅牢で安全な運用に繋がると感じました。
新機能 Deploy services with across multiple region について
この後、今後の Cloud Run の新機能についての紹介がありました。 当該機能については、本セッションが初出の情報でなくしばらくプレビュー版の機能ではありますが、近い将来、stable 版として Cloud Run ではマルチリージョンにおけるサービスのデプロイが可能になるかと思います。
gcloud beta run deploy example --regions=us-west4,asia-east1

現在、弊社ではこちらの記事でも紹介させていただいた通り、アメリカにおいて事業を開始したこともあり 日本で利用されている在庫管理システムも将来的に、US リージョンに展開する可能性もあります。そういった場合にこの機能を使うことで簡単にデプロイできることは便利になると感じました。
新機能 Service Health 機能について
Service Health 機能は、現在開発中の機能であり、Cloud Run サービスの健全性を監視し、障害発生時の自動復旧を高速化することを目的としています。 特にマルチリージョン構成において、より高い可用性を実現することを目指しています。 その仕組みは、Container Readiness という機能に基づいています。これは、Cloud Run で稼働している個々のインスタンスが正常にリクエストを受け付けているかを判断するためのエンドポイントを設けるものです。Cloud Run がこのエンドポイントを定期的にチェックし、応答がない場合やエラーが返ってくるコンテナを「不健康(Unhealthy)」と判断します。この Container Readiness については設定が 下記のように Readiness Probe に追加されると考えています。

Readiness Probe の設定内に新たな項目が追加され、チェック間隔、タイムアウト、失敗と判断するまでの試行回数等も Cloud Run のサービス設定で変更できるとのことです。

この機能の追加により MTTR(平均修復時間)の改善も期待できると言及されていました。 複数のリージョンに Cloud Run サービスをデプロイし、ロードバランサーと Container Readiness を組み合わせることで、リージョンレベルの障害からの MTTR を短縮できると想定されています。
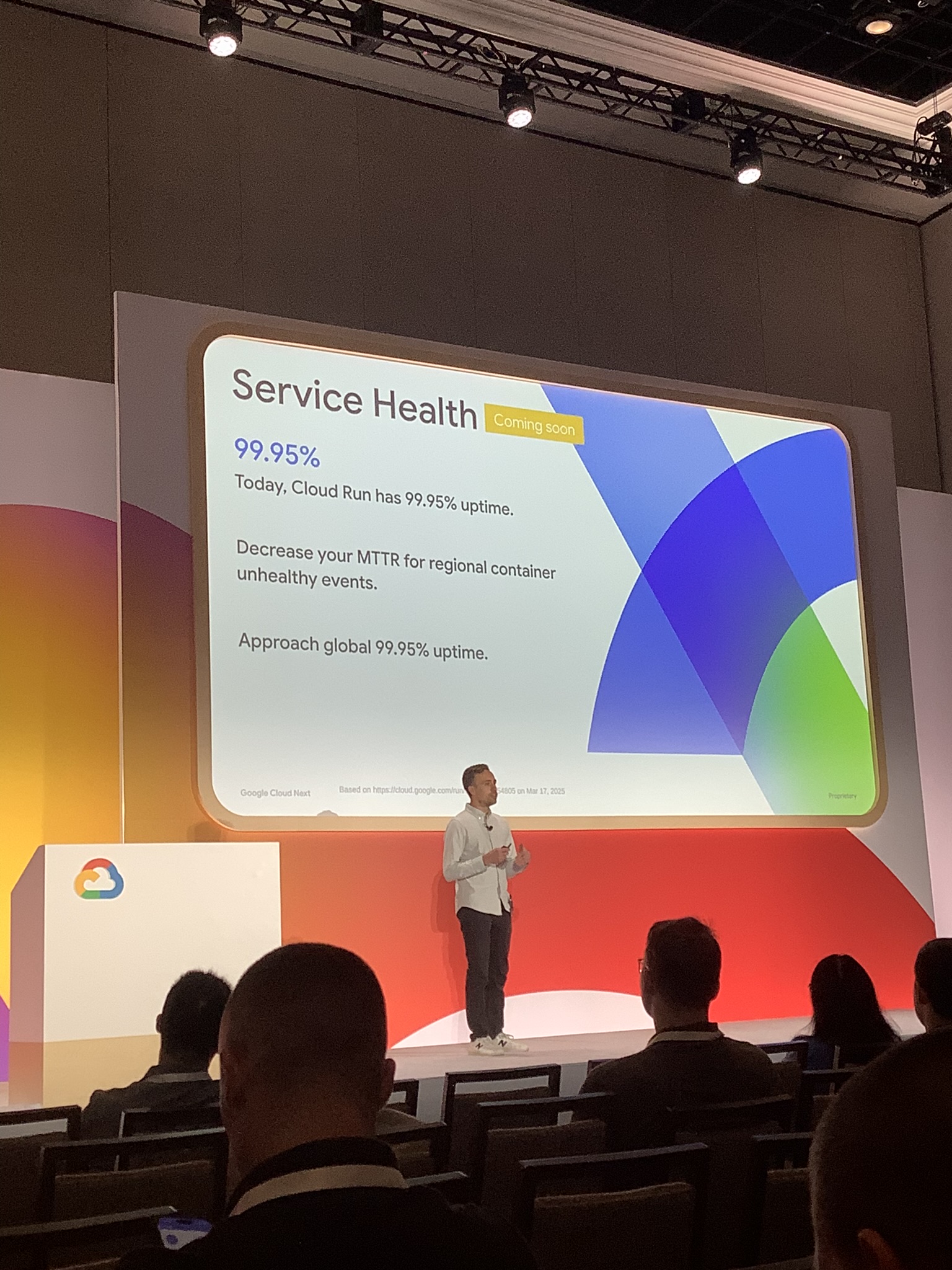
この機能によって、Cloud Run が現在リージョン単位で提供している 99.95%の月間稼働率を、グローバルなマルチリージョン構成全体で見ても達成することを目指しているとのことでした。
デモでは、実際に us-west4 と asia-east1 のマルチリージョンにデプロイされたサービスにおいて、us-west4 のほうが「Unhealthy」になった際に自動的にロードバランサーが asia-east1 に切り替わる様子を実演していました。
-
us-west4 が「healthy」で正常稼働している

-
us-west4 が停止して「Unhealthy」になる

-
asia-east1 に切り替わる

所感: Belong での適用可能性について
前述の通り、弊社はアメリカ国内での事業も拡大する予定のため日本国内で利用しているサービスが今後国外でも利用されることが予想されます。
その際にマルチリージョンでのデプロイを 1 コマンドで実行可能になる点は、開発者にとって魅力的です。
現在は CI/CD パイプラインでデプロイを行っていますが、既存のデプロイコマンドに --regions オプションを追加するだけで、マルチリージョンデプロイに対応できるのではないかと期待しています
また、マルチリージョンにおける Service Health 機能もサービスの信頼性に寄与してくれるものと期待しています。
気になる点としては、マルチリージョン構成が安定版としてリリースされた際に、自社のサービスにとってどのような構成が最適か、考慮すべき点が多いだろうという点です。
例えば、データベースサーバーをシングルリージョンに配置する構成は、システムの複雑性を抑える上では一案ですが、そのデータベースサーバー自体が単一障害点(SPOF)となってしまう懸念があります。
Commerzbank 社の事例のように、可用性を最大限に高めるためにはデータベースサーバーも複数リージョンに展開することが望ましいですが、その場合、データ同期の頻度や方法によってコストが大きく変動する可能性があり、設計時に考慮すべき点が多いという印象を受けました。
おわりに
本記事では、Google Cloud Next '25 の中のセッション Run high-availability multi-region services with Cloud Runについてまとめさせていただきました。
Cloud Run におけるマルチリージョンデプロイメントは現時点ではプレビュー版ですが、今回の発表からは、Google 社が企業のグローバル展開を支援する機能を強化していく姿勢がうかがえました。
今後も Cloud Run の国際化対応に関連する機能追加が進むことを期待させてくれる、興味深いセッションでした。
最後に Belong では、共に働くエンジニアを募集しています。
新しい技術に興味がある方、グローバルな環境に興味がある方は以下リンクもご参考いただければ幸いです。
Entrance Book